换口味continue。
这篇文章是19年的Managment Science上的文章,主要是做市场营精准用户营销的,文章中提到了一个2阶段的实验以及使用一些机器学习方法来更高效的做营销活动分发,里面的实验建模方法、问题分析的思路和方法跟我们当前所做的工作(滴滴价格引擎)都十分相像,某种程度上说,这些也是我们团队在过去两年中,实打实踩出的“best practice”,所以拿出来写一下。
因为是MS上的文章,技术层面的东西会少一点,更多的是关注于问题建模、数据分析上,所以我并不打算纯叙述性地写下来,只会串文章整体思路以及分析的亮点,大家有时间就去看看原文。
当公司期望获得新客时,公司需要决策哪些用户群体是你的目标用户,以及对于他们做什么样的营销活动。一个标准的方式是先做一轮小规模的实验来观测不同营销活动的影响,然后利用这些数据来制定营销策略,辨识哪些用户适合哪种营销活动,然后在一个更大规模用户群体上去实践。营销策略(给谁发,发哪种营销活动)的效果会依赖于训练数据的质量以及具体建模方式,本文中评估了几种建模方式,并对效果进行了分析。
我们的评估分析依赖于一个两阶段的实验,营销策略用第一阶段实验(pilot experiment)上收集的数据进行训练,在第二阶段的实验上进行验证。
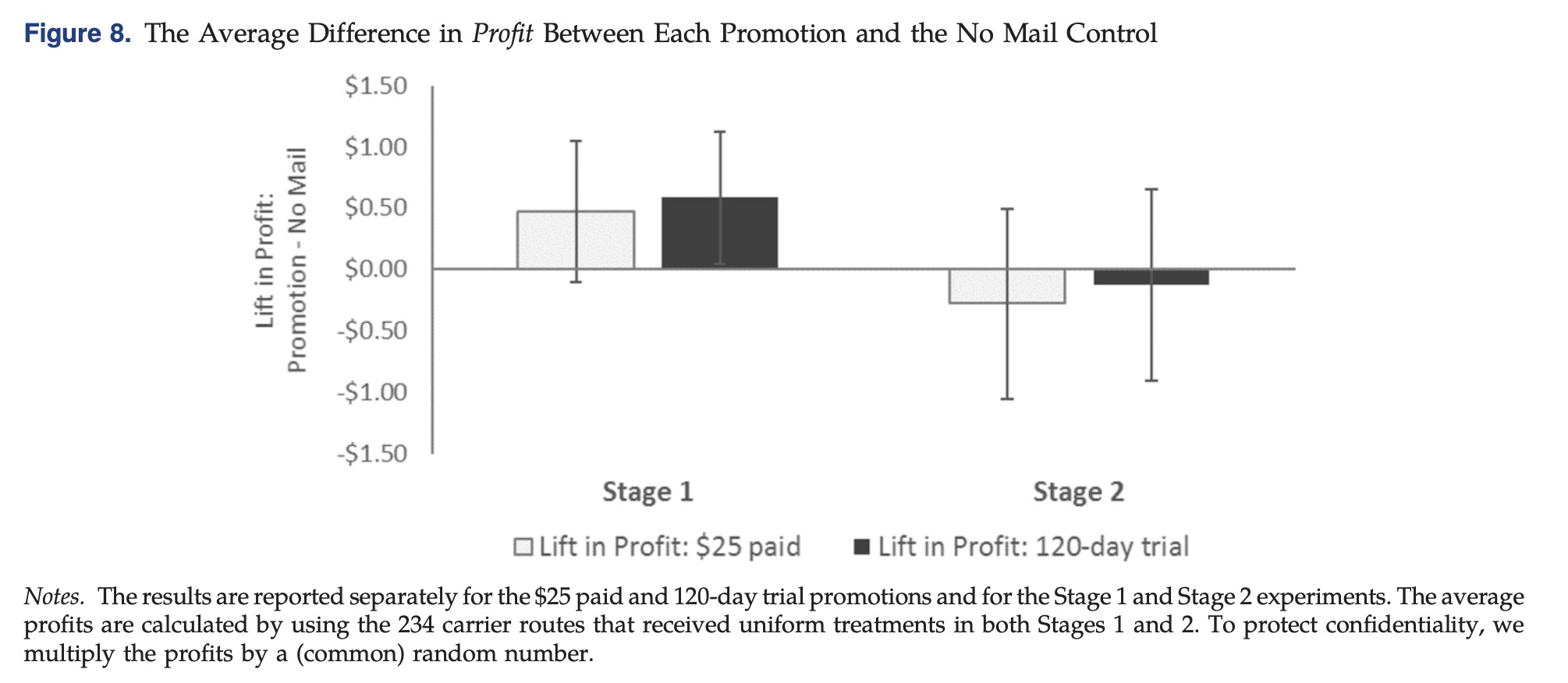
这次实验的数据由美国的一个大的零售商提供,用户只能通过购买会员才能购物。这家零售商会定期通过邮件发放一些促销活动来增加会员数量,包括25美元12个月的付费会员以及一个120天的免费尝试,如果后续还想继续购物则需要全价购买会员。
对于第一阶段的实验,包含一百万的住户,这些住户分布在两个地理行政区,然后对这些住户随机进行分组3组:发25美元一年会员,发120天免费试用和不发邮件。第一阶段的时候在2015年2月开始,一直到3月底。
待评估的方法以及分类:
在阶段二除了以上七种外,还额外留了均匀发放的两组和完全不发的一组作为对照组以及用于评估分析,整体覆盖四百万用户。
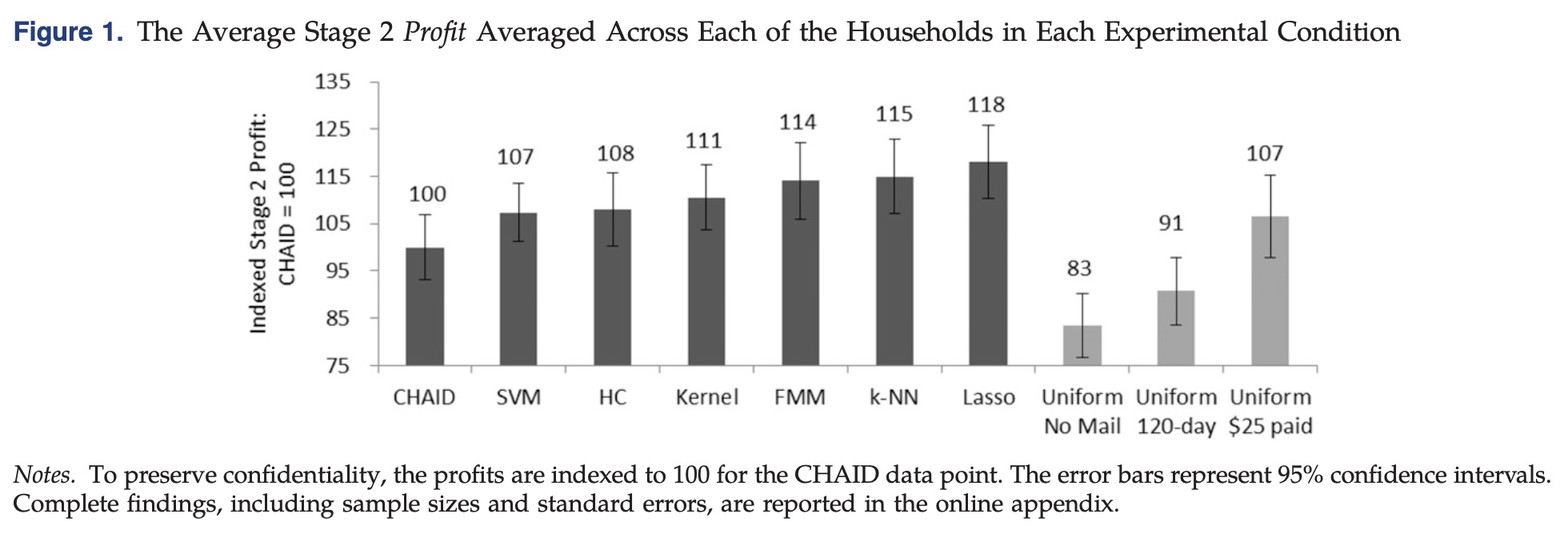
直观的看,25美元一年的营销策略会更有效,但是Lasso推荐的的策略实现了更高的利润,这是因为对于Lasso而言,找出了适合发120天试用以及不发的人群,我们利用Lasso在全量下发的人群上预测
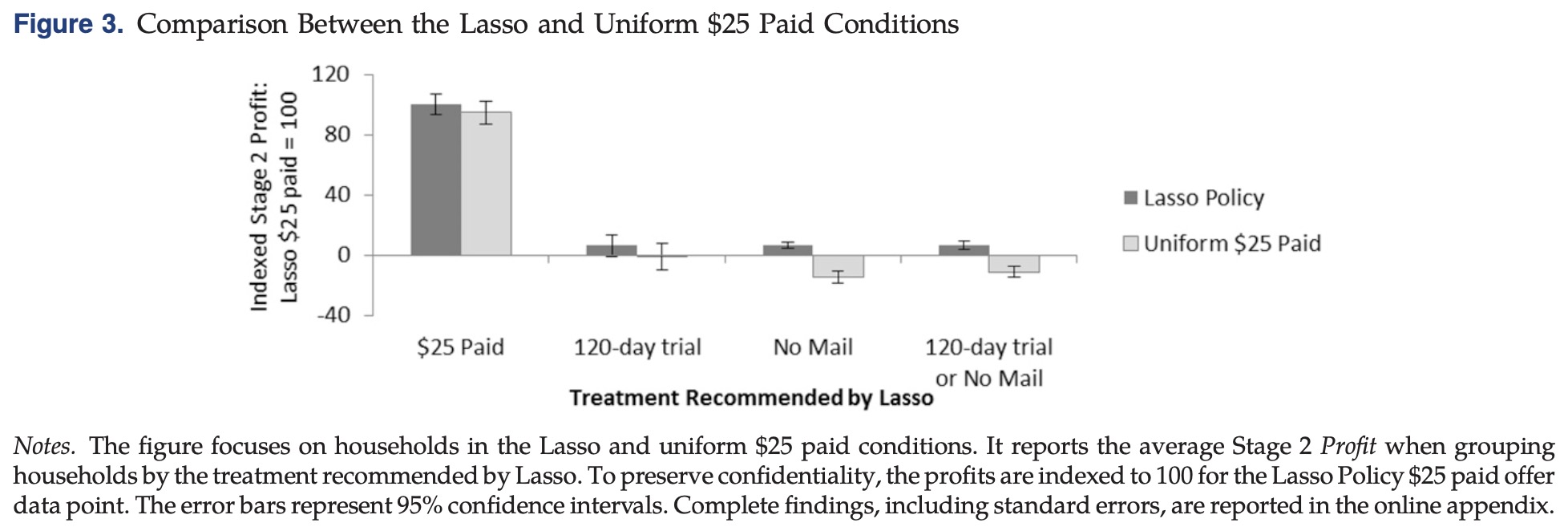
可以看到,Lasso推荐发别的活动的人群,在Lasso觉得不应该下发的人群上有效的节约了成本,因为这群人发放活动会有负向收益。
通过对结果进行分析,我们罗列了四种对结果产生影响的原因:
- covariate
shift,训练集和实际线上使用的数据分布不一致,由于第一阶段实验是一个小规模的用户群体上进行,在第二阶段大规模应用时,会发生与第一阶段实验人群分布不一致的情况
 ,为了辨识哪些变量发生了改变,采用MMD来检测两个分布是否一致,同时用实验组的变量分布来构建区间,对于超出正常范围的样本,各个方法上效果都比较差
,为了辨识哪些变量发生了改变,采用MMD来检测两个分布是否一致,同时用实验组的变量分布来构建区间,对于超出正常范围的样本,各个方法上效果都比较差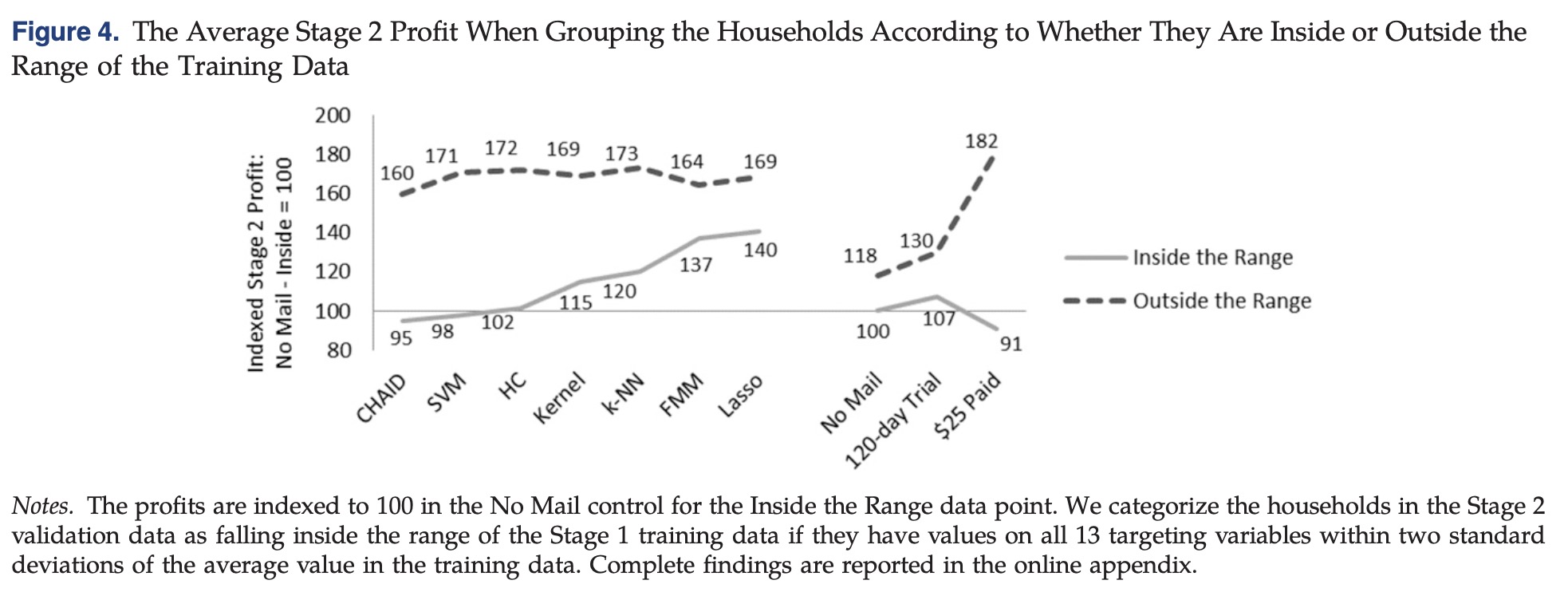 ,同时对于数据分布偏易程度不同,不同类别模型表现效果也是有差异的
,同时对于数据分布偏易程度不同,不同类别模型表现效果也是有差异的
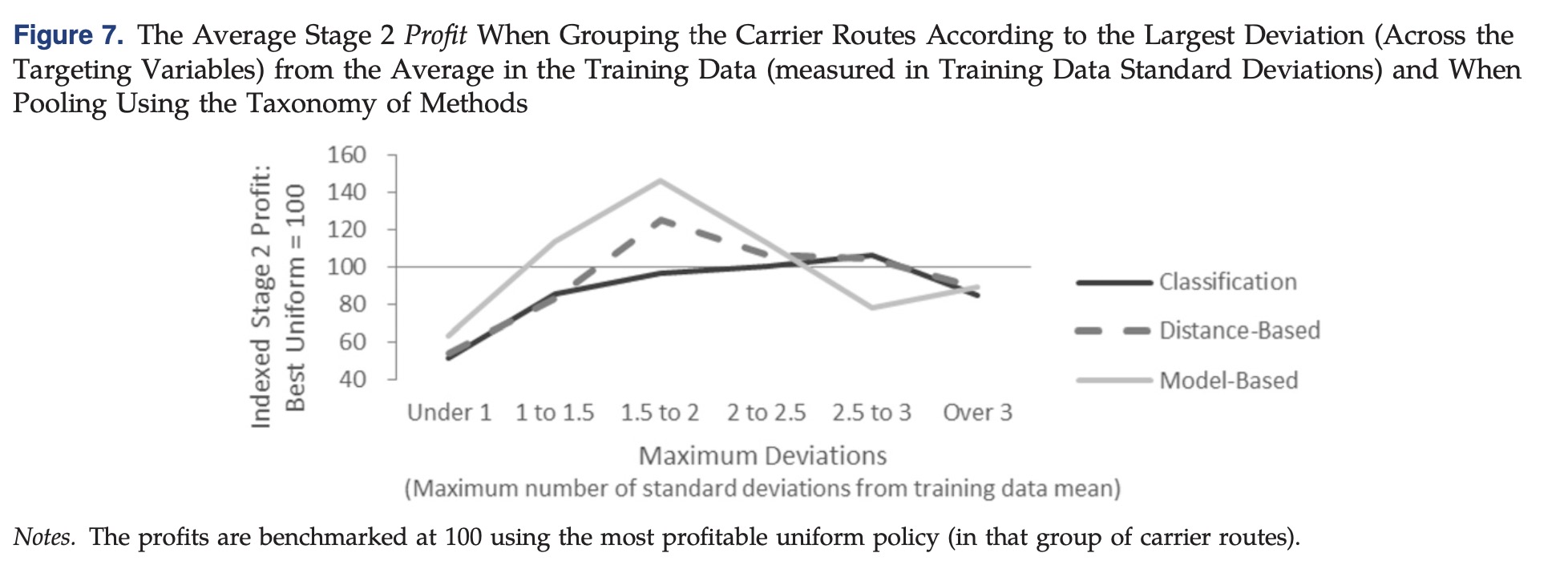
- concept
shift,相同数据分布时候,潜在的函数关系发生改变,导致这个情况的原因可能是时间周期上的变化(第一季度做实验一,应用于二三四季度)、竞争对手的营销活动或者是一些其他商业环境上的改变。为了证明存在这个现象,先比较了相同的数据上在不同阶段实验上结果的变化
 ,其次提出了一个度量潜在函数变化的指标
,其次提出了一个度量潜在函数变化的指标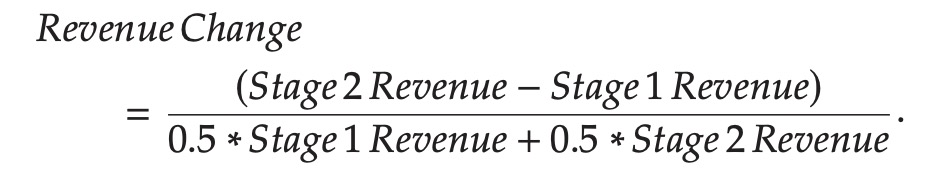
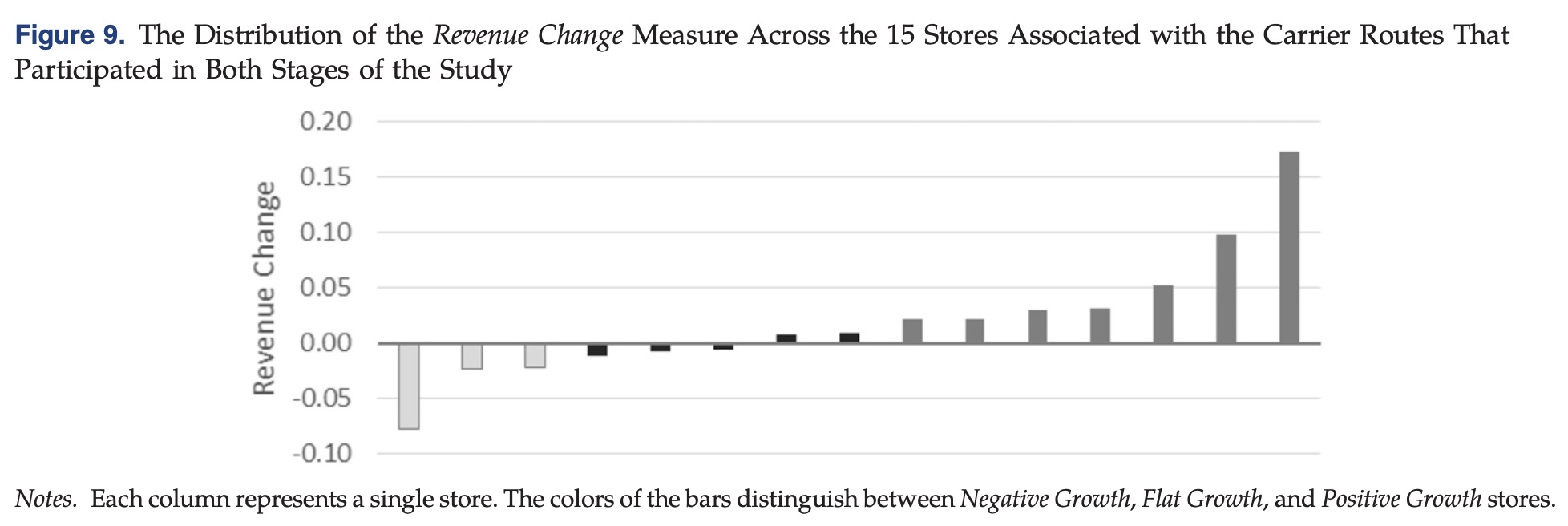

- information loss through aggregation,因为公司只能使用过去的购买历史数据来进行预测,所以会需要对下发决策做一定粒度的聚合,但随着聚合维度的增加,会丢失一些个性化信息,导致模型预测能力的下降。
- imbalance data,会存在一些新客,新客会缺少历史数据,这就使得对于新客多的场景预测值不准。
除了上述几个简单的模型,同样尝试了几种更为复杂的机器学习模型,利用第二阶段的随机分发数据进行评估
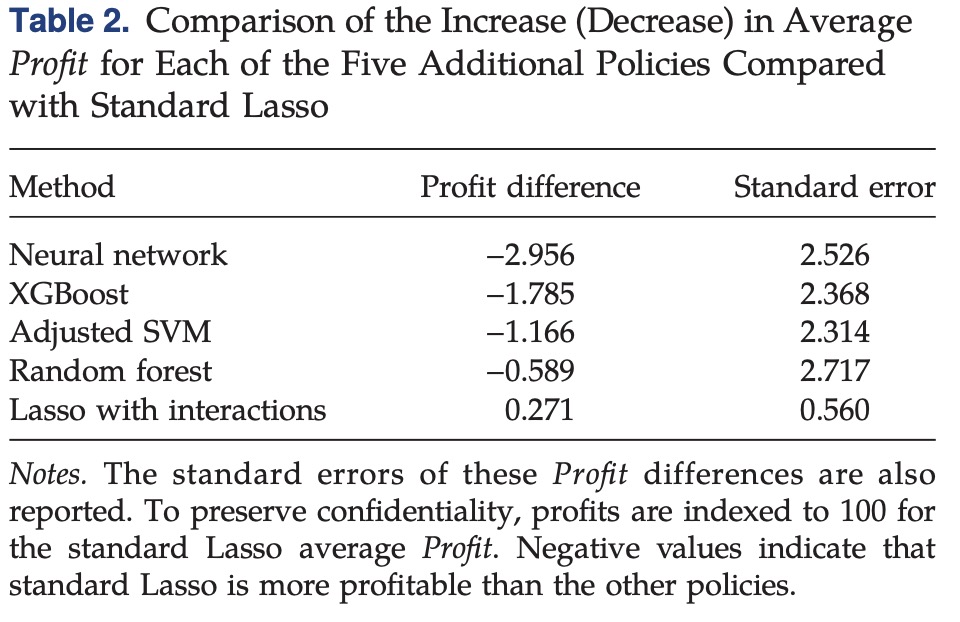
上面是这篇文章的主要内容,有很多细节的分析我没有写,大家有时间可以看看原文,谈几点和我们的工作的相似点吧:
- “2阶段”的实验,在这类营销活动圈选人群的业务场景上,这种方式应该算是一个最佳实践,通过一个无偏策略(uniform policy)的数据得到的模型才会有更好的效果
- 关注对照组,关注不同对照组数据分布以及结果,同时应该在这种天然的“反事实”数据上评估模型
- 对于covariate shift和concept shift的分析方法和思路适用于大部分场景,大部分营销活动分发场景都会出现这样的状况,做Stable Learning或者Causal Inference可以尽量提高模型对于这两个问题的鲁棒性