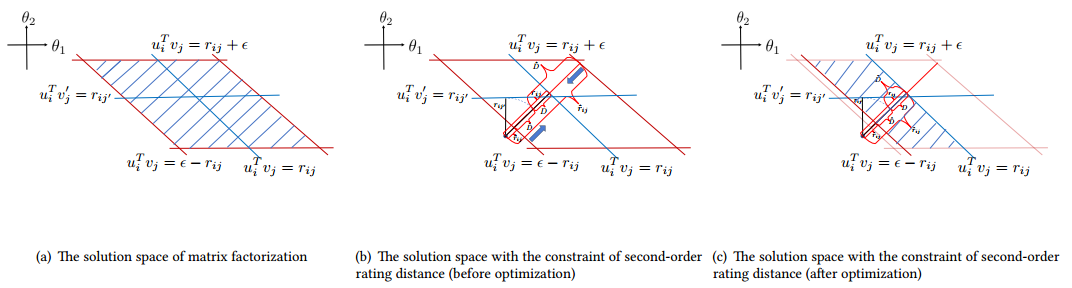
$$ 作者还对这一算法进行了几何上的解释
之后还给出了HoORaYs的概率图模型
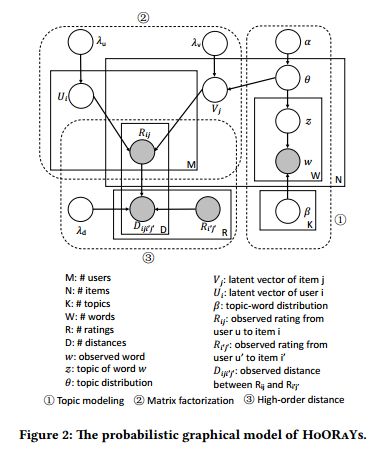
- 对于每个用户\(i\) ,隐变因子\(u_i\sim\mathcal{N}(0,\lambda_u^{-1}I_K)\)
- 对于每个物品\(j\) ,
- topic属性\(\theta_j\sim \text{Dir}(\alpha)\)
- 物品隐因子\(v_j=\epsilon_j+\theta_j,\epsilon_j\sim\mathcal{N}(0,\lambda_v^{-1}I_K)\)
- 对于每个词\(w_{jn_w}\)
- 从topic中指定\(z_{jn_w}\sim \text{Mult}(\theta_j)\)
- 指定\(w_{jn_w}\sim\text{Mult}(\beta_{z_{jn_w}})\)
- 对于每个评分项\(r_{ij}\sim\mathcal{N}(u_i^Tv_j,c_{ij}^{-1})\)
- 对于距离\(d_{iji'j'}\sim\mathcal{N}(\sigma(u_i^Tv_j,r_{i'j'}),\lambda_d^{-1})\)
采用一种EM方式来最大化似然函数求解(具体的木有细看)。
总的来说,这篇文章还是诚意满满,虽然之前这种类似的优化方式也已经有了,比如之前一篇文章中利用item2vec来学习物品相似性来改进物品的隐向量,但这篇文章中作者还是对这种方法做了详细完整的描述,而后面给出了几何角度与概率图模型的分析也很干货满满,思路上还是很精彩的。