看懂这几篇需要一些RL方面的基础知识,之后并不会涉及一些基础内容的讲解。
Playing Atari with Deep Reinforcement Learning
这篇是DQN的开山之作,先看这篇也是因为nature上那篇画的太乱了。
开篇作者先点出将DL应用在RL上的几个挑战: - 大多数深度学习的应用都需要大量的标注训练数据,而增强学习算法往往是从一串序列数据的反馈中学习,而这个反馈信号往往是稀疏的(很少才会有)、充满噪音的、延迟的(很多步之后才会得到反馈)。 - 大部分深度学习算法都是假设训练样本是独立同分布的,而增强学习用到的数据都是序列数据,样本之间高度相关。
作者面对以上几个问题提出了解决方案,用经验回放机制来克服这些问题(experience replay mechanism),将训练样本放入记忆库,然后通过随机采样的方式抽出来训练样本,计算梯度更新权重,这样就可以避免样本之间的联系。
关于Q-learning的更新,熟悉RL的同学肯定都了解Bellman Equation \[ Q^*(s,a)=\mathbb{E}_{s'\sim \mathcal{E}}[r+\gamma\underset{a'}{\max}Q^*(s',a')|s,a] \] 所以我们可以根据这个定义损失函数 \[ L_i(\theta_i)=\mathbb{E}_{s,a\sim\rho(\cdot)}[(y_i-Q(s,a;\theta_i))^2] \] 所以梯度也就出来了 \[ \nabla_{\theta_i}L_i(\theta_i)=\mathbb{E}_{s,a\sim\rho(\cdot);s'\sim\mathcal{E}}[(r+\gamma\underset{a'}{\max}Q(s',a';\theta_{i-1}-Q(S,a;\theta_i))\nabla_{\theta_i}Q(s,a;\theta_i)] \]
之前前人们也想过用类似的网络来做value function的近似,也就是NFQ的思路(Neural Fitted Q-learning),可是NFQ采用batch来训练网络,会有很大的计算开销,DQN用SGD的方式训练,减少了训练开销同时也可以用于大规模数据集。同时NFQ用AE做特征提取,来表示状态,而DQN是一种E2E的学习方式,直接学习高阶表征。
DQN的算法如下 
简单解释一下,这里的\(\phi\)就表示的是Q-learning的value function近似网络。一共训练M个episode,每个episode迭代T步,每步中,用当前网络对序列的每个状态产生最优值,做成训练样本放入记忆库,同时从记忆库中随机抽取样本,进行网络的迭代,可以说,一边学习一边产生新样本,又用随机采样训练的方式减少样本前后联系的影响,更新网络后,又会影响新加入记忆库的样本,从而越学越好。
文章后面就是介绍网络具体结构和实验部分了。
Human-level control through deep reinforcement learning
这篇其实跟刚才那篇是一篇,但这篇投稿的是nature,所以只能把一些基础杂七杂八的东西写生去了,看着就很烦了。不过这盘文章里的图倒都是很漂亮。
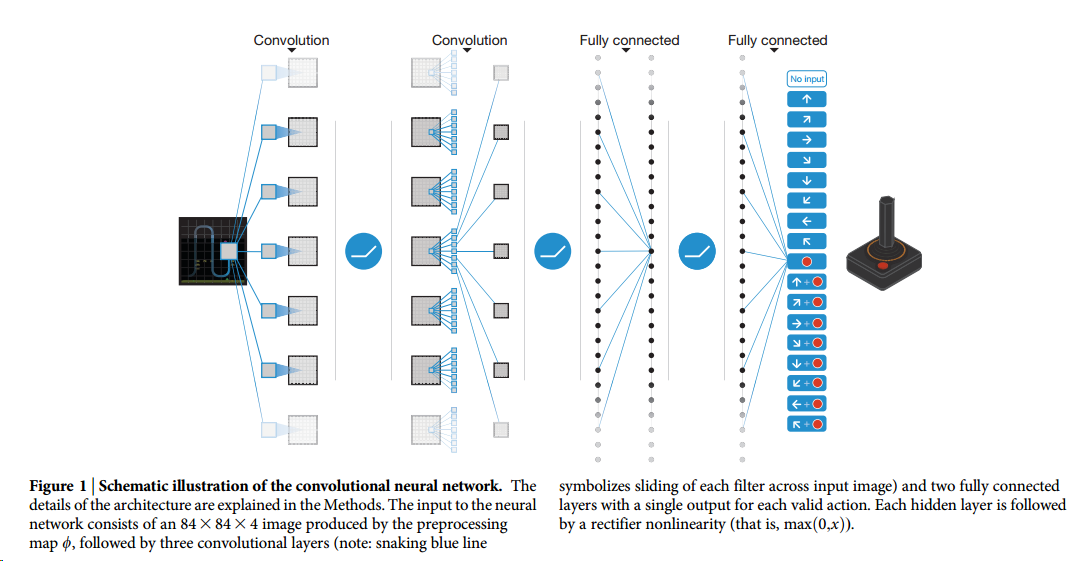
仔细翻了一下,真的什么额外内容都没讲,心塞塞。