这篇文章是criteo ai lab发表在KDD2021上的一篇文章,文中的一些idea非常棒,同时跟我最近手头上做的事情比较像,拿出来详细写一下。
Introduction
关于竞价广告的背景就不在这里啰嗦了。。
竞价策略会依赖于展示广告的价值,这个价值一般需要用机器学习算法进行预测,这篇文章主要讨论一个广告是否需要重复、多次展示给一个用户。对于一个状态为\(x_t\)的用户,一次展示\(D_t=1\)的价值为CPA(Cost per Action)与被归因到这次展示的目标事件(target event)的期望次数\(S_t\)的乘积 \[ \text{CPA} \cdot \mathbb{E}(S_t|X_t=x_t, D_t=1) \] 目标事件\(S_t\)一般是用户在点击了这次展示广告之后的购买。但是当一个用户已经多次点击了广告,所有的贡献都会归因于这些展示广告中的一个,一般来说都是购买前的最后一次点击。这样做的结果是,序列中的单次展示会被标记为\(S_t=1\)或\(S_t=0\),这样学到的模型可能是无效的。我们认为任意的归因的做法是次优的,并提出了一种用期望目标事件增量的\(\Delta S\)来衡量展示价值的方法,我们引入因子\(\alpha(x_t)\)和展示\(D_t\)未来一段时间内产生购买\(S\)的概率,展示价值变为 \[ \text{CPA}\cdot \alpha(x_t) \cdot \mathbb{E}(S|X=x_t, D_t=1) \] 我们假设,如果展示\(D_t\)没有被点击则不会影响未来发生购买的概率,我们估计因子\(\alpha(x_t)\)为展示\(D_t\)被点击\(C_t=1\)和\(C_t=0\)时,期望购买数量的条件概率 \[ \alpha(x_t)=1-\frac{\mathbb{E}(S|C_t=0, X_t=x_t, D_t=1)}{\mathbb{E}(S|C_t=1, X_t=x_t, D_t=1)} \] 当销量完全是增量的时候,因子值为1,当点击不会产生增量的时候,因子值为0。
本文的contribution主要有:
- 对竞价的问题进行陈述,阐述了贪心形式的缺点,并且阐述了为什么最大化收益,竞价需要考虑期望销售的增量,而不是只是归因于这次展示的销量
- 建模点击的因果效应,介绍了一个新的模型来估计展示广告的价值,这个模型是基于点击对于销售的因果效应模型
- 提出了一个度量增量的指标,提出了一个新的指标来评估模型对于销售增量预估能力的好坏。
- 离线、在线实验结果。
The Bidding Problem
Mathematical formulation
当一个用户浏览时,他会在页面上看到广告展示位,每个广告位都会有一次竞价,广告主会投标来购买这次展示机会,最高的竞价将会获得这次展示机会。对于一次竞价,一个用户的竞价的序列定义为一个随机过程,在每一步时间\(t\):
- 竞价者收到一个竞价请求,包含用户的状态\(X_t\)和一些相关信息
- 竞价者给予这次广告展示价值产出价格\(b_t\)
- 二元变量\(D_t\)会告诉竞买者这次广告是否会被展示,如果展示了会产生成本\(\text{Cost}_t\),不展示则不会产生花费
- 如果竞价者获胜,之后会观测到点击情况\(C_t\)
在整个序列中,有可能会发生多次购买,在序列结束后,广告主会决定哪些销量时由于这次竞价产生的,竞价者观测到归因的销售量\(S\),得到\(S\cdot \text{CPA}\)的收益,其中\(\text{CPA}\)是一个常量,定义了被归因的销量。竞价者会选择一个竞价策略\(\pi\),来根据用户状态产生竞价,期望最大化收益为 \[ \mathbb{E}\bigg[ S\cdot \text{CPA} -\sum_{t\in\text{sequence}} \text{Cost}_t \bigg] \]
Assumptions
此处做一些假设:
- Fully observable MDP:状态\(X_t\)都是可观测的,\((X_t,b_t)\)序列构成MDP
- Independent users:用户间相互独立
- Bid impacts future only through the display:竞价只通过展示状态影响未来结果
上述前两个假设,这个问题变成了一个强化学习问题,每个用户都是一个序列决策过程,连续的动作是竞价\(b_t\),每一步的奖励是\(-\text{Cost}_t\),序列最终的奖励是\(S\cdot \text{CPA}\)。
注意到成本\(\text{Cost}_t\)和展示状态\(D_t\)依赖于竞价,第三个假设表明了竞价者和环境在观测到展示状态\(D_t\)后都不会在意\(t\)时刻的竞价\(b_t\)和成本\(\text{Cost}_t\),所以\((X_t,D_t)\)构成了MDP,因果图如下:
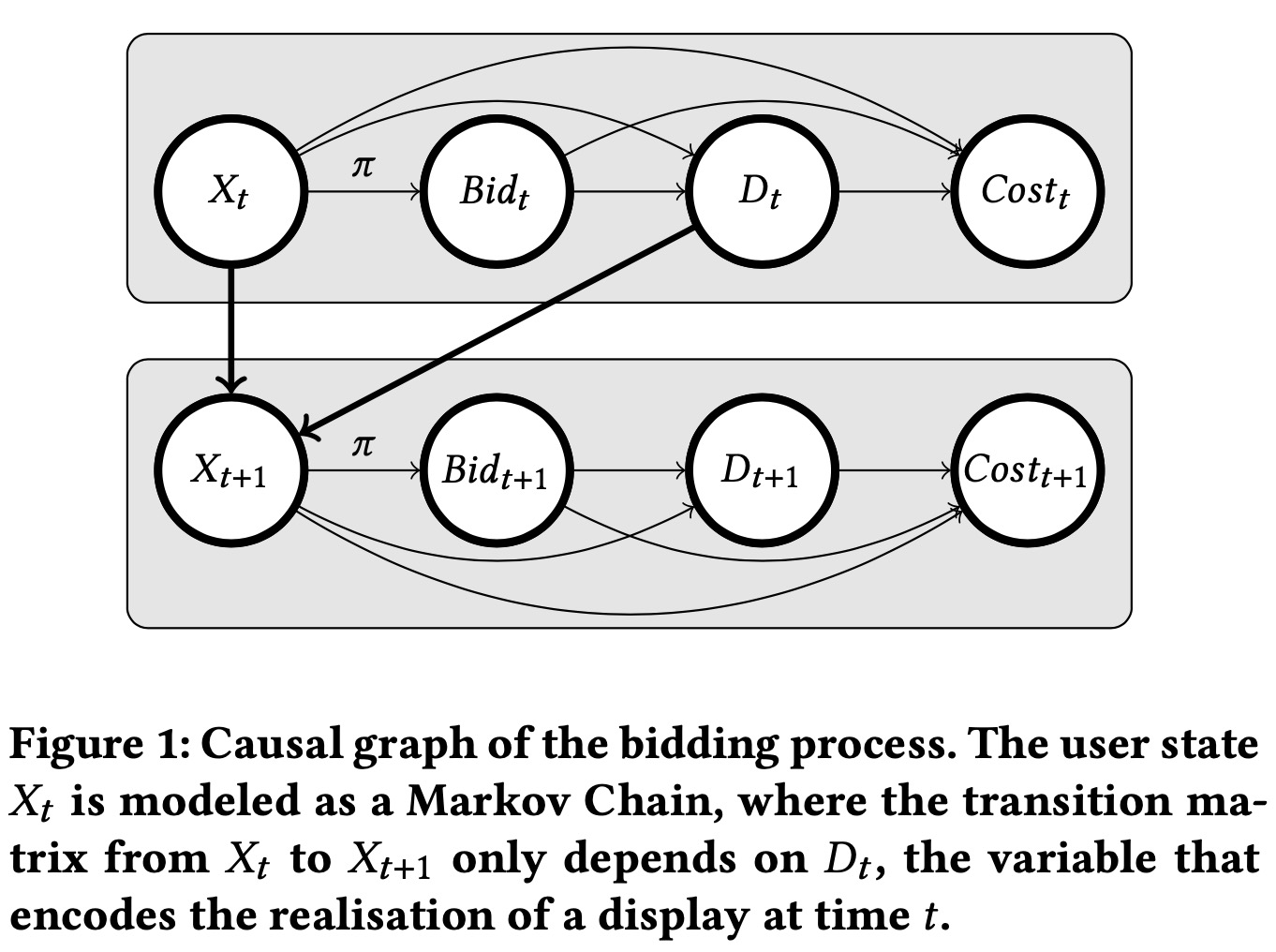
这些假设在实际中可能会不满足,比如:
- 竞争者对于用户会有一些私人信息,因为展示成功率和最终销量都会依赖这些私人信息,导致假设1不符合
- 如果一个竞价者在\(t\)时刻计算出之后的竞价,或者依赖于当此成本\(\text{Cost}_t\),会导致假设3不满足
尽管会有这些问题,但我们相信这些假设都足够合理。
Shortcomings of the greedy policy
像之前所讨论的,广告主会用一些简单的规则对销量做归因,比如说归因到这个用户最后一次的点击。在这样的规则下,可以用序列最后的销量来替代序列中每个时刻的销量\(S_t\),我们定义\(S=\sum_tS_t\),同时我们的目标依然是最大化\(\text{CPA}\cdot S-\sum_t\text{Cost}_t\)。
我们定义一个贪婪的竞价者是最大化每个时刻下的期望回报,\(\mathbb{E}[\text{CPA}\cdot S_t-\text{Cost}_t]\),由于归因规则并不完美,比如说归因到最后一个点击上,导致这样做对于整个序列来说并不是最优的,比如第一次的展示足够产生购买行为,但是如果我们在归因前就进行了第二次展示(竞价购买展示机会),这次额外的展示并没有带来价值但却增加了成本。
Optimal policy
接下来我们推到一个最优的竞价,在时刻\(\tau\),假设竞价者将会沿用既定策略\(\pi\),我们定义未来的成本\(\text{FCost}_t=\sum_{t>\tau}\text{Cost}_t\),期望收益是 \[ \Delta S(x_\tau)=\mathbb{E}[S|X_\tau=x_\tau,D_\tau=1]-\mathbb{E}[S|X_\tau=x_\tau,D_\tau=0] \] 成本是 \[ \Delta \text{FCost}(x_\tau)=\mathbb{E}[\text{FCost}_\tau|X_\tau=x_\tau,D_\tau=1]-\mathbb{E}[\text{FCost}_\tau|X_\tau=x_\tau,D_\tau=0] \] 根据之前的假设,我们可以推出最优的策略为 \[ b^*_\tau=\underset{b}{\arg\min}\mathbb{E}\big[ D_\tau \cdot(V(x_\tau)-\text{Cost}_\tau)|\text{Bid}_t=b \big] \] 其中展示的价值定义为 \[ V(x_\tau)=\text{CPA}\cdot \Delta S(x_\tau)-\Delta \text{FCost}_\tau \]
Modeling The Causal Effect of Clicks
根据上面的推导,我们需要估计单次展示对于额外归因销量\(\Delta S(X_\tau)\)和未来的成本\(\Delta \text{FCost}(X_\tau)\),本文中,我们提出了一个新的方法,通过利用随机的点击来估计\(\Delta S(X_t)\)的方法。因为我们相信,贪婪竞价低效最大的原因就是直接将销量归因于最后一次点击,在本文中我们将关注于\(\Delta S(X_\tau)\),\(\Delta \text{FCost}(X_\tau)\)近似为0。
在本章节,我们为了简化先去掉下标\(t\),用\(D\)和\(C\)表示事件\(D=1\)和\(C=1\),用\(\overline{D}\)和\(\overline{C}\)表示\(D=0\)和\(C=0\),假设\(S\)也是二元变量,因此有 \[ \Delta S(x)=\mathbb{P}(S|X=x,D)-\mathbb{P}(S|X=x,\overline{D}) \] 可以立即为展示对于归因销量的因果效应。因为产生销量十分稀疏,所以我们并不能直接拟合模型\(\mathbb{P}(S|X=x,D)\)。
Assumptions
大部分归因系统一个很常见的假设是如果没发生展示的点击,不会对销量产生影响,这很大程度上缩小了需要考虑的展示的数量。
假设4,No Post Display Effect:下图展示了整个过程的因果图,\(C_t\) block了所有从\(D_t\)到\(S\)的路径。
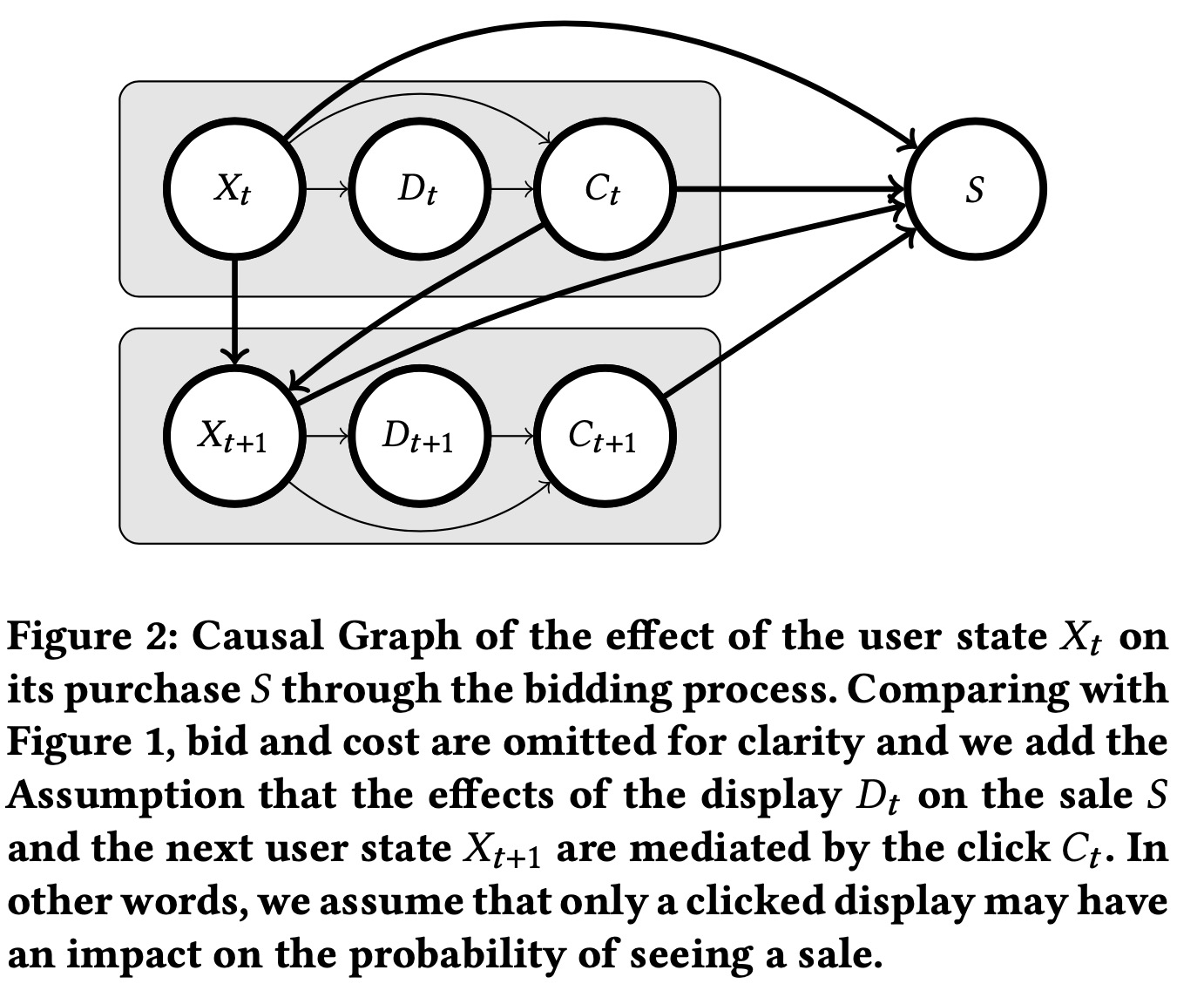
换句话说,展示只能通过点击造成一个销量 \[ \mathbb{P}(S|X=x,\overline{D}) = \mathbb{P}(S|X=x,\overline{D},\overline{C}) = \mathbb{P}(S|X=x,D,\overline{C}) \] 第一个等式是因为点击不可能在没有展示的情况下发生,第二个等式是因为d-separation,因为\(D\)只通过\(C\)影响S。
The incremental bidder
\[ \begin{aligned} &\mathbb{P}(S|D,X=x) \\ &\quad = \mathbb{P}(S|C,D,X=x)\cdot \mathbb{P}(C|D,X=x) + \mathbb{P}(S|\overline{C},D,X=x)\cdot \mathbb{P}(\overline{C}|D,X=x)\\ &\quad = \mathbb{P}(C|D,X=x) \cdot \Big( \mathbb{P}(S|C,D,X=x) - \mathbb{P}(S|\overline{C},D,X=x) \Big) + \mathbb{P}(S|\overline{C},D,X=x) \end{aligned} \]
所以有 $$ \[\begin{aligned} &\Delta S(x) \\ &\quad = \mathbb{P}(S|C,D,X=x)\cdot\Big( \mathbb{P}(S|C,D,X=x) - \mathbb{P}(S|\overline{C},D,X=x) \Big) \\ &\quad\quad+ \Big( \mathbb{P}(S|\overline{C},D,X=x) - \mathbb{P}(S|\overline{D},X=x) \Big) \end{aligned}\]\[ 根据我们之前的假设,最后一项$\mathbb{P}(S|\overline{C},D,X=x) - \mathbb{P}(S|\overline{D},X=x)$,可以理解为展示后的长期影响,在我们假设中为0。因此 \] S(x) = (S|C,D,X=x)( (S|C,D,X=x) - (S|,D,X=x) ) \[ 所有的项都可以直接从数据中估计得到。如果$ \mathbb{P}(S|C,D,X=x)>0$,我们有 \] S(x) = (S|C,D,X=x)(S|C,D,X=x)( 1 - ) $$ 我们称最后一项为“增量因子”。这一项处于0到1之间,当等于1的时候,说明这次展示造成的销量是纯增量,如果是0,就说明这次展示不会对未来的销量有增量。
An Incrementality Metric
我们想度量增加额外的展示,在未来会不会产生额外的销量,我们像评估我们的模型对于\(\Delta S(x)\)预估的好坏,\(\Delta S(x)\)可以分成两部分,第一部分\(\mathbb{P}(C|D,X=x)\)是一个常见的分类模型,第二项$ (S|C,D,X=x) - (S|,D,X=x)$,因为我们无法观测到点击展示的反事实,所以离线评估这个模型的表现非常困难。
为了解决这个问题,我们引入一个变量\(Y\),有 $$ (Y|C,D,X=x) = (S|C,D,X=x) - (S|,D,X=x)
$$ 虽然我们无法观测,但是我们构建了一个评估指标,能够在只知道\(C\)和\(S\)的情况下评估我们模型对于\(Y\)的预测能力。
The generative model
此处我们只关心展示后点击以及销量的情况,我们分成4个类别\(T\in\{a,n,y,d\}\)
- 展示一定会(always)带来销量,不管点不点,\(T=a\)
- 展示一定不会(never)带来销量,不管点不点,\(T=n\)
- 展示只有在点击时候才会带来销量(incremental),\(T=y\)
- 展示只有在点击时候才不会带来销量(decremental),\(T=d\)
假设5,No decremental displays:\(\mathbb{P}(S|C,X=x)\geq\mathbb{P}(S|\overline{C},X=x)\)
这个假设表明不会有负向的展示(即增量因子是正数),所以\(T\in\{a,n,y\}\),其关系如下图所示
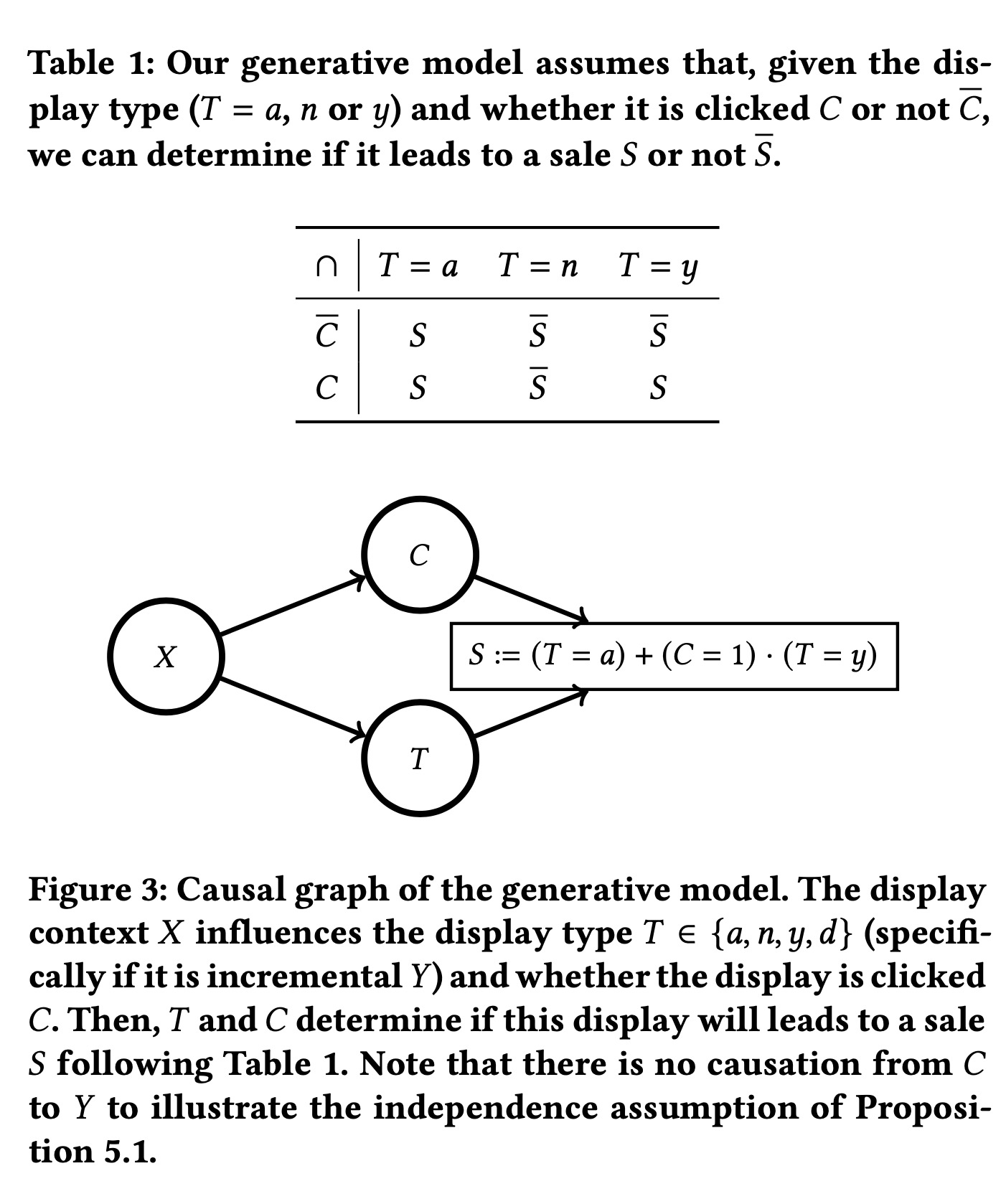
因为我们想找到增量,所以\(T=y\)是我们所关心的,我们定义\(Y\)为\(T=y\),\(\overline{Y}\)为\(T\neq y\)。
Reverted incremental likelihood
\(Y\)为一个二项分布变量,我们希望找到一个函数\(f\)预测\(Y\),似然函数为 \[ \text{LLH}_B(Y,f(X))=Y\log f(X)+\overline{Y} \log(1-f(x)) \] 因为我们无法观测到\(Y\),所以我们并不能直接计算似然。下式提供了,给定\(C\)和\(S\)时,上述似然函数的一个无偏估计[Jaskowski and Jaroszewicz, 2012] \[ \text{RLLH}_B(C,S,f(X))=\frac{C}{\mathbb{P}(C|X)}\text{LLH}_B(S,f(X)) + \frac{\overline{C}\cap S}{\mathbb{P}(\overline{C}|X)}\log \frac{1-f(X)}{f(X)} \] 如果能有一个正确的\(\mathbb{P}(C|X)\),我们就可以从数据中估计增量似然,这使得我们可以离线评估增量模型的好坏。一个模型的评估依赖于另一个模型并不是一个理想的做法,但是实际中点击预估模型非常常见,同时用大量的数据进行训练,所以我们可以安全使用它来评估销量预测模型。
Experimental Results
Offline analysis
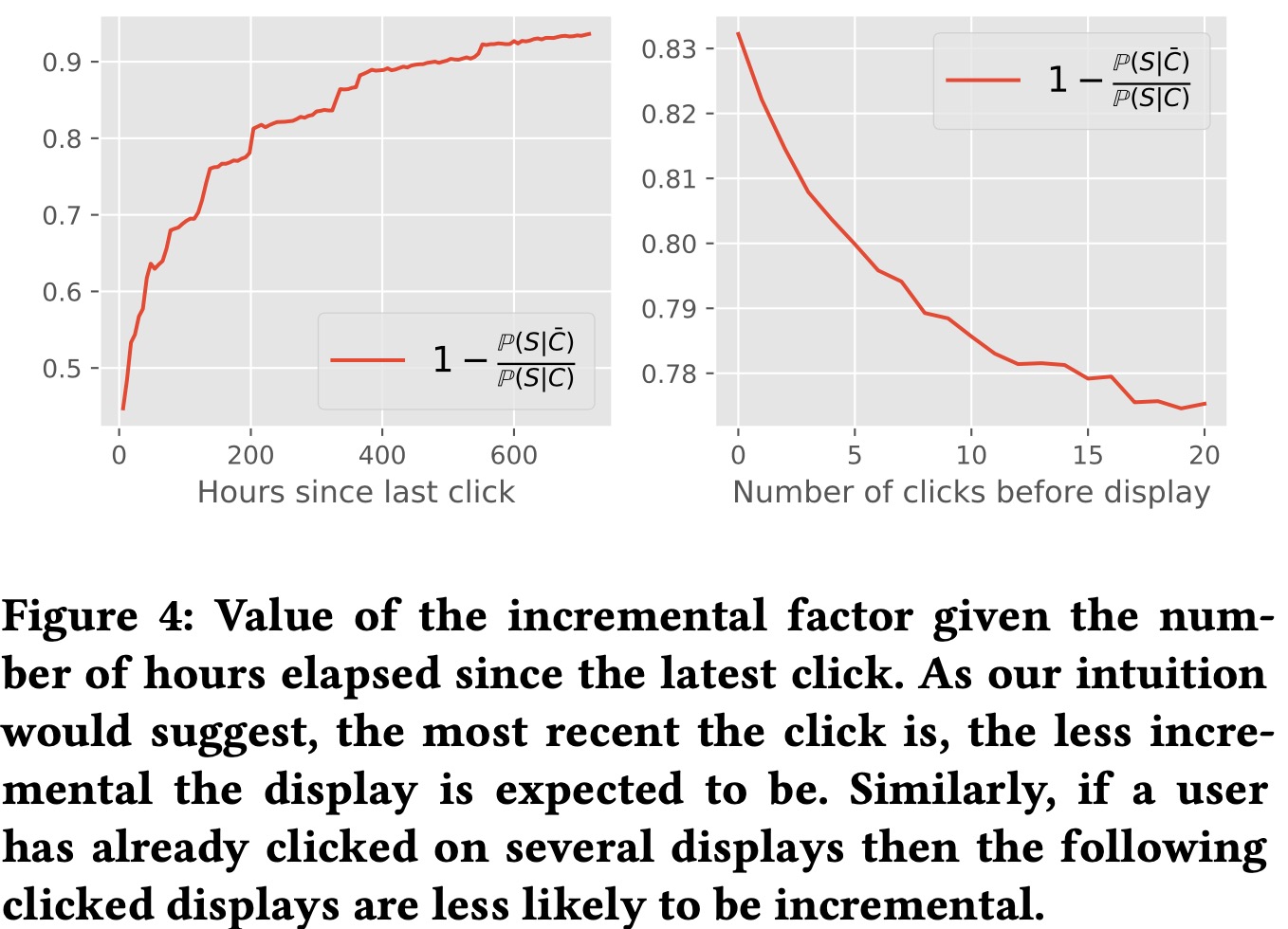
左图表现了随着上次点击时间增加,增量因子是递增的,右图说明了展示次数的增加,增量因子递减,这些预测的表现都是符合我们的预期的。