今天看nips2017的预选论文,翻到了4篇推荐相关的,其中3篇都是做cold start问题,看来这个问题最近很火热嘛,包括了RL和meta learning,看来有必要跟进一波潮流。再看其他的论文的时候,还翻到了微软的lightGBM,果断先捞出来看一下。
之前网上流传了许多关于lightGBM相关的内容,但是看到论文才是最实在的,文中提到相比于其它关于GBDT的实现,对于计算信息增益来划分节点的做法都还是太耗时间了,基本上都是\(\#feature\times\#data\) 的计算损耗,而基于柱状图(histograms-based)的方法则会相比更高效且节约内存,所以lightGBM也是从这个思路出发的。
BTW,文中的review部分包括了很多已有的其它GBM实现方法的回顾,都cite的是很经典的文章,如果想深入了解的话可以按照文中的review来看。
lightGBM主要从两方面来优化,feature数量和data数量,分别提出EFB(Exclusive Feature bundling)和GOSS(Gradient-based One-Side Sampling)进行分别的优化。
在划分时,gradient大的样本(instance)往往会对信息增益有较大的贡献,所以,我们用采样的方法,减小那些数量较多但是gradient较少对节点划分增益不大的样本的影响,首先根据绝对误差排序,选择top \(a\%\)的样本,然后从剩下的采样 \(b\%\),同时赋予不同的权重。后面作者做了理论分析,表示这么抽样不会改变训练数据分布,blabla(当然我是没看的)

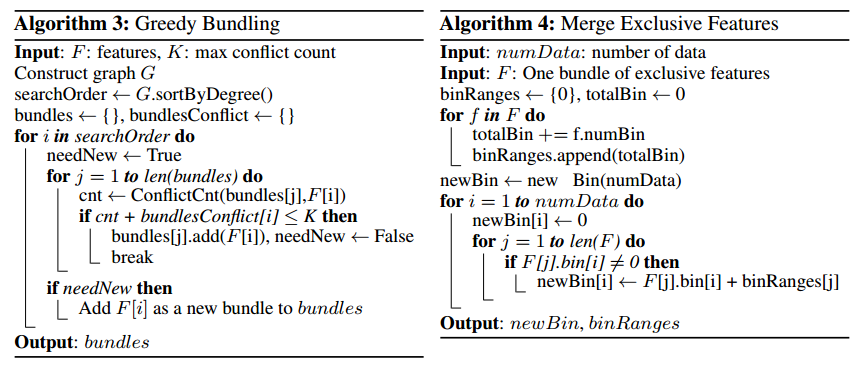
EFB则是解决特征的问题,训练数据往往会十分稀疏,如大量onehot产生的特征,而GBDT这样的算法,在面对节点划分时,不得不考虑所有特征,所以我们用bundling的方式来减少不必要的特征。因为是从histograms-based的想法出发,EFB实际上也是再用划分“桶”(如LSH)这样的方法,减少特征量。具体做法是利用图的着色问题,用特征构造图的矩阵,然后根据着色来划分,如果两个特征不是mutually exclusive,则它们之间存在边。(具体操作此处没看太明白,着色问题我也没看过,留个坑)对于一个bundling的feature,则改变feature的取值区间来merge不同的feature。
后面是文章的实验部分,效果还是很好的,看微软的论文,就给我一种哪有问题我就干掉哪的感觉,而且是工程化很强的东西,包括之前的lightLDA,现在lightGBM,都是非常厉害。