写在最前面,
本来是想简单摘抄一下这篇文章中的精华,写到一半觉得这篇文章不应如此,本文应该是一篇可以比肩Wide&Deep的文章。如果说Wide&Deep告诉业界推荐就是要搞Embedding,E2E,那么本文可能就是告诉大家CTR模型就是要搞Online Learning,搞ODL,以及围绕这些技术Google广告团队他们都在思考什么样问题。
N年前写本科毕设时,我有幸选中了Wide&Deep那篇文章并一字一句翻译了一遍,受益匪浅,今日这篇文章也希望可以一字一句翻译,好好消化。
题外话1,说点负面的,由于业务规模和大环境的限制,国内可能只有很少团队能够跟进这个方向,大部分算法团队优化迭代模型及相关系统所带来的收益,目前来看,很难覆盖其成本。未来数据作为核心资产,真正能赚钱的算法团队可能会逐步变成打磨“模型”资产的团队,而训练的“模型”可能会慢慢变成类似服务器这样的公司资产。
题外话1.1,如果用“数据”资产所获得的“模型”资产变得越发通用(Google的Pathways),那么服务器能卖,模型能不能卖呢?
题外话2,其实这两年国内很多团队都有对未来算法模型发展方向的探索,比如阿里的端智能(快手最近CIKM Best Paper,其实是同一拨人搞得)、全链路算力动态分配等等,目前来看只能说百花齐放吧,最终哪个方向能走得更远,还有待时间去检验。
TL;RD,
本文是Google广告团队在CTR模型优化迭代上的上一些最佳实践,包含准确率提升的tricks、效果提升和模型规模的trade-off、可复现性提升以及对多种bias的处理。
摘要
For industrial-scale advertising systems, prediction of ad click- through rate (CTR) is a central problem. Ad clicks constitute a significant class of user engagements and are often used as the primary signal for the usefulness of ads to users. Additionally, in cost-per-click advertising systems where advertisers are charged per click, click rate expectations feed directly into value estimation. Accordingly, CTR model development is a significant investment for most Internet advertising companies. Engineering for such prob- lems requires many machine learning (ML) techniques suited to online learning that go well beyond traditional accuracy improve- ments, especially concerning efficiency, reproducibility, calibration, credit attribution. We present a case study of practical techniques deployed in Google’s search ads CTR model. This paper provides an industry case study highlighting important areas of current ML research and illustrating how impactful new ML methods are evaluated and made useful in a large-scale industrial setting.
对于工业级的广告系统,广告点击率(CTR)的预估是一个核心问题。点击作为用户参与行为的重要类别,经常被作为广告对用户产生作用的主要信号。此外,在按点击付费的广告系统中,点击率的期望直接影响价值的估计。因此,对于大部分互联网广告公司,CTR模型的开发是一项重大的投资。
为了解决这类问题,需要许多适合在线学习的机器学习技术,不同于用于提升传统机器学习模型准确率的技巧,其更关注于效率、可重复性、校准和结果归因(credit attribution,简单翻译为结果归因可能不太准确,后文会详细解释)。
本文展示了一个部署在谷歌搜索广告的CTR模型中,用到的实用技术的案例研究,该工业级的案例研究,强调了机器学习研究的重要性,展现了新的机器学习方法在工业环境中是如何评估并产生巨大影响的。
Introduction
点击率预估是在线广告系统的重要组成部分,直接影响着公司收入,并且也是近些年热门研究的领域。本篇介绍了一个详细的案例研究,为读者提供了实际工业环境下CTR预测系统的方方面面,描述了大规模工业界的ML系统所面临的挑战,并且强调了一些在实践中证明非常有效的技术。
CTR预估模型包含数十亿的权重,通过百亿的样本训练得到,需要满足数十万QPS的性能要求。本文所描述的技术是为了在准确度提升和训练推断成本增加之间进行平衡。
CTR for Search Ads Recommendations
推荐是指从候选物品集合中,根据给定的上下文信息,给出单个或多个结果。上下文信息会包含用户的属性信息、之前浏览过的视频、搜索词或者其他信息。搜索广告更侧重于匹配搜索查询\(q\)和广告\(a\)的过程。CTR模型会预估概率\(\mathbb{P}(\text{click}|x)\),其中输入\(x\)是广告和查询对\(<a,q>\),也会包含影响点击率的其他因素,特别是用户交互界面相关的因素,如广告在结果页上如何被展示。
除了展示有用的候选结果,广告的推荐系统会有校准的需求。实际点击的样本是随机的,对于给定的广告和查询\(x_i\)和二元的标签\(y_i\),我们希望在样本集合\(D\)上,达到\(\mathbb{P}(\text{click}|x_i):=\mathbb{E}_{<x_i,y_i>\sim D}[y_i=\text{click}|x_i]\)。虽然经典的log-likelihood目标函数可以达到零聚合校准偏差,但对于每个样本而言,偏差往往是存在的。
广告定价和分配问题会需要对每个样本进行校准。通常情况下,预测值和商家出价在竞价机制中,共同决定了广告的价格。竞价机制会依赖于潜在结果的相对价值,这就需要所有候选\(x\)的预测值都是被良好校准的。除此之外,与普通推荐不同的,广告系统经常需要选择不展示广告,这就需要预估单个广告相比无广告的价值,而不单单是最大化广告相关性。
Model and Training Overview
如何对广告和查询\(x\)进行表示是非常重要的选择。查询和广告标题的语义信息是最重要的组成部分,目前大部分研究中,都是通过Attention层产出原始文本信息的embedding,但是我们发现使用变种的全联接网络和最简单特征,如bi-grams或n-grams的统计,就可以得到更好的准确率和效率的平衡。用户查询和广告标题天然文本长度偏低是主要原因,数据高度稀疏,每个样本只有很少的部分特征是非0的。
所有的特征都被当成类别特征,映射到一个稀疏的embedding表,给定输入\(x\),我们将所有特征的embedding拼在一起得到embedding向量\(e\),作为深度模型的输入。用\(E\)表示一个mini batch内所有embedding的值。
接下来我们介绍简化后的模型结构,在之后章节中,我们会介绍为了提升准确度、效率和可复现性,对网络结构的改进优化。我们将\(E\)输入进隐藏层\(H_1=\sigma(EW_1)\),\(W_1\)会对\(E\)进行线性变化,再进行非线性激活\(\sigma\)。隐藏层\(H_i=\sigma(H_{i-1}W_i)\)会层连起来,最后第\(k\)层的输出会被喂入输出层\(\hat{y}=\text{sigmoid}(H_kW_{k+1})\),产出模型的预测值\(\hat{y}\)。模型权重会通过\(\min_W\sum_i\cal{L}(y_i,\hat{y}_i)\)进行优化。ReLUs是激活函数很好的选择。模型通过结合标签\(y\)和预测值\(\hat{y}\)的logistic loss进行监督学习训练得到。训练过程在TPU上采用异步mini batch的SGD:对于每次训练\(t\),计算当前批次样本Loss的梯度\(G_t\),通过一个自适应的优化器更新权重。AdaGrad对于embedding和稠密的网络权重表现很好。
Online Optimization
在广告优化中,对于非稳定的数据,我们发现在线优化方法效果最好。模型对实时到达的样本进行预测,并将其用于训练,而预测值会被用于模型评估。这种方式有很多优势,因为所有的指标可以在样本训练前计算,所以我们可以拥有最实时的评估,同时由于并不用保留验证集,所以可以利用所有数据进行训练。
ML Efficiency
CTR预测系统会对给用户展现的所有广告进行预测,需要满足近10w的QPS的性能需求。任何计算量的增加都会带来额外的部署成本,同时预测的耗时对于实时CTR预估也十分严格。当我们评估模型的改进时,我们需要小心地权衡这些改进优化所带来的推断成本增加。
模型的训练成本也是需要着重考虑的,对于固定的计算预算,衡量训练成本的指标一般是带宽(可以同时训练的模型数)、耗时(端到端评估一个新模型需要的时间)和吞吐量(单位时间内训练的模型数)。
推断预测成本和训练成本可能存在部分差异,一些机器学习的技术可以用来做一些权衡。模型蒸馏(Distillation)对于控制推断预测成本或者“分期偿还”训练成本(原文为amortizing training costs)非常有用。
高效管理模型训练的计算资源,是通过最大化模型吞吐量,保证最小带宽和最大训练耗时来实现的。我们发现所需要的带宽经常受研究人员的数量所限制。对于一个重要的广告模型,往往有数十位工程师在做不同方向的优化尝试。训练耗时则与研究人员的偏好有关,从数小时到数天不等。并行度会控制耗时,在许多系统中,耗时的降低往往是以牺牲吞吐量为代价的。
对于任何机器学习模型的优化,必须权衡眼前的收益和未来研发的长期成本。比如,盲目扩大一个大型DNN模型可能会有短期的收益,但会给未来的训练增加令人望而却步的成本。
在诸多文献中,有很多技术和模型结构都会有一定的准确度提升,但是却很难说这些提升是值得的(比如过多模型的集成学习,或是随机变分贝叶斯推断等等),同时也有一些准确度提升的机器学习技术注重效率提升,可以通过调整模型的参数来降低训练成本。因此我们评估一项技术时,通常关注两点:
- 当训练成本不增加时,准确度的提升是什么
- 如果模型的容量更小,当准确度持平的时候,训练成本的降低是多少
在我们的业务场景中,一部分技术善于降低训练成本,另一部分则适用于提升准确度。
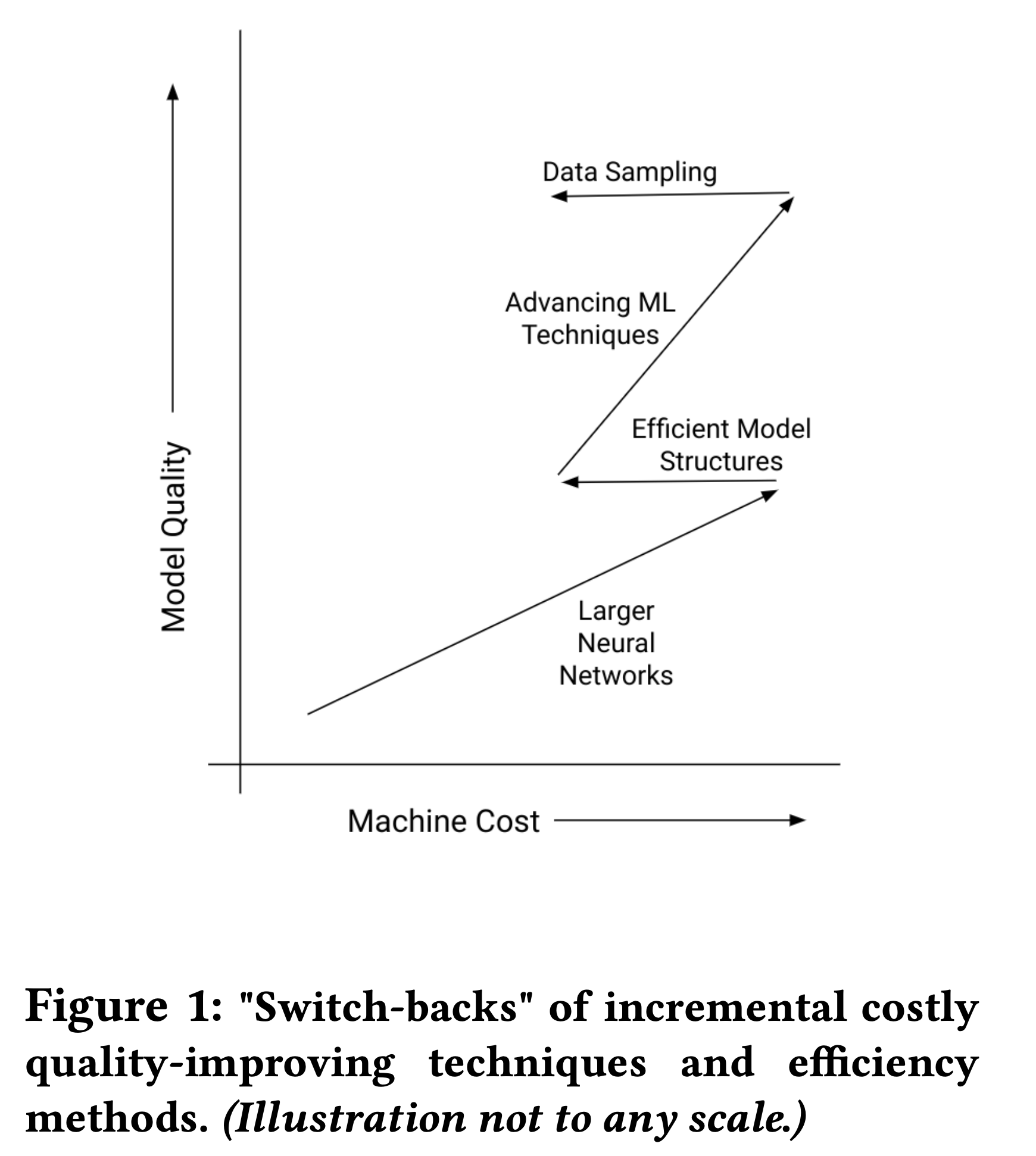
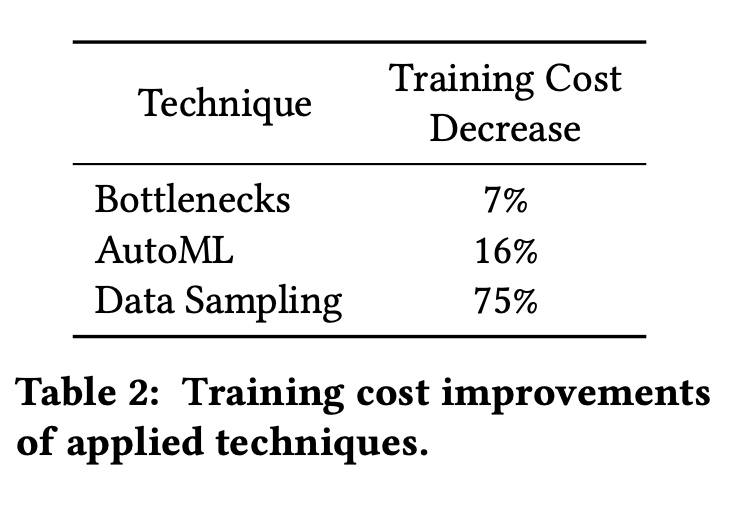
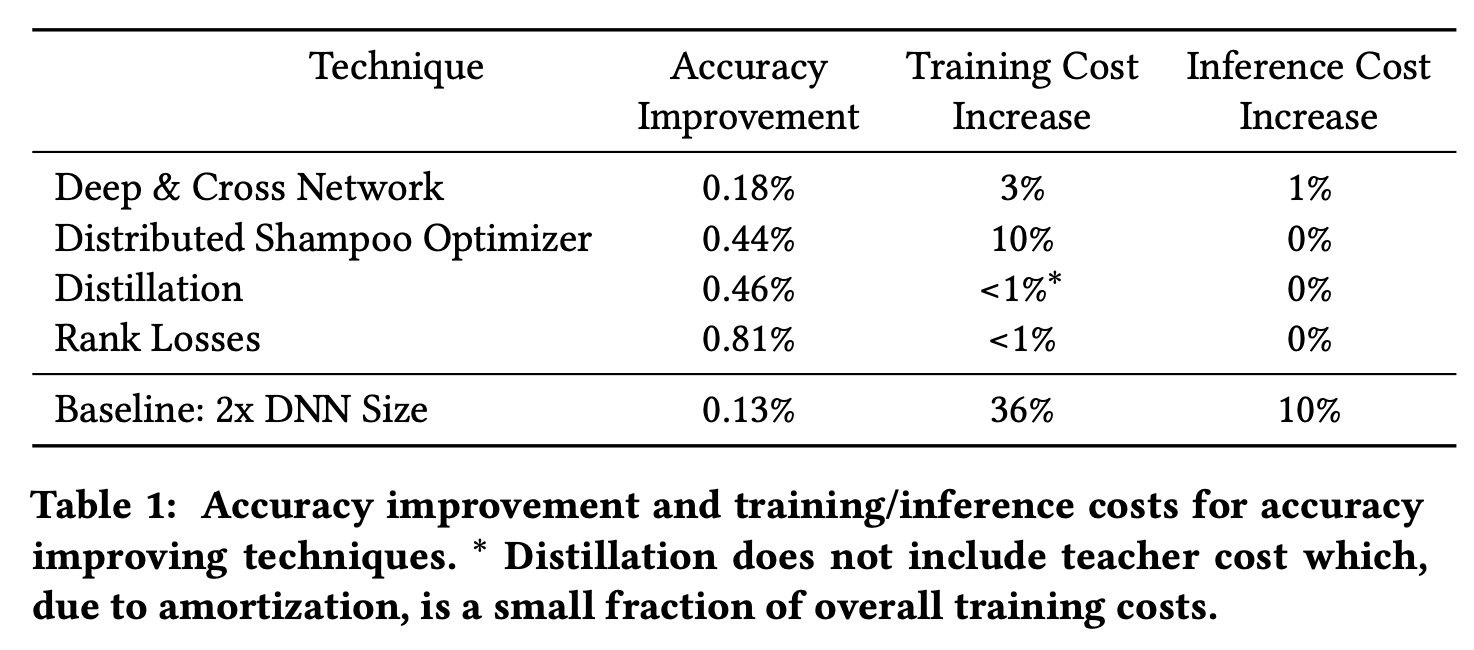
对于降低成本的主要优化包括优化骨干网络、AutoML搜索网络结构以及数据采样,其效果如下
Bottlenecks
提升网络中每一层的宽度是提升准确度的有效手段之一,更宽的网络会有更强的非线性映射能力,但是损失函数和梯度的数据矩阵就会更大,底层矩阵乘法的计算效率就会更慢,矩阵乘法的成本随着矩阵的大小二次增加,对于一个隐藏层\(H_i=\sigma(H_{i-1}W_i)\),其权重\(W_i\in\mathbb{R}^{m\times n}\),我们需要对输入\(H_{i-1}\)的每一行执行\(m\times n\)次相乘并求和的操作,因此更“宽”的策略并不是成本高效的(cost-effective)。针对这个问题,我们发现在非线性层之间插入低秩矩阵可以在损失很小精度前提下,有效降低成本。
通过对\(W_i\)进行奇异值分解,我们可以发现前50%的奇异值贡献了超过90%的价值,这就表示我们可以近似将\(H_{i-1}W_i\)分解为\(H_{i-1}U_iV_i\),其中\(U_i\in\mathbb{R}^{m\times k},V_i\in\mathbb{R}^{k\times n}\),总计算量缩减到\(m\times k+ k\times n\),对于固定的\(k\),如果我们将\(m\)和\(n\)扩大\(c\)倍,总计算量也只是线性增长\(c\)倍。在实际研究中,我们发现这种近似带来的精度损失非常小。增加网络宽度可以提高准确度但却引来计算成本增加,将层的权重矩阵分解可以降低计算成本同时只损失很少的准确度,通过平衡这两者,我们可以做到不增加计算成本的前提下,增加模型的准确度。而平衡这两者可以通过人工调参或者AutoML技术达到,人工调参可以做到准确度持平的条件下,降低约7%的训练成本。
AutoML for Efficiency
为了通过调整CTR模型结构来达到最优的准确度和成本的平衡,经常需要调整embedding以及后续每一个隐藏层的大小,但参数的组合往往是指数级增长的。在实际工业环境中,通过多次迭代来进行参数搜索的方式成本过于高。我们采用了一种基于权重共享的网络结构的搜索方式,通过自动调整网络结构参数来在准确度不变情况下降低训练和预测成本,具体形式如下图所示:
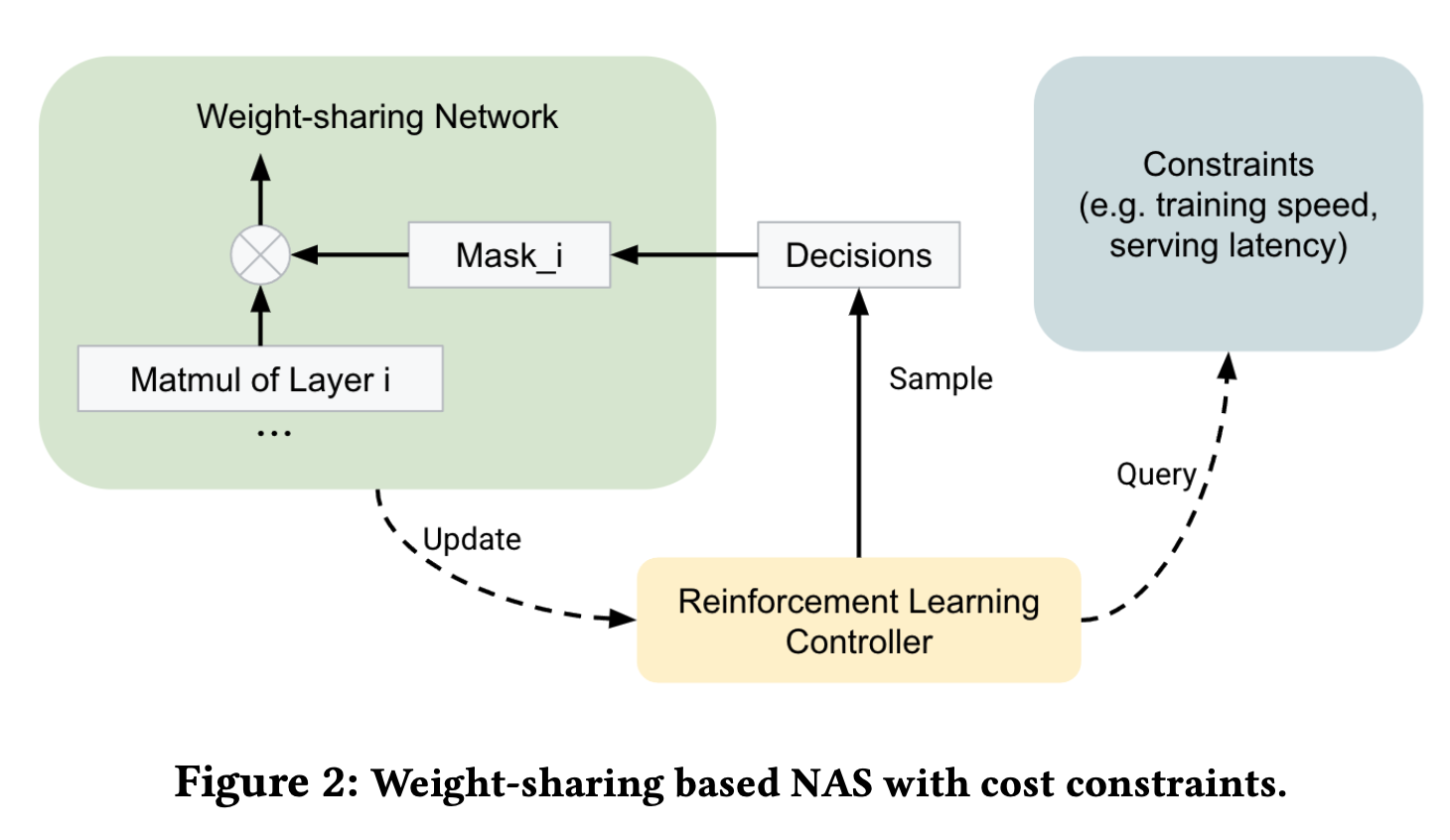
包括三个部分,权重共享网络、强化学习控制器和约束。权重共享网络会构建一个父网络(super-netwrok),包含搜索空间的所有候选的子网络(sub-network),这样我们可以在一次迭代中同时训练所有候选的网络结构,并且通过mask机制选择只激活部分网络。强化学习控制器会维持一个候选网络结构的采样分布\(\theta_\text{dist}\),并从中采样得到\((d_1,d_2,\cdots)\)作为每次训练所需要激活的子网络,奖励记为\(R(d_1,d_2,\cdots)\)(文中并没有给出具体的定义),并采用REINFORCE算法进行学习 \[ \theta_\text{dist} = \theta_\text{dist} +\alpha_0\cdot\Big( R(d_1,d_2,\cdots) - \overline{R} \Big) \cdot \nabla \log \mathbb{P}(d_1,d_2,\cdots|\theta_\text{dist}) \] 其中\(\overline{R}\)表示讲理的均值,\(\alpha_0\)表示强化学习的学习率,在训练结束后,会选择最大概率值的网络结构。约束是指如何计算子网络的成本,会在奖励中考虑部分成本的影响,\(R=R_\text{accuracy}+\gamma \cdot |\text{cost}/\text{target}-1|,\gamma<0\)。
实际使用中,我们会设置成本目标为baseline的85%、90%或者95%,选择相同精度下,成本最小的。
最近一次模型结构的搜索帮助我们节省了16%的训练时间,并且没有降低准确率。
Data Sampling
历史点击样本构成了庞大的数据集,并且每天都会稳定增加,但是样本数量递增所带来的收益是递减的,对于模型效果的边际增量趋近于零,最终只会带来训练计算和数据存储成本,保留所有的数据并不划算,所以我们会采用数据采样的方式来控制训练成本。因为训练方式是一段时间内的样本流(在线训练,所有训练数据会先预测然后进入模型训练),所以有两种方式来减少训练数据:
- 限制所用数据时间范围
- 对数据进行采样
首先只用近期的数据是符合直觉的,更久远的数据分布跟未来数据分布会更加不相关,同时,在任何时间周期内,点击样本都是更稀少且重要的,所以我们对于非点击样本进行采样。因为采样的初衷是为了高效率训练,所以精确的样本平衡并没有必要,采用固定的采样比即可。为了保证模型预估是非偏的,需要对负样本进行逆概率加权(IPW,做causal的同学应该很熟悉)。
另外两种采样策略也被证明是有效的:
- 对logitic loss低的进行采样,即预估值很低的未点击样本(目前预估的已经很好的样本进行采样)
- 根据广告处于页面的位置,对用户不太容易看见的样本进行采样(伪曝光进行样本)
值得注意的是,很小的采样率会造成模型不稳定,增大方差,以及样本加权对于保证模型校准能力非常重要。
对于上面提到的采样策略,需要提前知道样本的loss,如果对每一个样本都进行一次预测,那么后续采样带来的性能的节省就没有意义了,所以我们会用teacher model的预测值作为代替。具体做法为先在全部样本上训练一次,计算损失和采样比率,再用采样的数据训练一次。teacher model只会训练一次,后续迭代只用采样的样本。随着之后模型的更新迭代,即使每个样本的loss会变化,但是第一次训练的模型仍会对样本的“学习难度”有较好的把控。
通过结合基于loss的采样策略和类别加权,不损失准确度的前提下,只需要保留不到1/4的样本。
Accuracy
Loss Engineering
Loss的设计在我们系统中扮演着重要角色,我们的目标是预测一个广告是否会被惦记,模型通常是优化logistic loss(也即二分类问题时,预测分布和真实分布的交叉熵损失),该损失函数可以为我们提供无偏的预测值。
除了预估CTR,我们也希望模型可以做到正确排序,被点击的广告相比无点击的广告应该拥有更高的CTR,因此我们也考虑排序的损失函数。
Rank Losses
我们发现PerQueryAUC(每个query样本的AUC)是和商业目标十分契合的衡量指标。除了额外增加PerQueryAUC作为评估指标外,我们使用rank loss作为第二个损失函数。实践中我们采用Ranknet loss \[ -\sum_{i\in\{y_i=1\}}\sum_{j\in\{y_i\neq 1\}}\log \Big( \text{sigmoid}(s_i,s_j)\Big) \] 其中\(s_i,s_j\)是两个样本的logit score。
rank loss和logstic loss需要一起优化,第一种结合的方式是做多目标优化 \[ {\cal{L}}(W)=\alpha_1 {\cal{L}}_\text{rank}(y_\text{rank},s) +(1-\alpha_1){\cal{L}}_\text{logistic}(y,s) \] 其中\(y_\text{rank}\)是排序的label,\(y\)是二分类任务的label,\(\alpha_1\in(0,1)\)是rank-loss的权重,另一种方式是采用多任务学习,其中模型会针对每个loss给出不同的估计\(s\) \[ {\cal{L}}(W_\text{shared}, W_\text{logistic}, W_\text{rank}) =\alpha_1 {\cal{L}}_\text{rank}(y_\text{rank},s_\text{rank}) +(1-\alpha_1){\cal{L}}_\text{logistic}(y,s_\text{logistic}) \] 其中\(W_\text{shared}\)是共享的权重,\(W_\text{logistic}\)和\(W_\text{rank}\)分别对应logistic loss和rank loss的输出的参数,rank loss可以理解为对于\(W_\text{shared}\)的一种正则项。
因为基于rank loss的预测并具有校准性质,所以模型的预测值会存在偏差,所以会需要校准模块。
Distillation
蒸馏技术会增加额外的辅助loss,将更大capacity的teacher model的输出作为soft label进行学习。在我们的模型中,我们采用两步在线蒸馏的方法。在第一阶段,teacher model会在训练前对每一条样本进行预测,studnet model会用teacher model的预测值进行第二遍训练。因此,teacher model的计算成本可以分摊到多个student model上,整体来看并不会显著增加训练成本。
除了增加准确度,蒸馏也可以用来降低训练数据的成本。一旦高capacity的teacher model训练一次,其后续可以在更大的数据集上进行训练,student model也会受益于teacher model所学到的知识,并且只需要更少、更近期的样本。
蒸馏对于student model会带来0.41%的精度提升,同时训练和推断计算成本并没有变化。
Curriculums of Losses
课程学习(Curriculums Learning)一般是指模型从简单的任务开始学,逐渐过渡到复杂的任务上。我们发现直接对所有Loss进行训练会导致模型不稳定,因此我们先训练二分类logistic loss,然后逐渐增加蒸馏和rank loss。
Second-order Optimization
用二阶优化方法对DNN模型进行优化在产品级的ML系统中十分少见,谷歌内部系统Distributed Shampoo,将二阶优化方法应用于工业级模型训练。在我们的场景中,较大的batch size已经将训练成本降低,所以采用二阶优化仅增加了10%的训练时间,带来模型的准确度提升收益也高于训练时间增加的成本。
学习率替代(Learning Rate Grafting)。在线学习的一个主要挑战就是制定学习率改变方式。与静态数据上的训练模型不同,在线模型的训练步数一般是未知的,甚至无边界的。目前依赖于固定的时间范围的学习率衰减方式,比如指数衰减等,效果要差于依赖数据的自适应调节方法。在实践中我们发现AdaGrad在在线学习中效果也很好,特别是在\(\epsilon\)参数调整后,因此我们用AdaGrad为每层计算出的步长和Distributed Shampoo计算出来的下降方向进行模型参数更新。
动量(Momentum)。另一个有效的实现是结合Nesterov动量和梯度,我们分析发现在Shampoo的基础上增加动量对于模型的提升增益最大,同时也没有增加计算成本,知识增加了存储开销。
稳定性和效率(tability & Efficiency)。Distributed Shampoo在迭代中会有更高的计算复杂度,首先我们采用了分块的方式降低计算复杂度,同时实现并行更新,此外优化器独立于batch的大小,因此我们可以用更大的batch来减少计算,最后我们发现数值稳定性非常重要,所以我们采用双精度浮点数,并且将CPU附在TPU中来进行求根计算,整体流程如下图所示
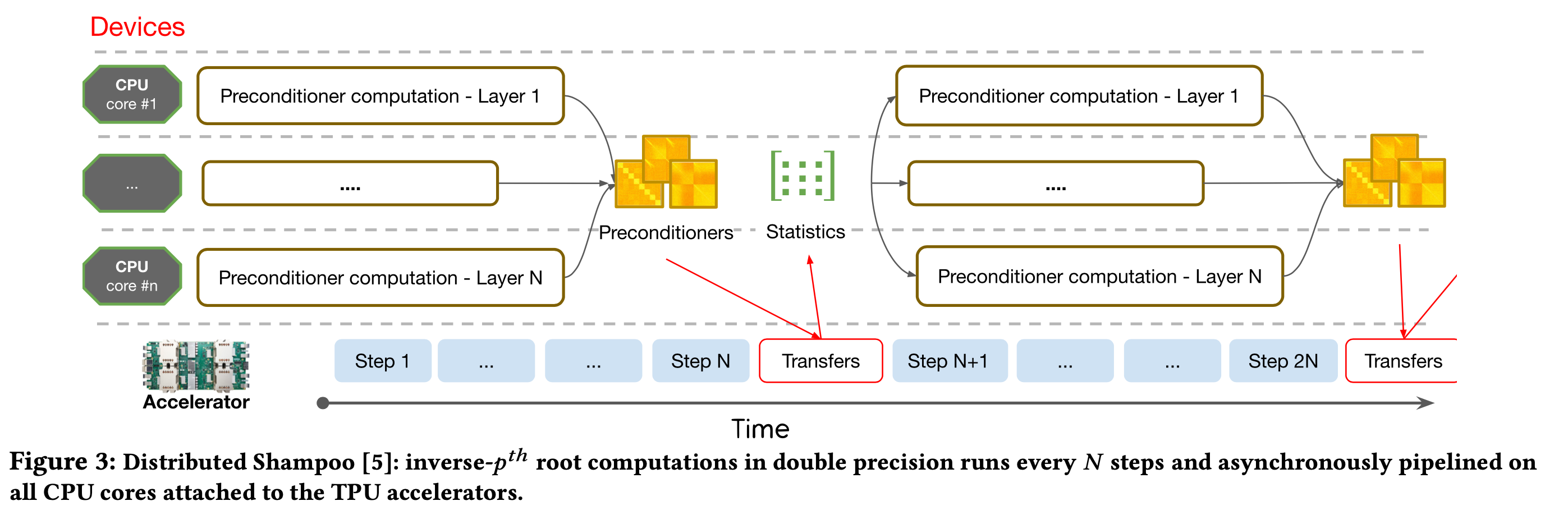
采用Distributed Shampoo进行优化后,PerQueryAUC增加了0.44%(0.1%即显著)作为对比,将网络结构变宽一倍也只提高了0.13%。
Deep & Cross Network
学习交叉特征对于推荐系统十分重要,我们采用DCNv2作为主干网络,其处于embedding层\(e\)和DNN网络中间,将所有embedding向量拼接起来\(e_0=\text{concat}(\tilde{e}_1,\cdots,\tilde{e}_F)\in\mathbb{R}^m\),\(F\)为特征数,下一层的输出为\(e_i=\alpha_2(e_0 \odot U_iV_ie_{i-1})+e_{i-1}\),\(U_i\in\mathbb{R}^{m\times k},V_i\in\mathbb{R}^{k\times m}\)为需要学习的参数矩阵,\(\alpha_2\)在训练过程中从0增加到1,让模型在开始的时候优先学习embedding,然后再学习交叉的特性。
除此之外采用ReZero的初始化可以增加模型的稳定性和可复现性。
采用Deep & Cross 网络结构有0.18%的准确度提升,但是增加了3%的训练成本。
Summary of Efficiency and Accuracy Results
Irreproducibility
不可复现性并不容易检测,因为其可能出现在部署后系统指标变动中,而不是在验证集的评估中。相同的模型可能会收敛到高度非凸目标函数的两个局部最优解中,即使平均准确度相同,但是个体的预测值会有差异,模型部署后,样本选择偏差进一步增强,进而导致两个模型的差异进一步增大。这种现象会严重影响开发,当模型被重新训练并部署到生产环境中,收益可能会消失。
许多因素都会导致模型的不可复现性,包括随机初始化、高度并行的分布式训练、数值误差、硬件问题等等,在训练初期轻微的差距,也会随着不断训练而产出完全不同的模型。同时目前标准的训练指标并无法度量不可复现性,此处我们采用模型预估的偏差作为近似的观测指标,避免我们在部署后才能发现问题,该指标定义为相对预测差异(Relative Prediction Difference,PD),对于模型1和模型2而言,PD为: \[ \Delta_r = 1/M \cdot \sum_i |\hat{y}_{i,1} - \hat{y}_{i,2}| / \big( (\hat{y}_{i,1} + \hat{y}_{i,2}) / 2\big) \] 在深度模型中,PD一般会高达20%。令人惊奇的是如固定初始化、正则、dropout、数据增强甚至增加约束,都无法改善PD指标,或者是以降低精度为代价提高了PD指标。Warm-starting的训练方式(用之前模型的参数进行启动)可能会导致模型在一个次优的空间内进行训练,并不适合。集成学习的方式,特别是self-ensemble,通过平均多个预测模型的输出,可以降低预测的方差,提升PD指标。但是在实际产品系统中维持一个集成学习模型可以说是一种技术债。即使部分文献表明这种集成学习会带来准确度的提升,但是我们尝试后发现,相同训练成本下ensemble表现并不如单模型。
上面说的这些方法,是对模型准确度、复杂性和可复现性的置换。
随着不断研究和实验,我们发现ReLU激活函数对于提升PD有帮助,因为ReLU会降低目标函数的非凸性,即平滑的激活函数一方面可以降低损失函数的非凸性,另一方面可以提升模型的可复现性。在我们的尝试中,我们发现SmeLU激活函数在可复现性和准确度上会有更好的效果 \[ f_\text{SmeLU}(z)= \begin{cases} 0 && z < -\beta \\ \frac{(z+\beta)^2}{4\beta} && |z|\leq \beta \\ z && z >\beta \end{cases} \] 在我们的系统中,用3部分集成可以将PD从17%降低到12%,蒸馏可以进一步将PD降低到10%,SmeLU可以在单模型上将PD降低到低于10%,同时准确度也提升了0.1%。
Generalizing Across UI treatment
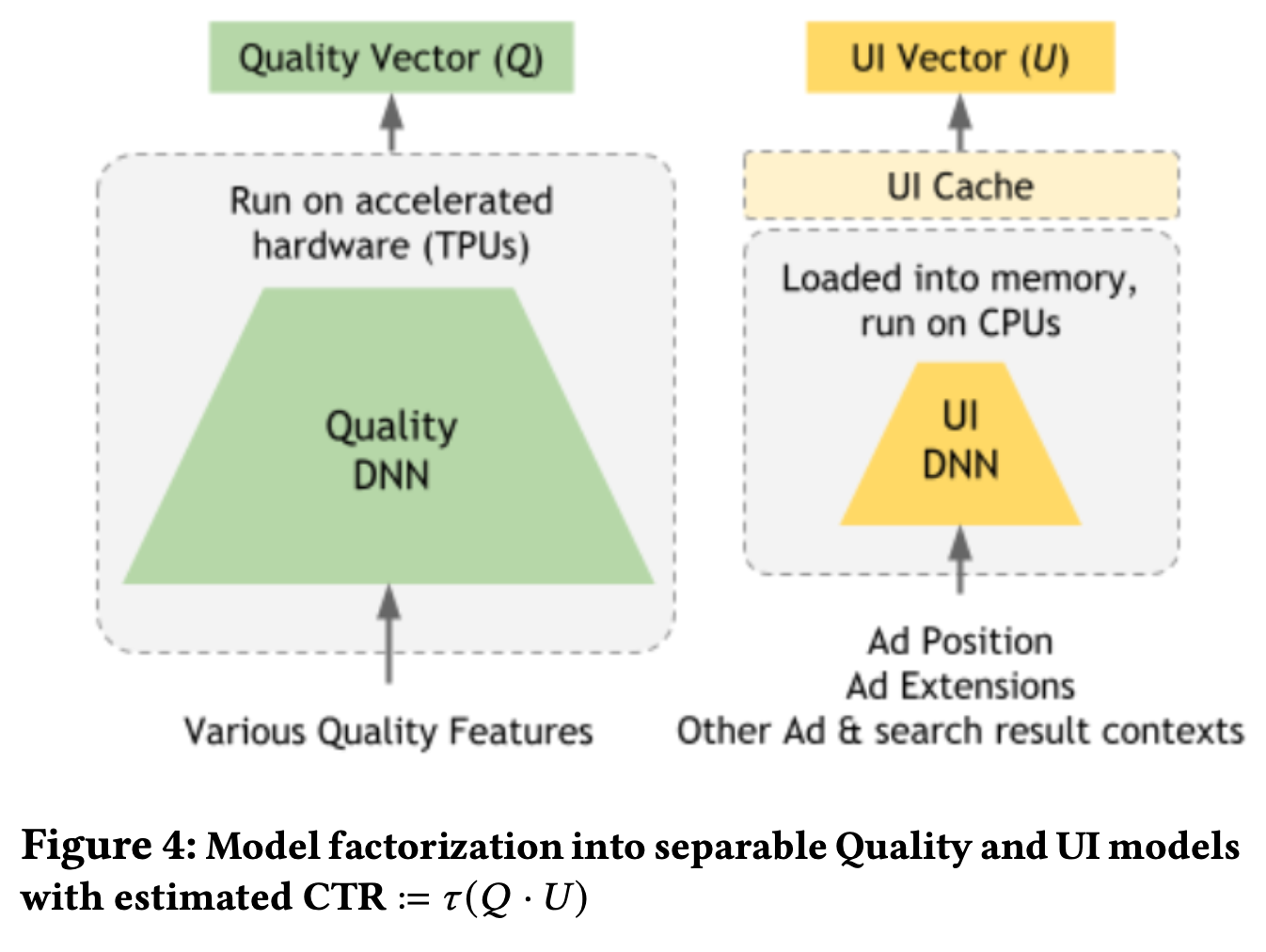
影响广告CTR模型效果的核心因素之一就是UI的干预,包括位置、页面上周边结果的相关性和特定的样式(加粗字体或者行内图片等等)。一个复杂的竞价系统不仅需要探索需要展示什么结果,同时也需要关注该如何展示给用户,并且这种探索必须在大规模的组合干预上有效进行。
我们通过将CTR模型分解为\(\tau(Q\cdot U)\)来解决这个问题,其中\(\tau\)是迁移函数,\(Q\)和\(U\)是不同的模型,分别输出质量(Quality)和UI的向量表征,\(Q\)是由大的DNN模型和各种特征embedding组成,每个广告只做一次打分,\(U\)是轻量级的模型,会针对一个广告进行多次打分,同时由于特征空间较小,可以通过缓存的方式显著降低查表带来计算成本。
校准在广告推荐系统中非常重要,校准偏差定义为标签与预测值的差值,我们希望每个广告的校准偏差为0。一个校准的模型可以让我们通过预估的CTR来权衡并决策是否展示广告以及具体展示哪一个广告。
结果归因(credit attribution)的概念和反事实推理或者隐式反馈的偏差很相似,很难在模型的权重中体现,同时也会造成不可复现性。想象这样一个例子,模型A见过很多靠前位置高CTR的样本,并且学习到了广告的位置会影响CTR,模型B与A相似,但是只用一些高CTR但是靠后位置的样本进行训练,学习到一些诸如相关性的因素对于CTR的影响,离线看,两个模型都会对这些广告有较高的CTR打分,但是却出于不同的原因,当我们将两个模型部署上线后,模型A在靠后的位置就会更倾向于不展示广告。
(文中这段写得理解成本偏高,个人理解就是历史训练数据中confounder的存在,模型会学到一些伪相关性,导致对于最终结果的归因有差异,即是什么特征导致高CTR的预估的差异,离线数据评估效果相同,线上实验结果却不一致。查了查并没有发现对 credit attribution 较好的翻译,此处我就根据自己的理解翻译为 结果归因 了)
在我们的系统中,我们通过在目标函数中增加bias constraints的方式来同时解决校准和结果归因的问题。这种方式相比反事实推理、逆概率加权等方式会更轻量级,在实践中,只需要调整很少的参数,并且我们只是通过在目标函数中增加一项而不是修改模型结构。
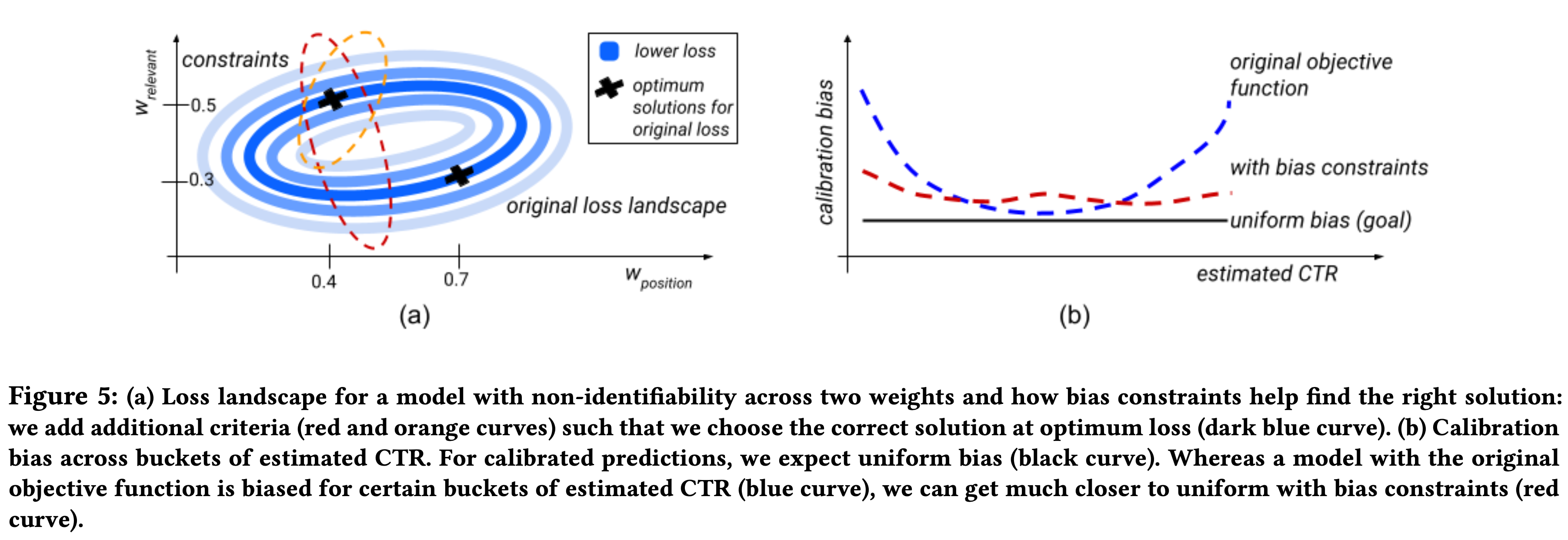
Bias Constraints
Online Optimization of Bias Constraints
我们希望在优化原始的目标函数时,考虑约束\(\forall k \forall i\in S_k, (y_i - \hat{y}_i)=0\),其中\(S_k\)表示我们希望校准的训练样本的子集,或是我们想或不想在优化模型使用的样本(比如在随机干预或者探索时收集到的OOD / off-policy下的数据)。
首先通过对偶变量\(\lambda_{k,i}\)将约束优化转化为无约束优化,并且通过对偶变量最大化拉格朗日函数,其次与其让\(S_k\)上的每个样本的bias为0,我们希望让\(S_k\)上样本平均bias的平方为0,这样不仅使得对偶变量数量缩减为\(\{\lambda_k, \forall k\}\),同时等价于增加关于\(\lambda_k\)的L2正则项和一个平均bias为0的约束,如下式,\(\alpha_3\)用于控制正则项损失,并且可以通过超参数调优的方式进行优化 \[ \underset{W}{\min}\underset{\lambda_k}{\max} \sum_i {\cal{L}}(y_i,\hat{y}_i) + \sum_{k=1}^{K} \sum_{i\in S_k} (\lambda_k (y_i - \hat{y}_i) - \frac{\alpha_3}{2}\lambda_k^2) \] 增加这部分损失函数所导致的准确率或者稳定性的下降可以通过如下方式进行调整,按影响排序依次为:逐渐增加bias constraint,降低\(\{\lambda_k, \forall k\}\)的学习旅,增加\(\alpha_3\),增加更多约束,其中前两种策略可以帮助降低对偶变量和其他权重的差异,后两种策略可以降低不合适约束的影响。
Bias Constraints for General Calibration
如果我们将校准偏差画出来,会发现校准偏差往往不是均匀分布的,在实际中我们常常发现对于分布边缘的样本校准偏差往往更大。我们将样本按照预估CTR进行分桶来构建bias constraints进行校准(个人理解,online learning是线上先预测再训练,此处预测的CTR仅用于分桶构建约束)。
Exploratory Data and Bias Constraints
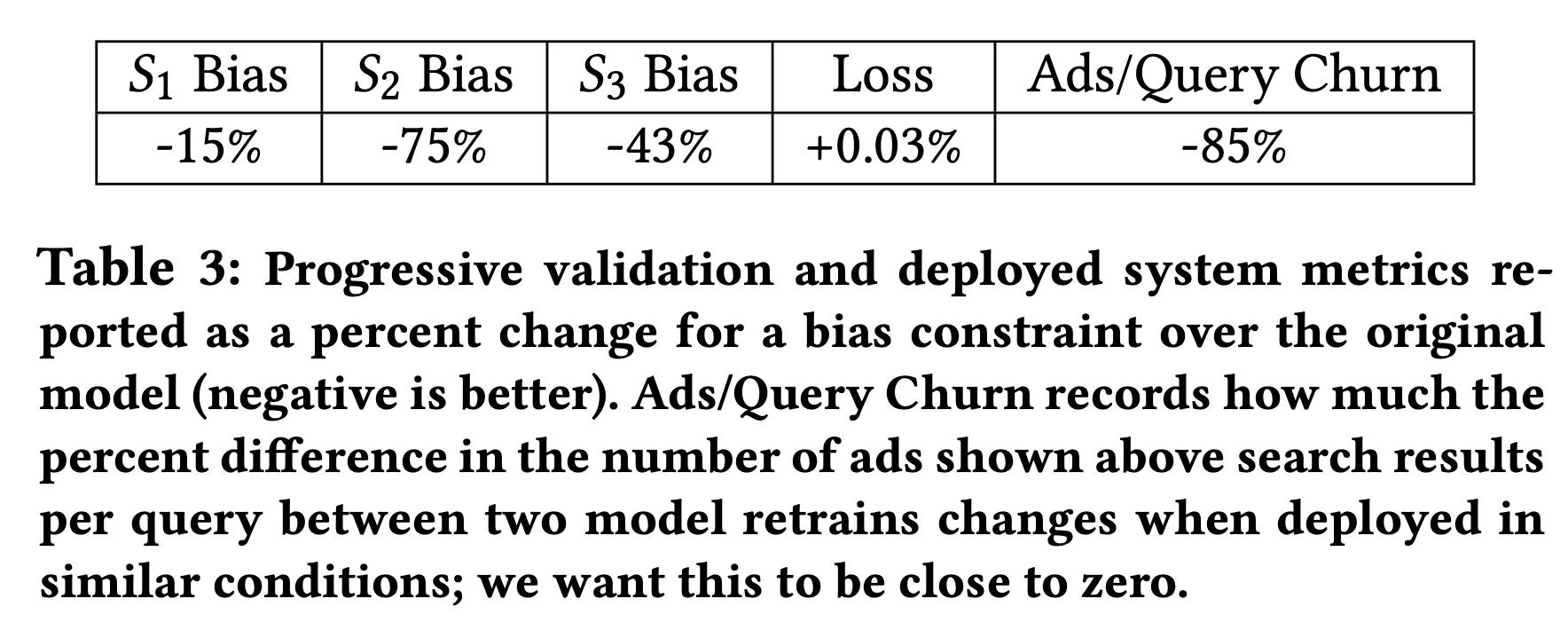
我们也可以用bias constraint来解决UI干预导致的结果归因问题,根据UI的展示差异把样本来划分为若干子集,比如\(S_1\)是高CTR但是展示在页面底部,\(S_2\)是高CTR展示在页面第二到最后的位置等等。依赖于模型的实现方式,按照特征去划分会更简单,我们选择特征集合\(\{f\}\),既要保证样本足够多不会影响模型收敛,也要做到粒度足够细 来确保单个样本的校准偏差降低。对于下表中所用到的模型,我们在每个子集上都显著降低了bias,同时增加了可复现性,准确度只是降低了一点点。
Conclusion
本文中我们详细介绍了一些用于大规模CTR预测的技术,这些技术在实际应用中被证明足够有效,包括平衡准确性的提高、训练和部署成本、系统可重复性和模型复杂性,同时也描述了针对UI干预的通用处理方式,希望本文可以引起相关从业者关于CTR预测、推荐系统、在线训练系统和大规模工业系统设计的兴趣。