摘要
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English- to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.0 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature.
主流的序列翻译模型是基于包含encoder和decoder的RNN或者CNN模型,目前效果最好的模型是通过attention机制来连接encoder和decoder。
我们提出一种简洁的网络结构,Transformer,只采用attention机制,并不需要RNN和CNN的结构,在两个机器翻译的任务上的实验表明,这种模型能产生更高质量的结果,同时拥有更高的并行度,训练时间更短。
我们的模型在WMT 2014英语德语翻译任务上达到28.4 BLEU ,超出了所有已知模型的效果,包括集成模型,超出2 BLEU,在WMT 2014英语法语翻译任务上,单个模型的评估中,达到41.0 BLUE,而这只需要8GPU上3.5天的训练时间,是之前最好模型所需训练时间的很小一部分。
背景
有很多工作将RNN、LSTM、GRN等模型应用于序列建模和语言模型建模、机器翻译等场景上,并取得了较好的结果,然而RNN这类方法在训练中会需要按照序列中元素的先后顺序,处理输入和输出,这就导致无法进行并行计算而增加训练成本。虽然已经有一些工作针对这个问题在做优化,但是序列计算的基本约束仍然存在。
Attention机制在众多序列建模的任务上都有较好的表现,其可以建模序列中不同部分的关系,同时并不受序列长度的影响,但在大部分工作中,Attention机制都是和RNN一起使用的。
本文提出一种Transformer的结构,只保留Attention机制,计算时的并行度显著提升,并且最终效果也更好。
方法
再序列翻译模型中一般采用Encoder-Decoder架构,Encoder将输入\((x_1, \cdots, x_n)\)映射为中间表征\((z_1, \cdots, z_n)\),Decoder再将中间表征转化为\((y_1, \cdots, y_m)\),在每一步中,模型都采用一种自回归(auto-regressive)的方式,将前一个输出和中间表征共同作为Decoder的输入。
模型结构如下图所示,主要分为几部分,我们一一来讲。
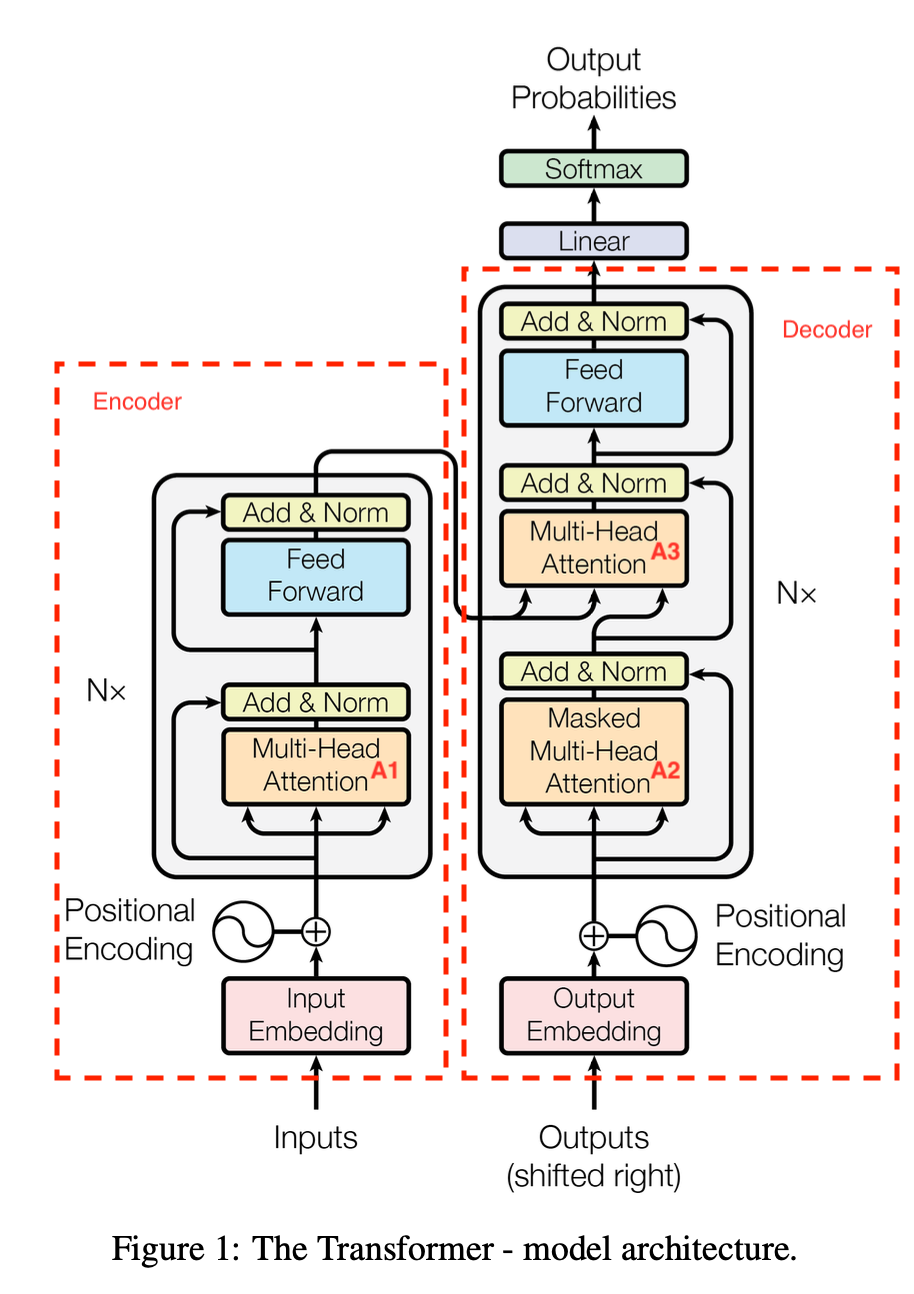
Encoder和Decoder
上图中左侧部分是Encoder,右侧部分是Decoder。
Encoder是由N=6个子部分堆叠组成,每部分包含一个Multi-Head Attention和FFN(也就是一个MLP层)组成,前后会按照ResNet的方式做输出的相加,并做LayerNorm。因为其中会有残差相加的方式,所以为了方便,所有层的输出都是一样的\(d_\text{model} = 512\)。
Decoder也是由N=6个子部分堆叠组成,与Encoder不同的是,Decoder中间会多一层,用于引入Encoder的输出。
此处多提一句LayerNorm,BatchNorm大家应该都很熟悉,是针对一个Batch内每一维度的特征,做Batch内的归一化,但这种做法对于序列的处理并不一定合适,一是因为序列的长度是动态可变的,二是针对Embedding的某个维度做不同样本间的归一化没有意义,所以在语言模型中常见的做法是做LayerNorm,可以近似理解为针对某条样本,对其序列中所有Embedding做归一化。
Attention
Attention函数是一种将Query(Q)和一个Key-Value(K-V)集合映射到输出的函数,输出的结果是一个值的加权和,权重由Q和K得到,值为V。
如图中所示,Transformer包含三种不同的Attention:
- 图中A1,Encoder中的Multi-Head Attention,实现为Self Multi-Head Attention,Q、K、V都是输入的序列
- 图中A2,Decoder中的Masked Multi-Head Attention,实现为Self Multi-Head Attention,Q、K、V都是之前每一步输出结果的Embedding,但是会对序列右侧的元素做Mask
- 图中A3,Decoder中的Multi-Head Attention,Q为之前的输出的结果,过完Masked Multi-Head Attention的输出,K、V为Encoder的输出
下面详细讲一下Attention的设计
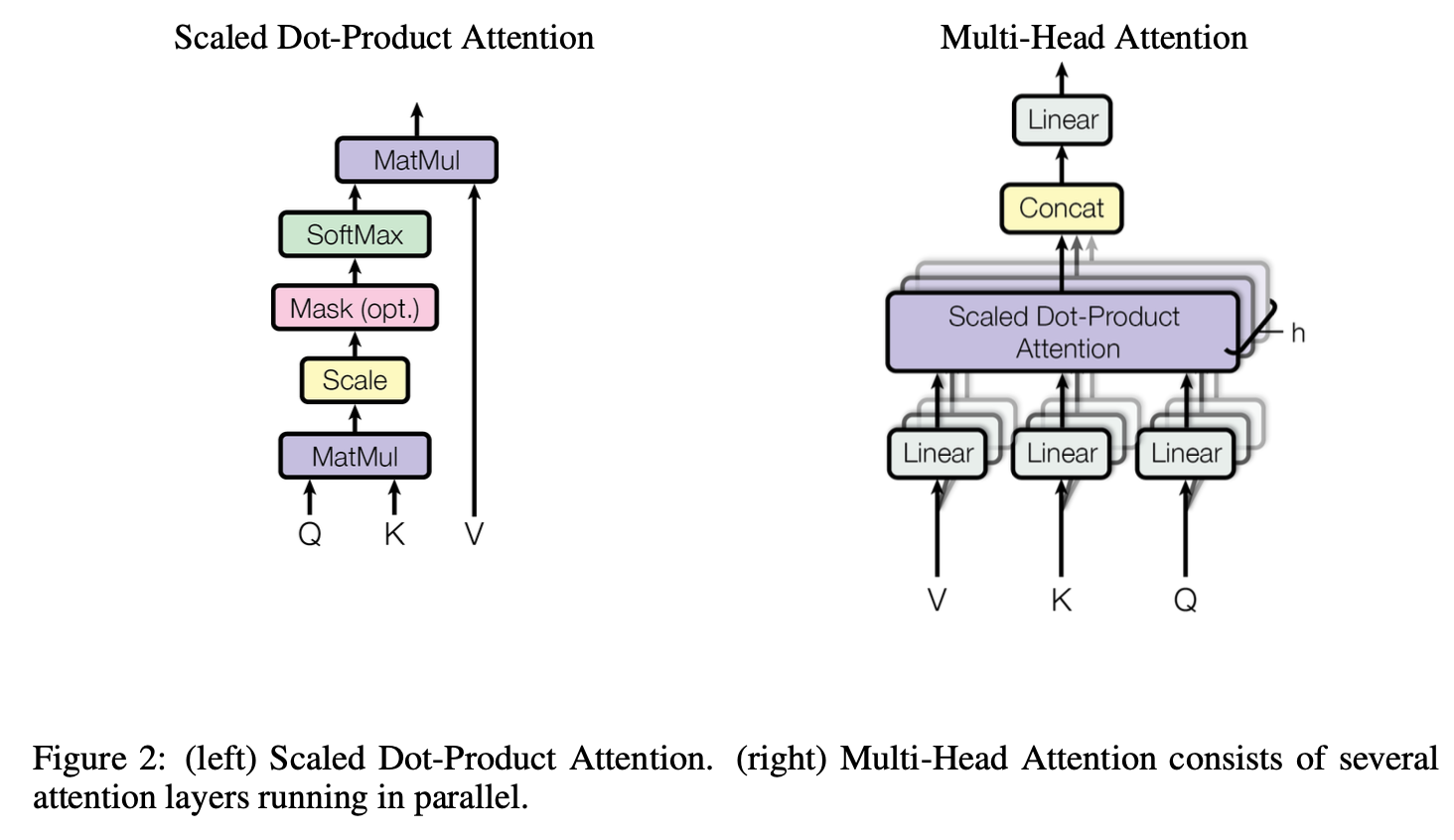
Scaled Dot-Product Attention
我们将上图中左侧的Attention设计称为Scaled Dot-Product Attention,其计算方式为 \[ \text{Attention}(Q,K,V) = \text{softmax}\Big(\frac{QK^\intercal}{\sqrt{d_k}}\Big)\cdot V \] 先将Q和K做乘法,得到距离度量的标量,然后为了降低表征向量维度大小的影响,做scaling(维度过高时候,会导致softmax中的值过大,迭代中梯度过小)
中间存在一个可选的Mask的步骤,如果是Decoder中的Attention,在自回归的方式下,需要屏蔽掉句子当前预测词后面的词汇,具体的实现方式是用一个较小负数(-1e10)替换掉对应位置元素值,这样做softmax时,其取值会趋向于0,不破坏softmax求和为1的性质。
Multi-Head Attention
因为点乘的Attention并没有可学习的参数,信息量仍是由原始的QKV提供,所以相比于使用一组QKV做Attention,作者发现对QKV做不同的权重的线性映射,会有更好的效果。
如上图中右侧图所示,针对QKV分别作h次线性映射,投影至\(d_k,d_k,d_v\)维,然后再经过多个Attention,最终将不同Attention的输出拼在一起作为最后的输出。 \[ \begin{aligned} \text{MultiHead}(Q,K,V)&=\text{Concat}(\text{head}_1,\cdots,\text{head}_h) W^O \\ \text{head}_i &= \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) &\forall i \end{aligned} \] 其中\(W_i^Q\in\mathbb{R}^{d_\text{model}\times d_k}, W_i^K\in\mathbb{R}^{d_\text{model}\times d_k}, W_i^V\in\mathbb{R}^{d_\text{model}\times d_v},W^O\in\mathbb{R}^{h d_v\times d_\text{model}}\),本文中\(h=8,d_k=d_v=d_\text{model}/h=64\)。
这种做法可以使的模型在不同的Head上有不同的Attention权重,同时关注到序列中多个位置。
Position-Wise Feed-Forward Network
即前向网络,就是一个多层的全连接层 \[ \text{FFN}(x)=\max(0, xW_1 +b_1) W_2 +b_2 \] 激活函数为ReLU,中间层会采用更宽的网络\(d_{ff}=2048\),输出仍保持\(d_\text{model}=512\)。
这个网络是每个位置的词都需要过的,所以叫Point-Wise,比如一个batch内的训练样本是\(B\times S\times E\),其中\(B\)是batch size,一个batch内样本数,\(S\)是序列长度,一条样本中的token数,\(E\)是Embedding的大小,此处是每个Embedding会过这个网络。
Embedding and Softmax
将输入和输出都转为embedding,再过模型,embedding层是共享的,且会在原始权重基础上乘以\(\sqrt{d_\text{model}}\),在最终输出结果前,会先过一次线性映射,再过softmax。
Position Encoding
由于模型没有采用RNN或者CNN的结构,只用Attention无法提取到序列中元素的位置信息,所以文中采用位置编码的方式,和输出的embedding相加作为模型的输入。
Position Embeding也是\(d_\text{model}\)大小,具体编码规则如下 \[ \begin{aligned} PE(\text{pos}, 2i)&= \sin(\text{pos} / 10000^{2i / d_\text{model}}) \\ PE(\text{pos}, 2i+1)&= \cos(\text{pos} / 10000^{2i / d_\text{model}}) \end{aligned} \] 其中\(\text{pos}\)就是token位置,\(i\)是embedding的第\(i\)维。文中也提到实验对比了学习position embedding的效果,并没有明显差别,同时这种方式相比学习的embedding,序列过长的时候,外推泛化能力更强。
Why Self Attention
相比于CNN和RNN,Self Attention的方式在计算量上,并没有明显差异,但是对于序列处理所需要的时间(下图中Sequential Operations,RNN需要对序列一个个元素进行处理)、以及序列前后信息传递的效率(下图中Maximum Path Length,序列上第一个元素信息传递给最后一个元素,RNN需要O(n),CNN需要O(logk(n)))上,却更高效。
