这篇文章是KDD2017的一篇文章,最近的Qcon上Airbnb还有人演讲这篇论文,这篇论文的主要思想就是用tables来代替tree的存储结构,进而达到提升效率的目的,据说可以达到1.5到6倍速度的提升。
模型的具体做法就是用table结构存储,主要有以下:
- features,对数据进行划分时,存储一次判断的特征
- cuts,对数据划分时,村粗判断的值
- 结果表,是一个二进制表,存储判断结果
- predictions,根据结果表的二进制结果转为十进制下表,存储结果,也就相当于叶子节点位置
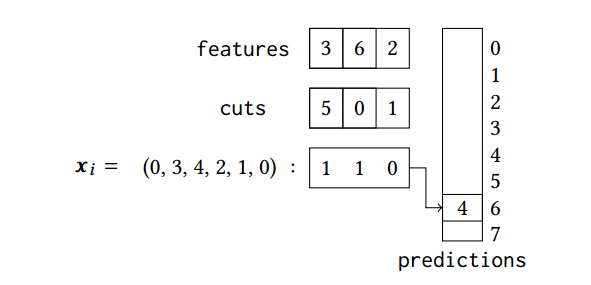
具体算法流程如下

先依次初始划分一次,然后进行n次pass,也就是backfitting,来re-split,提升效果,这里有一个迭代的思想,固定其他不变,重新划分其中某一个特征,然后以此重复,最后会收敛到最优解(真的会吗?论文中没给出证明,但很多算法都是这种思想,如坐标上升法、Gibbs采样等等),我看到这里觉得关键问题是n次backfitting的n怎么定,以及每次re-split的特征怎么选。
文章后面对选特征问题给了三种解决方法:
- cyclic backfitting,也就是全部依次迭代
- random backfitting, 随机选,随机迭代
- greedy backfitting,遍历一遍,选择最能降低方差的
感觉都是治标不治本的方案...文中提到问了避免过拟合所以一般选择\(n=1\) 。跟GBDT对比一下,GBDT是一种递归的方式,BDT是一种迭代的方式。
关于每次迭代时选择最优划分点,因为迭代划分点会更改最后分类,所以是计算最后的Gain来决定划分,Gain的计算公式与GBDT相似 \[ \begin{aligned} Gain(x_j,c)&=SE_{\mathcal{D}}-\sum_k(SE_{\mathcal{D}^L_k}+SE_{\mathcal{D}^R_k})\\ &=\sum_k(\frac{(\sum_{i\in\mathcal{I}_k^L}y_i)^2}{|\mathcal{I}_k^L|}+\frac{(\sum_{i\in\mathcal{I}_k^R}y_i)^2}{|\mathcal{I}_k^R|})-N\overline{y}^2 \end{aligned} \] 然后作者根据table的结构提出了快速的迭代计算的方式

后面还有如何快速更新ensemble后的BDT的结果

总体给我感觉这篇文章也是从数据存储计算格式的角度在工程上对GBDT做了优化提升,还是比较有意思的。