BPR这篇文章应该是近几年比较特别有意思的文章,有多想法的亮点,值得大家来细细品味。
这篇文章主要的contribution在于以下几点:
- 提出了一种通用的优化标准BRP-OPT,利用最大后验估计来优化个性化的排序,并且优化BRP-OPT的效果与优化AUC相似;
- 为了最大化BRP-OPT,提出了基于梯度下降和重采样的通用学习方法LearnBRP,并且可以较有效果;
- 能够将LearnBRP应用到当前比较流行的两种模型上;
- 能够取得较好的效果。
先对rank问题进行定义: \[ \forall i,j\in I:i\neq j\rightarrow i>_uj\vee j>_ui\\ \forall i,j\in I:i>_uj\wedge j>_ui\rightarrow i =j\\ \forall i,j,k\in I: i>_uj\wedge j>_uk\rightarrow i>_uk \] 分别定义了rank的完整性,非对称性和传递性,然后对于我们已经有的打分记录,我们认为用户有implicit feedback的物品的打分为1,而无交互或者missing value则定义为0,这样我们可以根据用户对打分进行排序比较,如下图所示
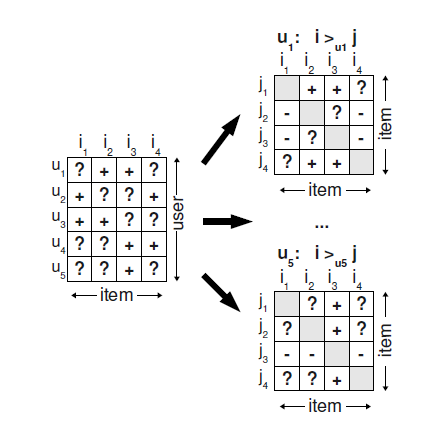
然后我们就可以来构建训练数据 \[ D_S=\{(u,i,j)|i\in I^+_u\wedge j\in I/ I^+_u\} \] 然后作者的初衷是优化rank的loss,即最大化后验概率 \[ p(\theta|>_u)\propto p(>_u|\theta)p(\theta) \] 参数\(\theta\) 的先验概率与似然的乘积,我们把似然写开 \[ \prod_{u\in U}p(>_u|\theta)=\prod_{(u,i,j)\in U\times I\times I}p(i>_uj|\theta)^{\mathbb{I}((u,i,j)\in D_S)}\cdot (1-p(i>_uj|\theta))^{\mathbb{I}(u,j,i)\notin D_S} \] 然后用sigmoid做概率的映射 \[ p(i>_u j|\theta)=\sigma(\hat{x}_{uij}(\theta)) \] 给参数\(\theta\) 一个零均值的正态分布先验,则我们的优化目标为 \[ \begin{aligned} \text{BPR-OPT}&=\ln p(\theta|>_u)\\ &=\ln p(>_u|\theta)p(\theta)\\ &=\sum_{(u,i,j)\in D_S}\ln\sigma(\hat{x}_{uij})-\lambda_\theta\|\theta\|^2 \end{aligned} \] 这样做可以认为是换了一种loss的AUC优化,具体解释见论文,很巧妙。
而BPR-Learning则是用BPR-OPT作为顶层loss,来优化底层的模型,比如说作为矩阵分解模型的loss,上层将gradient传下来后给下面进行参数迭代,看到这里不得不感叹一句,这个思想真是巧妙呀。作者结合当下几种主流的模型做了实验并进行了对比。
总的来说,这篇文章是少有的让人眼前一亮的文章,看着的确过瘾,而且思路清晰,形式巧妙,效果估计也很棒,恩,打算有时间自己实现一下了。