TL;DR
本文是LinkedIn的模型团队模型迭代“年终汇报”,包含LinkedIn团队对于各类模型涨点的技巧的实践。
摘要
We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improve- ments, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods.
To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quanti- zation and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction.
We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
LiRank 是 LinkedIn 的排序框架,将SOTA的建模架构和优化方法应用于线上生产环境中。本文中我们展示了LiRank中用到的一些模型优化方法,包括在DCNv2 中添加注意力和残差连接,分享了一些将SOTA架构落地的见解,包括Dense Gating、Transformer 和 Residual DCN,展示了一下在校准上的新技术,以及我们如何将 Deep Learing 在 Explore&Exploit 方向上进行落地的方案。
为了提供 高效、产品化的排序服务,我们详细描述了如何训练模型,并通过量化和词表压缩的方式来压缩模型,并将排序模型应用于Feeds、Job Recoomendation、和广告CTR预估。
最后我们总结了各类优化方法在AB实验中的经验,这些方法对LinkedIn各个场景的关键指标都有所贡献,Feeds场景中session member+0.5%,Jobs Serach和Recommendation场景中职位申请合格数 +1.76%,,广告点击率+4.3%。我们希望这些工作可以为相关从业人员提供实用的见解和解决方案。
正文
Large Ranking Models
Linkedin用排序模型的场景主要是Feeds的排序和广告的CTR预估。
Feeds Ranking Models
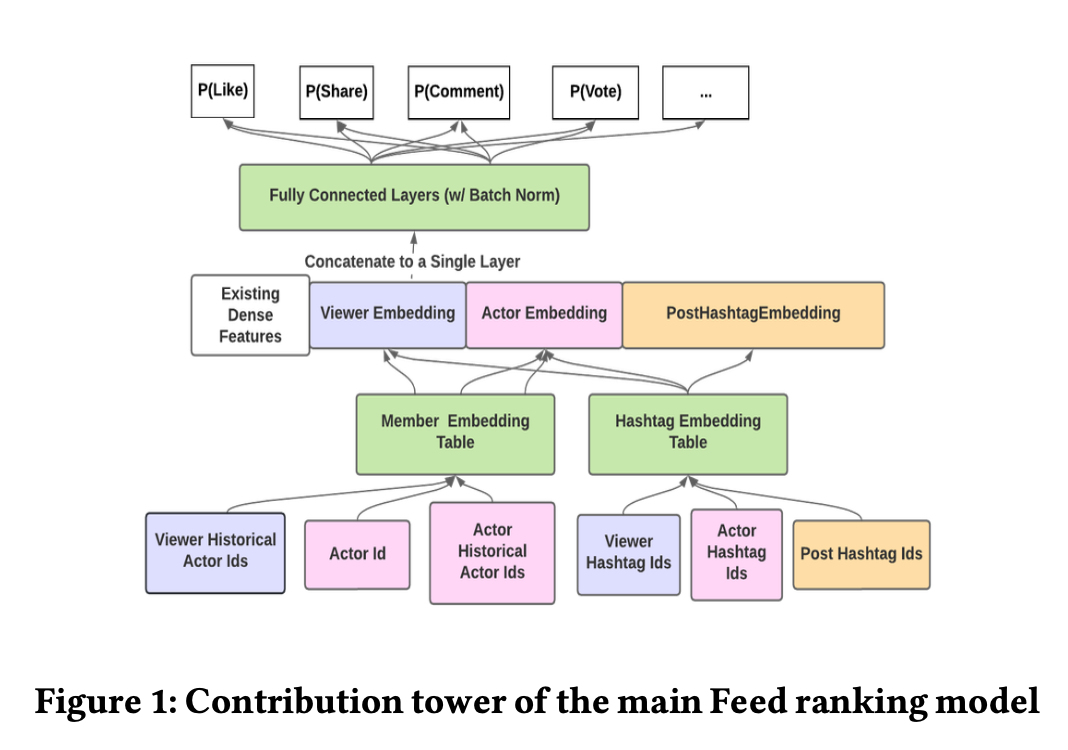
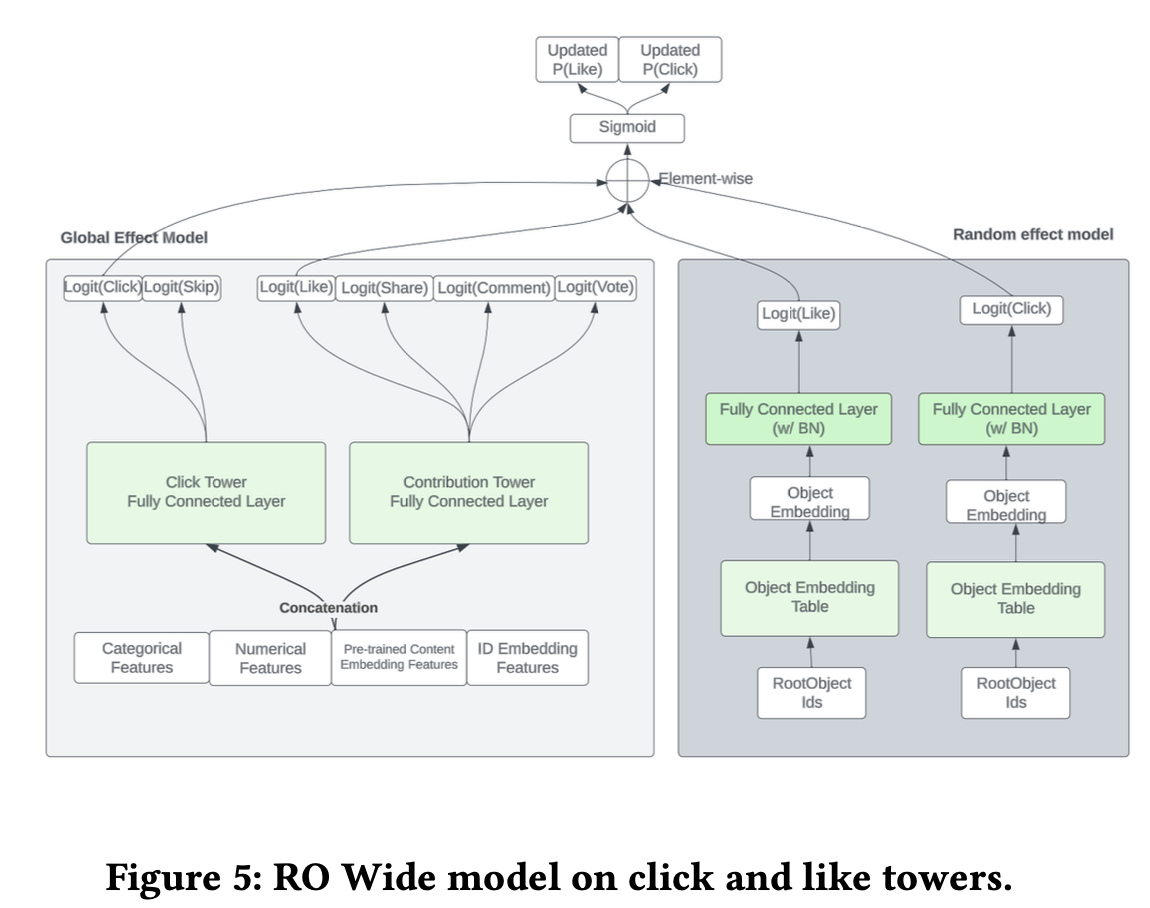
最开始的Feed排序模型是一个point-wise的排序模型,会针对每个 会员和内容的paire(<member, candidate post>)同时预估多种行为的概率,比如评论、分享、点赞、停留时长、点击等等。
一个多任务(MTL)的TF模型会通过2个塔来输出这些概率,click塔输出点击率和停留时长,contribution塔输出contribution和相关预测,这两个塔用了相同的dense feature,并叠加多层全链接。稀疏ID特征会转化成dense的embedding。
contribution塔结构如下图所示
Ads CTR Model
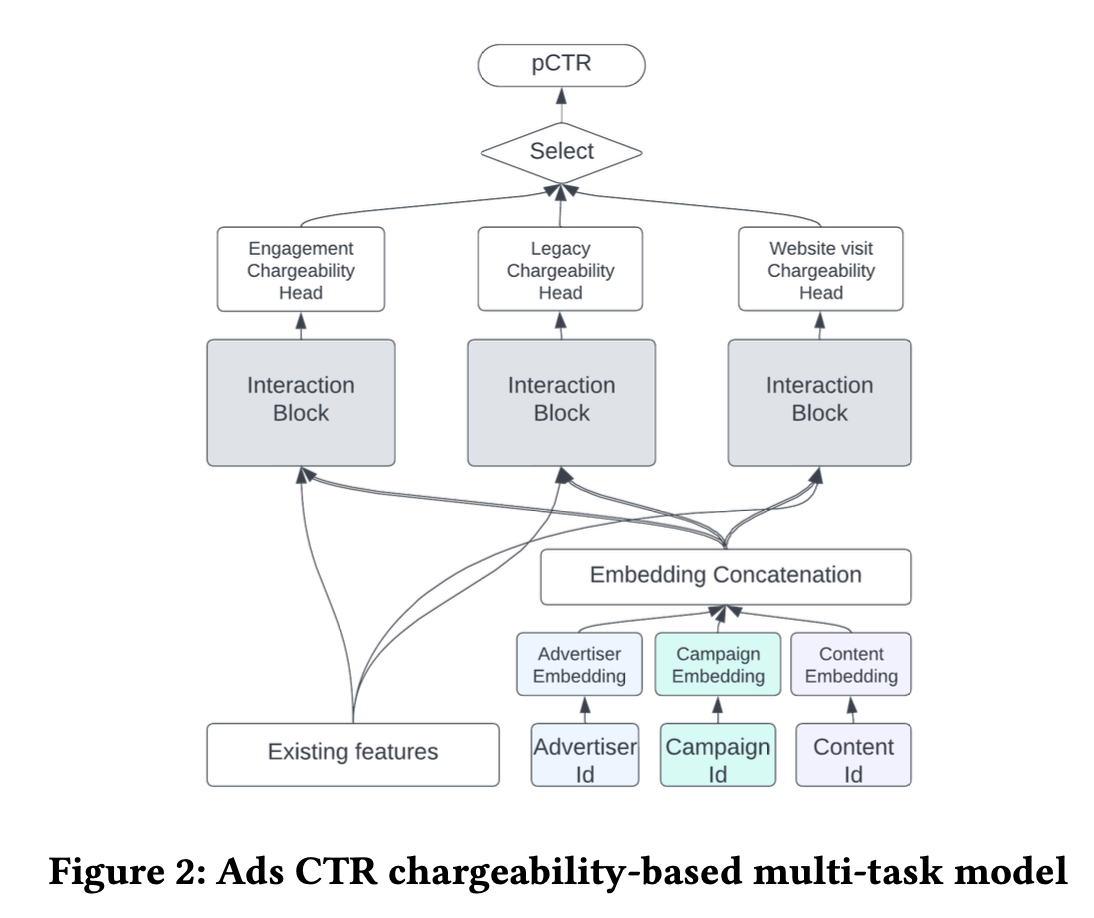
在LinkedIn,广告的选择依赖于广告CTR的预估。广告主会自定义广告计划付费点击行为,有些会选择互动行为,比如喜欢或者评论,另一些可能会选择网站访问,等等。为了更好的捕捉用户的兴趣,CTR模型是一个基于付费行为的MTL模型,有3个head输出,分别对应3组相似的付费行为,每个head都有独立的模型层,只在底层共享embedding。模型结构如下图所示,
Residual DCN
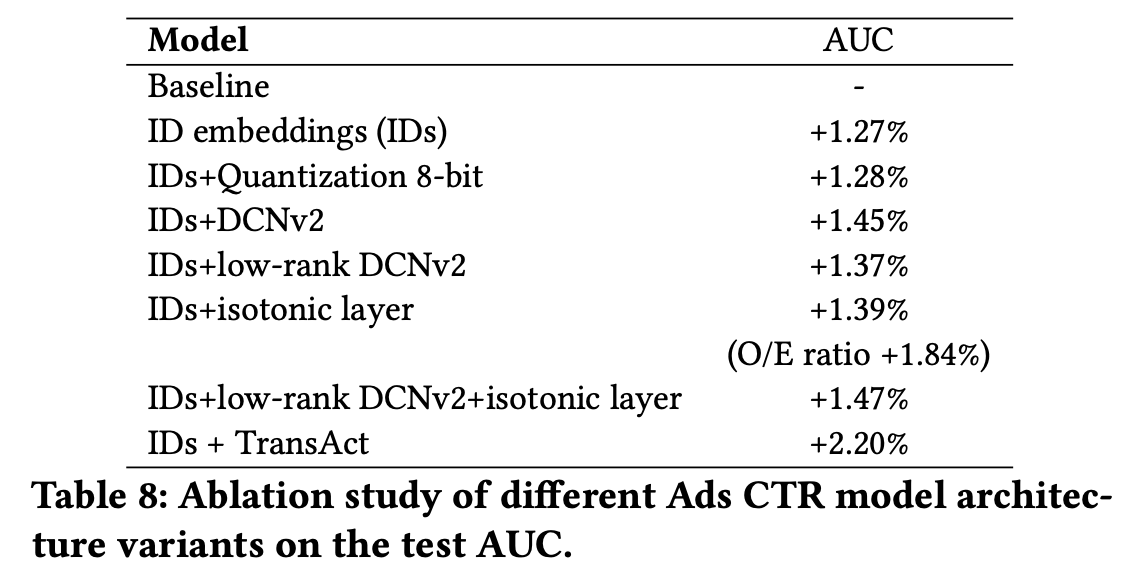
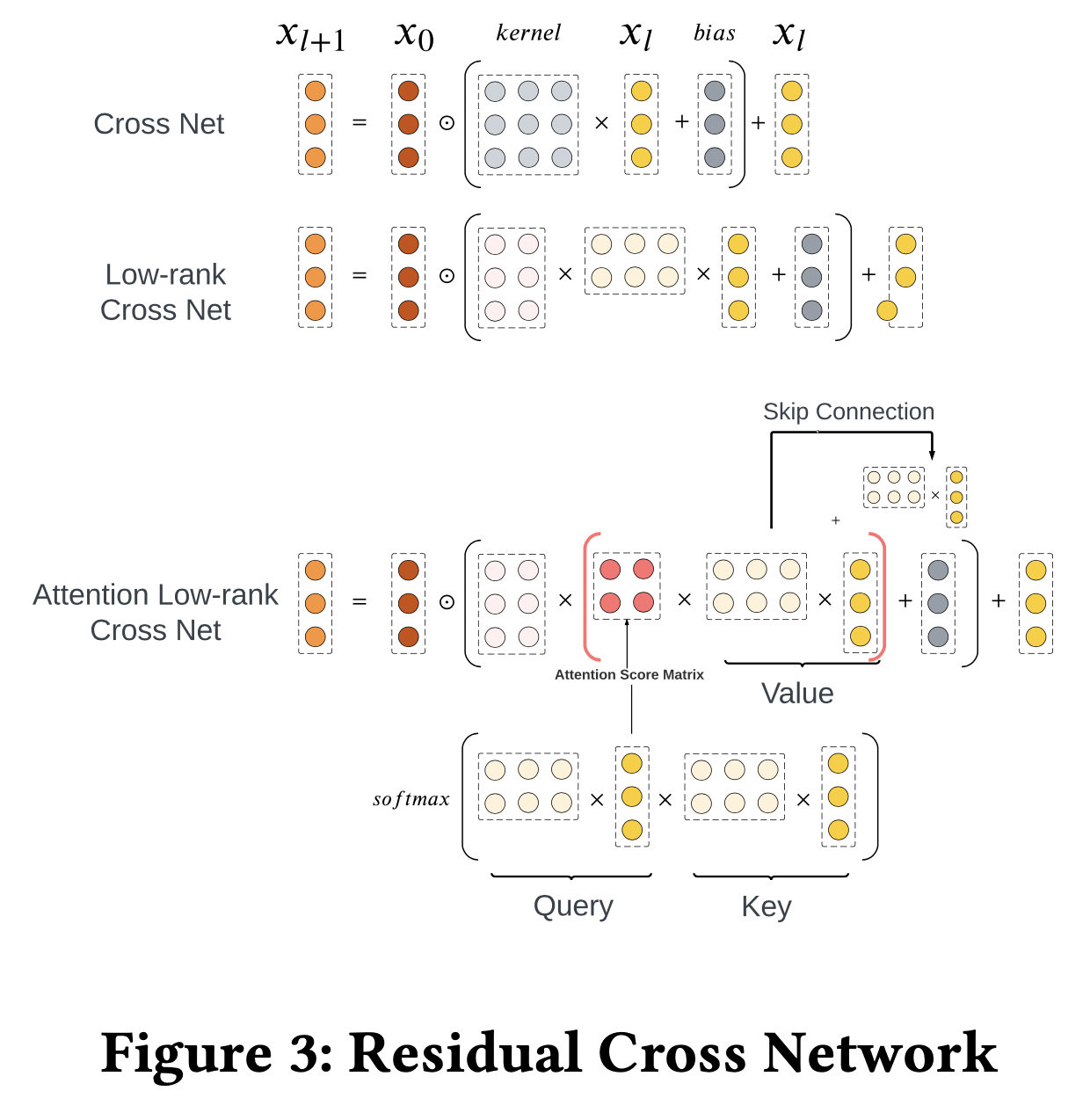
为了自动做特征交叉,我们使用了DCVv2的结构。在离线实验中,我们发现2层DCNv2已经可以提供足够的特征交叉能力,额外再增加一层,对于最终受益的提升不大,同时也增加了训练时间和推理时间的成本。
但即使只是用2层DCNv2,仍然会增加非常多的参数。为了解决这个问题,我们先对DCNv2做了矩阵分解,用2个更小的矩阵来近似,之后我们用embedding代替稀疏的one-hot,也节省了30%的参数。这些做法有效降低了DCNv2的参数量,让我们的模型可以部署在CPU上。(Arvin:这不就是日常操作吗?)
为了进一步加强DCNv2,我们在low rank的矩阵中,引入attention,原来拆成2个矩阵,现在拆为3个,中间的矩阵作为注意力分,由Value子矩阵做dot-product self-attention得到,具体计算方式如下 \[ \begin{aligned} x_{l+1}^{\text{cross net}} &= x_0 \times ( w_l \times x_l + b_l ) + x_l \\ & x_0, x_l, x_{l+1} \in \mathbb{R}^d\\ & w_l \in \mathbb{R}^{d\times d} \\ x_{l+1}^{\text{dcn v2}} &= x_0 \times ( {\color{red}{w_l^{1} \times (w^{2}_l)^{\mathsf{T}}}} \times x_l + b_l ) + x_l \\ & x_0, x_l, x_{l+1} \in \mathbb{R}^d\\ & {\color{red}{w_l^1, w_l^2}} \in \mathbb{R}^{d\times k}, k<<d \\ x_{l+1}^{\text{dcn v2 attention}} &= x_0 \times ( {\color{red}{w_l^{1}}} \times \underbrace{ { \color{green}{\quad\quad w^{a}_l} \quad\quad} }_{ {\color{green}{\text{AttentionScore}}} } \times \underbrace{ \big( {\color{red}{(w^{2}_l})^{\mathsf{T}}} \times x_l \big) }_{\color{green}{\text{Value}}} + b_l ) + x_l \\ & x_0, x_l, x_{l+1} \in \mathbb{R}^d \\ & {\color{red}{w_l^1, w_l^2}} \in \mathbb{R}^{d\times k}, k<<d \\ & {\color{green}{w_a^l}} = \text{softmax}\Big( \underbrace{ {\color{red}{(w^{2}_l})^{\mathsf{T}}} \times x_l }_{ {\color{green}{\text{Query}}} } \times \underbrace{({\color{red}{(w^{2}_l})^{\mathsf{T}}} \times x_l )^{\mathsf{T}}}_{\color{green}{\text{Key}}} \Big) \in \mathbb{R}^{k \times k} \\ \end{aligned} \] (Arvin:上图为笔者自己从图中推断,论文中没有明说计算方式,同时并没有增加跨层的连接)
attention score计算中会引入温度系数来平衡学习交叉特征的复杂度。在极度case下,attention score会退化成对角为1的矩阵,这时候等价于原DCNv2的结构。
实践中我们发现调节温度系数和增加跳层连接都会提高模型效果,同时让训练过程更稳定。
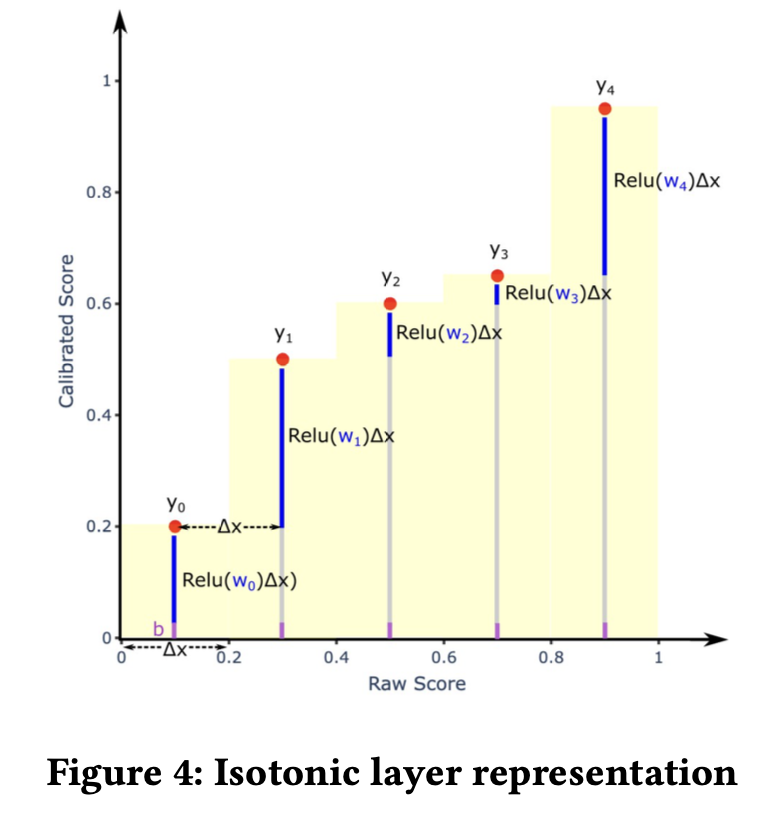
Isotonic Calibration Layer in DNN
模型校准是为了保证预估的概率与现实世界发生的概率对齐,广告计费会依赖点击率预估,能够精确校准十分重要。传统校准方式是一种训练后的处理方式,比如Platt scaling和isotonic regression。
我们提出了一个保序回归层(isotonic regression layer),可以跟NN模型一起进行训练,同时进行校准。与isotonic regression相同,也是采用一种分段校准的思路。它将模型预测值进行分桶,间隔\(v_i\),并指定一个可训练的权重\(w_i\)来更新这个分桶内的预估值,通过限定权重\(w_i\)非负,来达到保序的性质。为了增加在特定特征上的校准能力,\(w_i\)可以通过特征embedding加工得到。 \[ \begin{aligned} y_{cali} &= \sum_{i=0}^{i=k} Relu(e_i + w_i) \cdot v_i +b\\ v_i &= \begin{cases} \text{step} && \text{if} \quad i < k \\ y-\text{step}\cdot k && i=k \end{cases}\\ k&= \underset{j}{\arg\max} ( y - \text{step} \cdot j > 0) \end{aligned} \]
Dense Gating and Large MLP
扩大MLP层的宽度,会提高模型效果,离线尝试了4层3500维的MLP(Large MLP 或 LMLP),但这也带来了很多计算开销。为了解决这个问题,采用了Gate Net的结构,我们发现这是最高效的方式,基本无额外的计算开销,同时有显著的线上收益。
Incremental Training
推荐系统需要适应快速变化的生态,比如新的广告、内容和工作招聘。为了跟上这些变动,新模型经常会以最新的老模型为起始点,并持续用新数据训练,这个方式成为 热启(warm start)。这种方式可以提高训练效率,但也会使模型忘记一些学过的信息,比如catastrophic forgetting的问题。在增量训练中,不仅会使用之前模型的权重,也会用将其作为正则项加入模型。
\(t\)时刻的数据集为\(\cal{D}_t\),上一个时刻的权重为\(w_{t-1}\),对应的Hessian矩阵为\(\cal{H}_{t-1}\),总的loss为 \[ \text{loss}_{\cal{D}_t} +\lambda_f/2 \cdot (w - w_{t-1})^\mathsf{T} \cal{H}_{t-1} (w-w_{t-1}) \] 其中\(\lambda_f\)是遗忘系数,用来平衡历史样本的贡献。实践中\(\cal{H}_{t-1}\)会非常大,相比于计算整个矩阵,我们只计算矩阵的对角元素\(\text{dig}(\cal{H}_{t-1})\)。
Member History Modeling
为了建模用户和平台内容的交互行为,同样使用了transformer结构来处理序列行为特征。item的embedding、行为的embedding以及当前打分的embedding(Arvin:看起来埋了历史打分特征),通过transformer的encoder结构处理后,进行max pooling,为了增强信息,会把序列特征最后五个元素展开拼接在输出上,作为排序模型的输入。
通过一个消融实验,我们发现学习率并不会显著影响;相比于直接pooling,增加1层transformer encoder会有最大提升,在3层之后没有额外的收益了;对于其中映射的维度,提升宽度会有轻微提升。为了平衡计算耗时,我们使用 1/2的映射宽度,并限制序列长度为50。
Explore and Exploit
E&E是推荐系统经常需要面对的问题,传统的做法如UCB和Thompson采样,都无应用于NN的网络。
为了降低后验概率的计算成本,并保留网络的表征能力,我们采用了一种Neural Linear方法,将Bayesian Linear Regression应用于最后一层的权重。
Wide Popularity Features
模型中除了用全局模型的数十亿参数来捕捉趋势,还会用一个随机效应模型来预估单个item的流行趋势,这个模型每8个小时会训练一次,用于捕捉主模型的预测值和实际label的残差。
Multi-task Learning
在多任务学习方向上,尝试了grouping策略,将label相近的任务聚合为一组,也尝试过MMoE和PLE之类的结构,但是相比grouping策略的增幅较少,同时模型的参数量却大幅提升。
Dwell Time Modeling
停留时长通常面临以下挑战:
- 噪声数据使得直接预估或者对数化后预估都不稳定
- 静态的长播阈值无法适应用户的偏好,缺少一致性和灵活性
- 固定的阈值会产生bias,更利好时长更长的内容,与平台提升用户互动内容数的目标存在冲突
为了解决这个问题,我们采用了后验90分位数,作为标签阈值,且分位数的统计取决于排序位置、内容的类型、平台,聚类后产出分位数阈值来加强训练。
Model Dictionary Compression
字符串类型稀疏特征做Hash后再做embedding。
Embedding Table Quantization
Embedding量化。CTR +0.9%,认为是提升了模型泛化能力。
Training scalability
训练过程相关,数据读取,prefetch等,感兴趣可以阅读原文。
Experiments
一些消融实验,可以看出叠加各类优化技巧的收益
- feeds场景
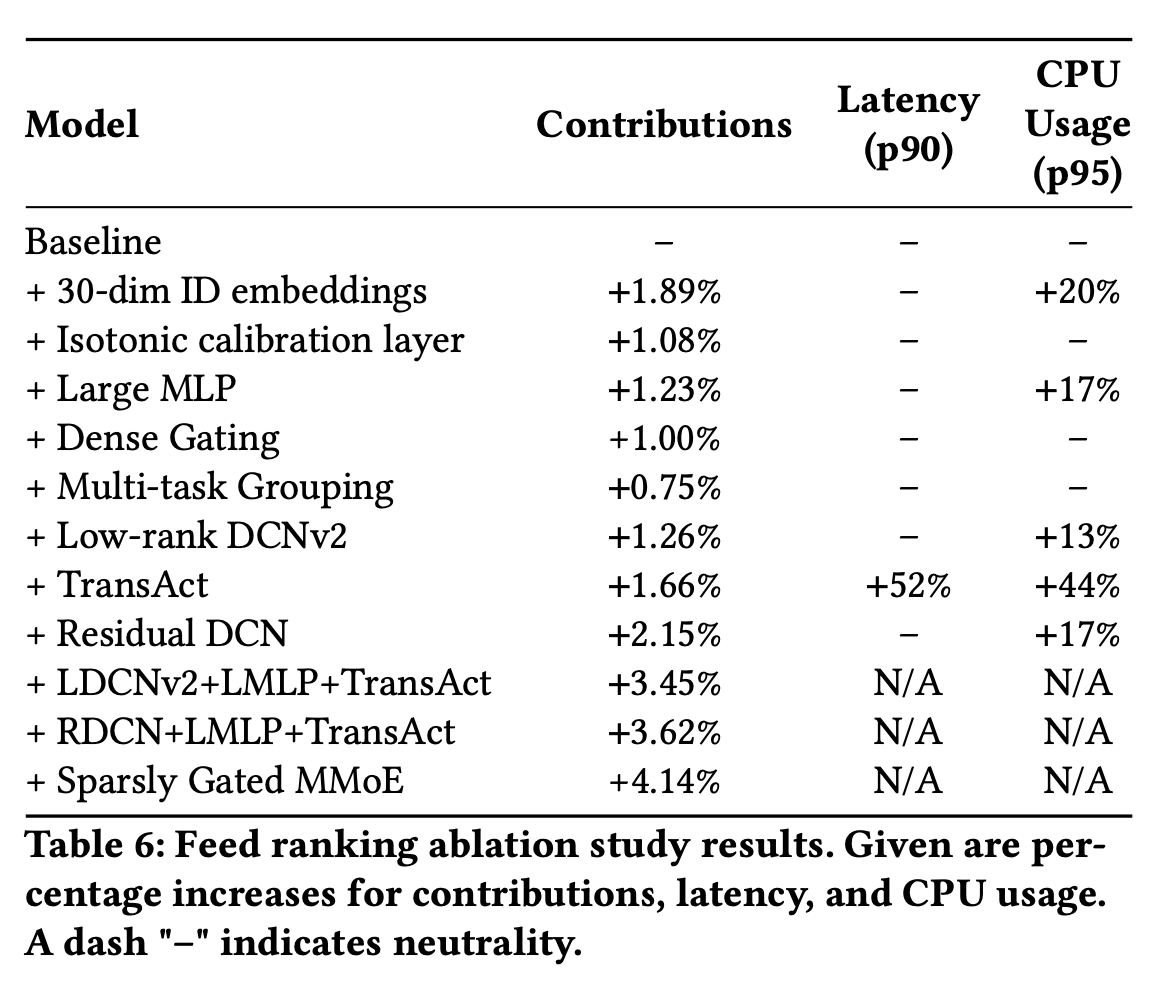
- 广告CTR