今天读ESL,看到第二章中对LS(Least Square)和k-NN的bias和variance对比,突然有了些新的理解,在这里记录一下。
All we know
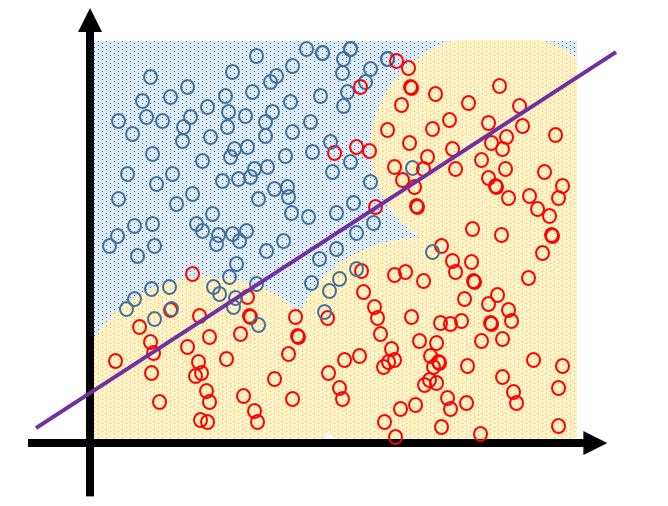
放一张经常可以看到的图,这张图来自机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系? 中的@修宇亮 的回答。
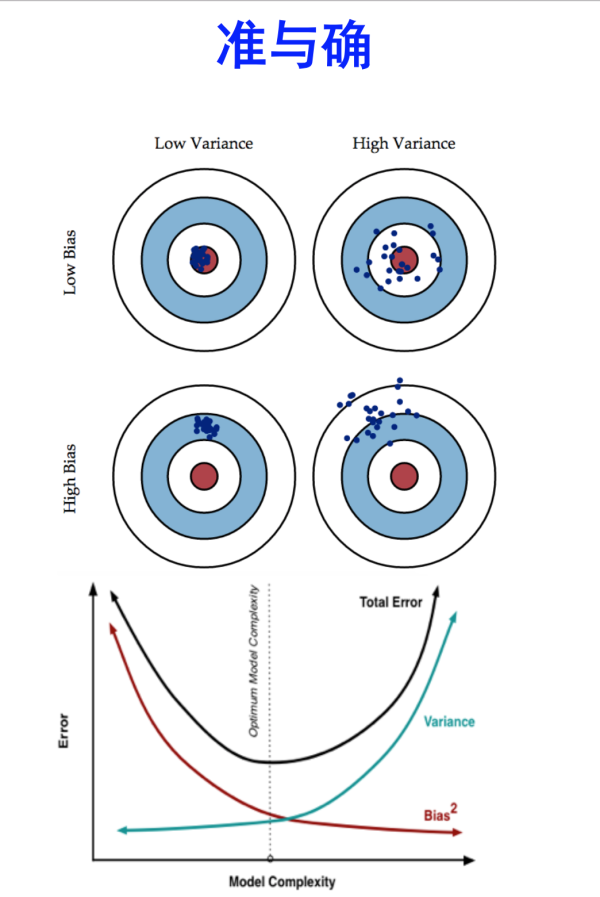
原图应该是PRML里的图好像,记不清了。
还有之前文章中写得
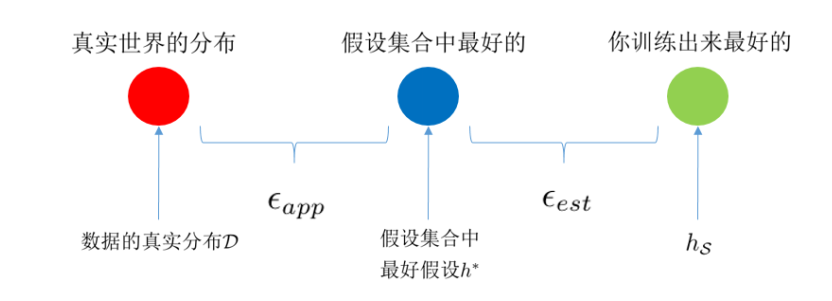
简单来说,bias决定假设集合中最好的假设与真实上帝函数的差别,而variance是训练中以经验风险最小化原则得到的假设与bias假设集合中最好假设的差别。
What I find today
简单的来说,bias就是模型对整体训练数据的把握,而variance描述每个样本扰动对模型的影响。
今天看ESL时,书中说:
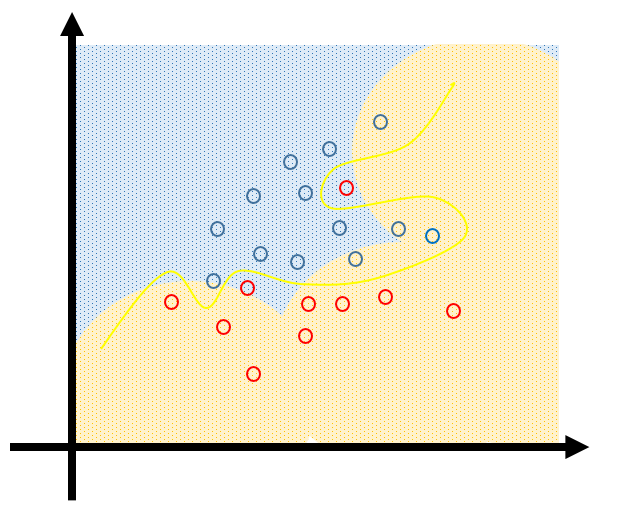
The linear decision boundary from least squares is very smooth, and apparently stable to fit. It does appear to rely heavily on the assumption that a linear decision boundary is appropriate. In language we will develop shortly, it has low variance and potentially high bias. On the other hand, the k-nearest-neighbor procedures do not appear to rely on any stringent assumptions about the underlying data, and can adapt to any situation. However, any particular subregion of the decision boundary depends on a handful of input points and their particular positions, and is thus wiggly and unstable—high variance and low bias.
LS得出的结果有较低variance和较高bias,而k-NN得出的结果有较高的variance和较低bias。
看到这里的时候我觉得可以这么理解:
- bias是表明模型在整体数据上表现,受到的是训练数据的影响,是寻找最佳模型时的衡量标准,而不在乎其中某一个样本的正确与否
- variance是相对单个样本而言(此处表述不准确,仅仅是这种意思),一个样本的变动会给整个模型带来多大的影响,是模型抗样本干扰能力有多强
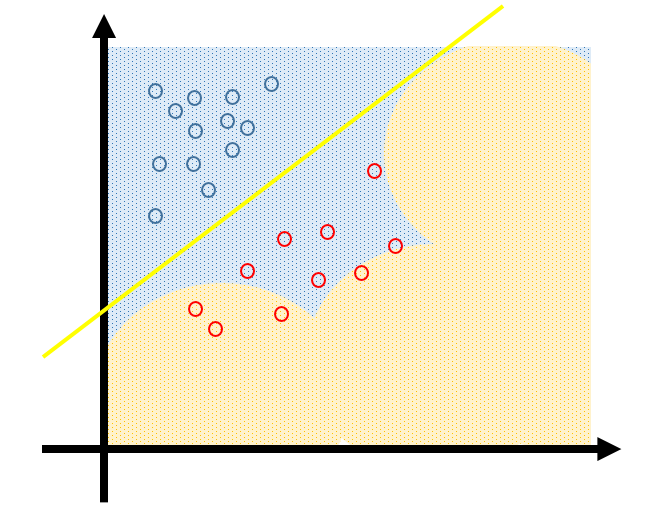
画图来解释,我们的数据分布如下,底下为真实分布,圆圈为我们采到的样本。
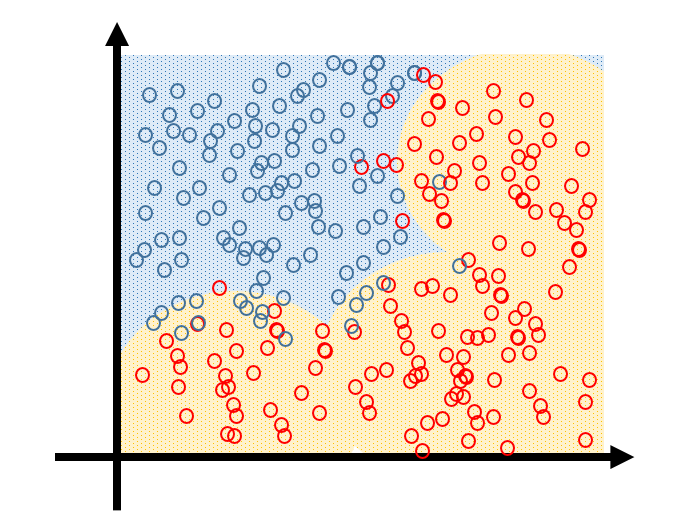
通常我们选择的模型应该是这样的
足够简单,而且能够最大程度描述数据的分布。
我们用简单的模型来描述数据时,特别是当我们采到的训练样本有问题时,我们就会得到一个高bias的模型
此时,单个样本的正确与否不会过多地影响整体模型。
当我们用复杂的模型来描述数据时
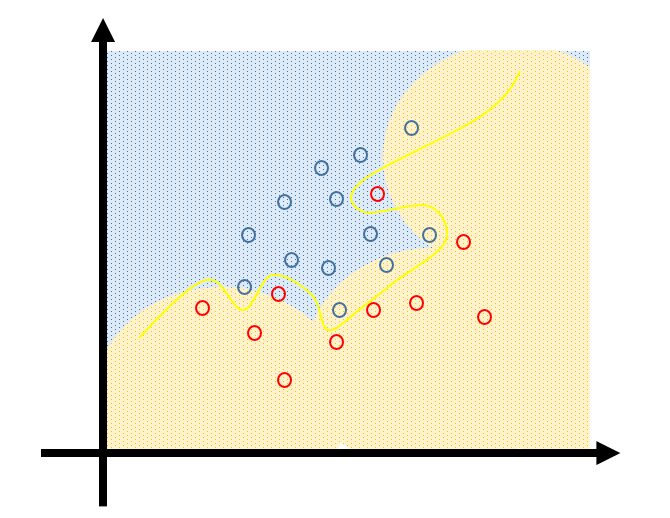
尽管我们能在训练数据上表现很好,可单个数据的变动,就会很大程度影响模型
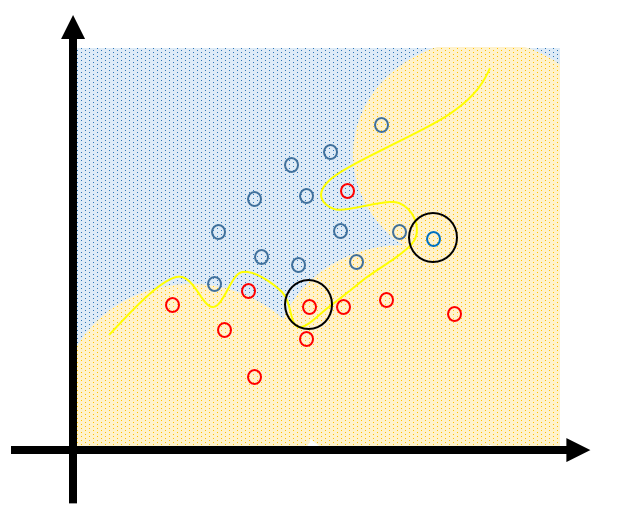
样本的扰动(或者说误差)会很大程度影响模型,这样的模型具有高variance。
Bias and Variance in Bagging and Boosting
为什么说Bagging是减少variance,而Boosting是减少bias?之前一直比较困惑,今天感觉可以说通了。Bagging是bootstrap+aggregation,对样本的不断重采样和聚合训练,不断减少了每个样本的影响,增加了总体对于各个样本的抗干扰能力,所以是降低variance。而Boosting是串行的迭代算法,不断去改进拟合每一个样本,自然对样本的依赖性强,虽然可以很好的拟合所有训练数据,但是如果训练数据有问题,则模型会很差,bias也就很高。
What else

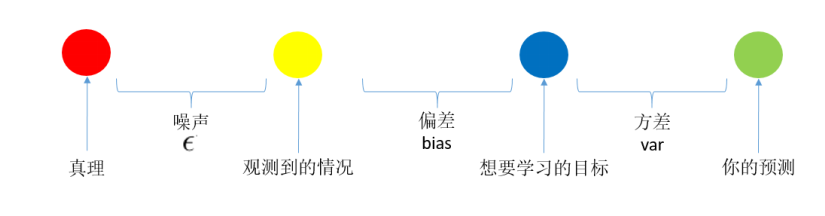
这张图也来自机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系? 中的@修宇亮 的回答。刚好看到这段,读过UML之后对这段话也是有所理解了。如果让训练误差小,则需要增加模型的capacity,模型复杂了,假设集合就大了,使训练误差和泛化误差足够接近的样本数也就多了,此时复杂的模型具有低的bias,反之,如果样本数量一定了,为了让训练误差和泛化误差足够接近则需要选择小的假设集合,也就是降低模型的capacity(某种程度上可以认为是参数数量),此时模型有较小的variance。