Introduction
矩阵分解的方法在推荐算法中是目前效果比较好的,本篇论文用深度学习的方法去做矩阵分解,因为矩阵分解是线性的分解关系,引入激活函数做多层计算后可以有非线性的特性,分解后的矩阵可能拟合程度更好。
本篇论文主要有以下几点:
- 提出了一种基于深度学习的矩阵分解方法,不仅使用了明确打分信息(explicit ratings),还用到了一些没有明确信息的反馈(non-preference implicit feedback);
- 重新设计了损失函数,同时考虑了已打分和未打分的信息;
- 在top-N推荐问题中,该算法表现优异
Problem Statement
\(M\) 个用户\(U=\{u_1,...,u_m\}\) 和\(N\) 个物品\(V=\{v_1,...,v_n\}\) ,打分矩阵\(R\in \mathbb{R}^{M\times N}\) ,将\(unk\) 记为未知,有两种方式来构造交互矩阵\(Y\in\mathbb{R}^{M\times N}\) ,即 \[ Y_{ij}= \begin{cases} 0, & \text {if $R_{ij}=unk$} \\ 1, & \text{if otherwise} \end{cases} \]
\[ Y_{ij}= \begin{cases} 0, & \text {if $R_{ij}=unk$} \\ R_{ij}, & \text{if otherwise} \end{cases} \]
本文采用第二种方式,明确的打分对于推荐非常重要,而没有打分记录的项用\(0\) 补全,作为未知打分信息(non-preference implicit feedback)。推荐问题可以泛化为 \[ \hat{Y}_{ij}=F(u_i,v_j|\theta) \] 潜因子模型可以记为 \[ \hat{Y}_{ij}=F^{LFM}(u_i,v_j|\theta)=p_i^Tq_j \] 在模型中我们做一下标记,\(Y\) 表示用户和物品的交互矩阵,\(Y^{+}\) 表示观测到的交互信息,\(Y^{-}\) 表示位置信息元素,\(Y^{-}_{sampled}\) 表示负实例的集合。
Our Proposed Model
模型结构如图所示
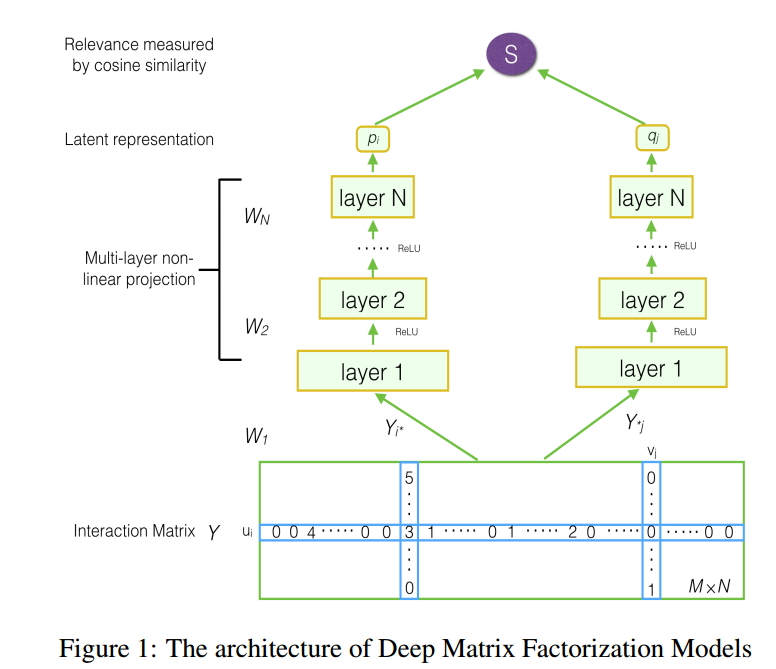
很容易看,在交互矩阵\(Y\) 的一行和一列分别取出后,经过多层神经网络后,最后产出分别产出一个隐向量,做乘积归一化后得到最后的评分,也就是做余弦相似度 \[ \hat{Y}_{ij}=F^{DFM}(u_i,v_j|\theta)=cosine(p_i,q_j)=\frac{p_i^Tq_j}{||p_i||||q_j|} \] 其中\(DMF\) 就是作者所提出的Deep Matrix Factorization。目标函数定义为 \[ L=\sum_{y\in Y^+ \cup Y^-} l(y,\hat{y})+\lambda\Omega(\theta) \] 为了简化,作者采用point-wise的目标函数,pair-wise留作以后做,通常的做法是采用平方损失作为损失函数 \[ L_{sqr}=\sum_{(i,j)\in Y^+ \cup Y^-} w_{ij}(Y_{ij}-\hat{Y}_{ij})^2 \] 其中\(w_{ij}\) 是样本的权重,但这样的权重无法利用non-preference implicit feedback的信息,所以作者根据交叉熵做了一种新的损失函数 \[ L=-\sum_{y\in Y^+ \cup Y^-} (\frac{Y_{ij}}{\max(R)}\log\hat{Y}_{ij}+ (1-\frac{Y_{ij}}{\max(R)}\log(1-\hat{Y}_{ij})) \]
Summary
感觉挺水的一篇文章...说优点,跟另一篇我之前看过的文章思路极其相似,谁前谁后也说,排除这点,这篇文章的亮点可能就是在于对于损失函数的设计吧。