摘要
The Click-Through Rate (CTR) prediction task is critical in industrial recom- mender systems, where models are usually deployed on dynamic streaming data in practical applications. Such streaming data in real-world recommender systems face many challenges, such as distribution shift, temporal non-stationarity, and systematic biases, which bring difficulties to the training and utilizing of recom- mendation models. However, most existing studies approach the CTR prediction as a classification task on static datasets, assuming that the train and test sets are independent and identically distributed (a.k.a., i.i.d. assumption). To bridge this gap, we formulate the CTR prediction problem in streaming scenarios as a Streaming CTR Prediction task. Accordingly, we propose dedicated benchmark settings and metrics to evaluate and analyze the performance of the models in streaming data. To better understand the differences compared to traditional CTR prediction tasks, we delve into the factors that may affect the model performance, such as parameter scale, normalization, regularization, etc. The results reveal the existence of the “streaming learning dilemma”, whereby the same factor may have different effects on model performance in the static and streaming scenarios. Based on the findings, we propose two simple but inspiring methods (i.e., tuning key parameters and exemplar replay) that significantly improve the effectiveness of the CTR models in the new streaming scenario. We hope our work will inspire further research on streaming CTR prediction and help improve the robustness and adaptability of recommender systems.
CTR预测是工业推荐系统中的重要组成部分,通常CTR模型都会被部署在一个动态流式的数据环境中。在现实世界中,这种流式数据面临着许多挑战,比如分布偏移、时序非平稳性、系统造成的偏差等等,这都给训练、使用推荐模型带来困难。在当前已有的研究中,大部分认为CTR是一个在静态数据集上的分类任务,并且假设训练和测试数据是iid的。
在本文中,我们将流式数据场景下的CTR预估任务定义为Streaming CTR Prediction Task,并针对这个问题构建了benchmark和相应的指标,用于评估和分析在流式数据下模型的性能,同时为了更好地理解与传统CTR任务的差异,我们研究了可能影响模型性能的因素,比如参数规模、标准化、正则化等。
本文的结果表明了“流式学习困境”的存在,相同的因素在静态数据和流式数据上,对于模型效果的影响不同,基于这个发现,我们提出了两个简单有效的方法(调整关键参数、样本回放),能够有效提升流式场景上CTR模型的效果。
我们希望我们的工作能促进对流式数据环境下CTR预估任务的进一步研究,并帮助提高推荐系统的鲁棒性和适应性。
正文
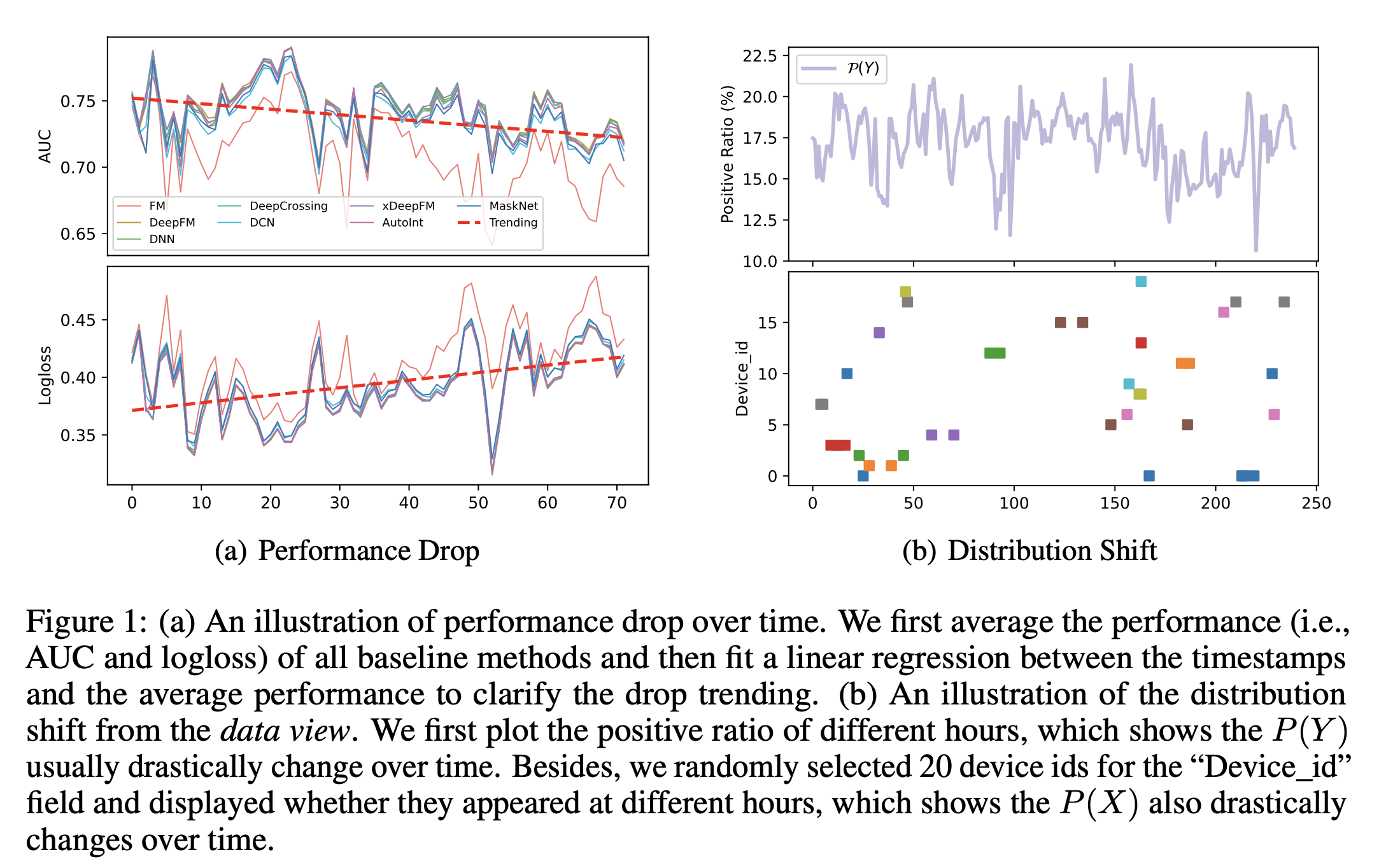
工业界推荐系统的数据往往是流式的,随着时间数据的分布可能会发生显著的变化,这种分布变化可能会对模型的效果产生影响。如下图a所示,我们将数据按照时间进行切分,CTR模型的AUC逐渐降低、LogLoss逐渐升高,说明模型的效果是受时间的影响的;下图b中,每段时间周期内,label的均值会有变化,不同device_id也会出现在不同的时间,即样本在不同时间段内分布存在差异。
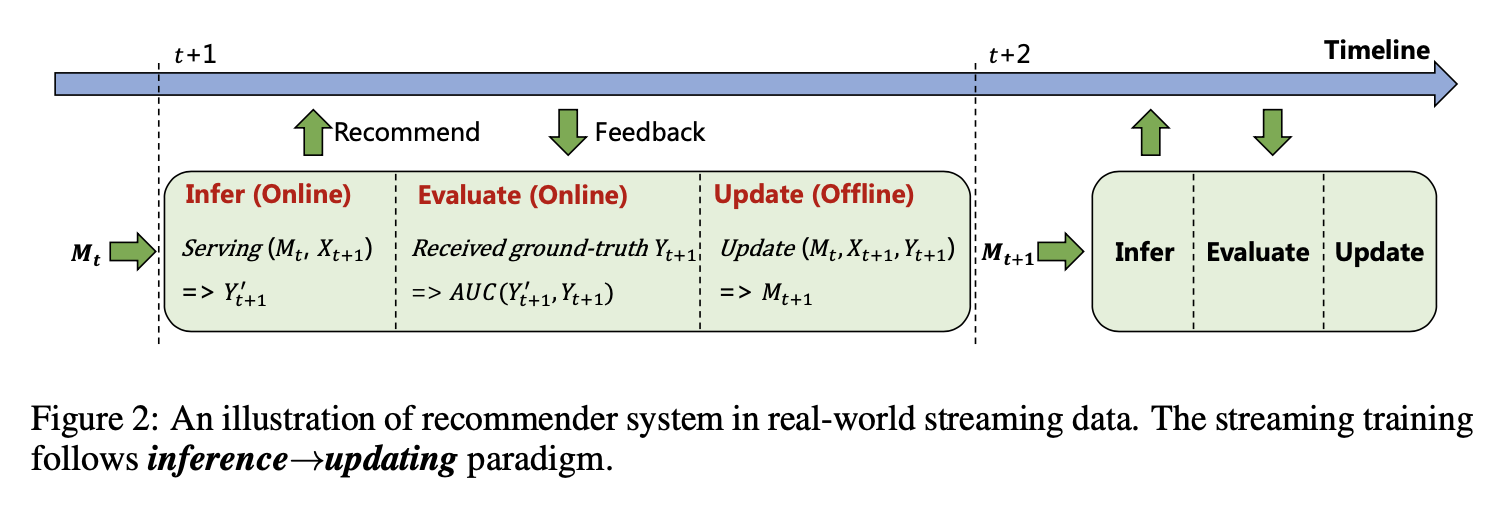
一个流式数据环境下,CTR模型的预测、评估和训练的过程如下,在第\(t+1\)的时间片内,会用上一时间片的模型\(M_t\)进行预测,得到\(Y'_{t+1}\),然后根据用户的反馈\(Y_{t+1}\)进行评估,并更新得到模型\(M_{t+1}\)。
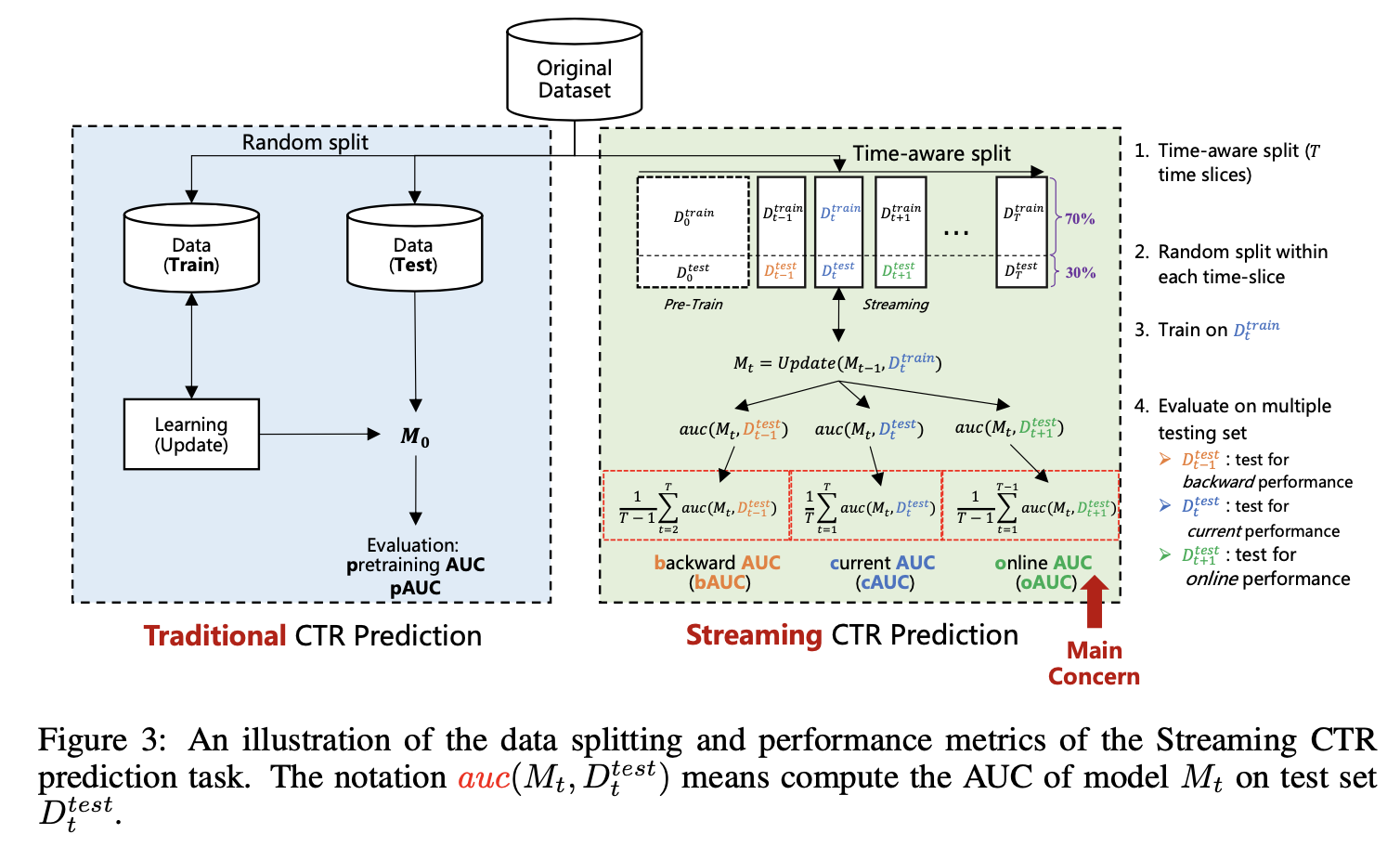
考虑到CTR模型在线更新的特点,我们提出了如下几个指标来对模型效果进行评估和分析:
- pAUC(pretraining AUC),数据集随机划分下,测试集上的AUC
- iAUC(incremental AUC),最初的模型,在后续时间片测试集上的AUC
- bAUC(backward AUC),流式训练后,上一时间片内随机划分出的测试集上的AUC
- cAUC(current AUC),流式训练后,当前时间片内随机划分出的测试集上的AUC
- oAUC(online AUC),流式训练后,下一时间片内测试集上的AUC
其中oAUC最能反应线上预测效果的好坏,但是模型训练效果受两部分影响,最开始初始化模型时候的效果以及后续流式训练的效果(业界普遍做法是先用较长历史数据 e.g. 30days进行初始化训练,之后再持续更新追上线上的模型),所以需要结合bAUC、cAUC、pAUC、iAUC共同分析
- 对比bAUC和cAUC的效果,可以看作是流式学习时,训练集上效果和测试集上的效果,可以度量不同时间段内,如果样本分布发生变化后,模型效果的变化
- bAUC也可以用于度量模型的“遗忘”程度,bAUC越高,说明模型对于过去的知识忘记的越少
- pAUC可以衡量模型最开始初始化时的效果,传统意义上静态数据环境下模型的效果
- iAUC用于衡量初始化的模型在后续学习过程中的效果,即对于分布外样本的泛化能力
集中不同AUC的计算方式如下图所示:
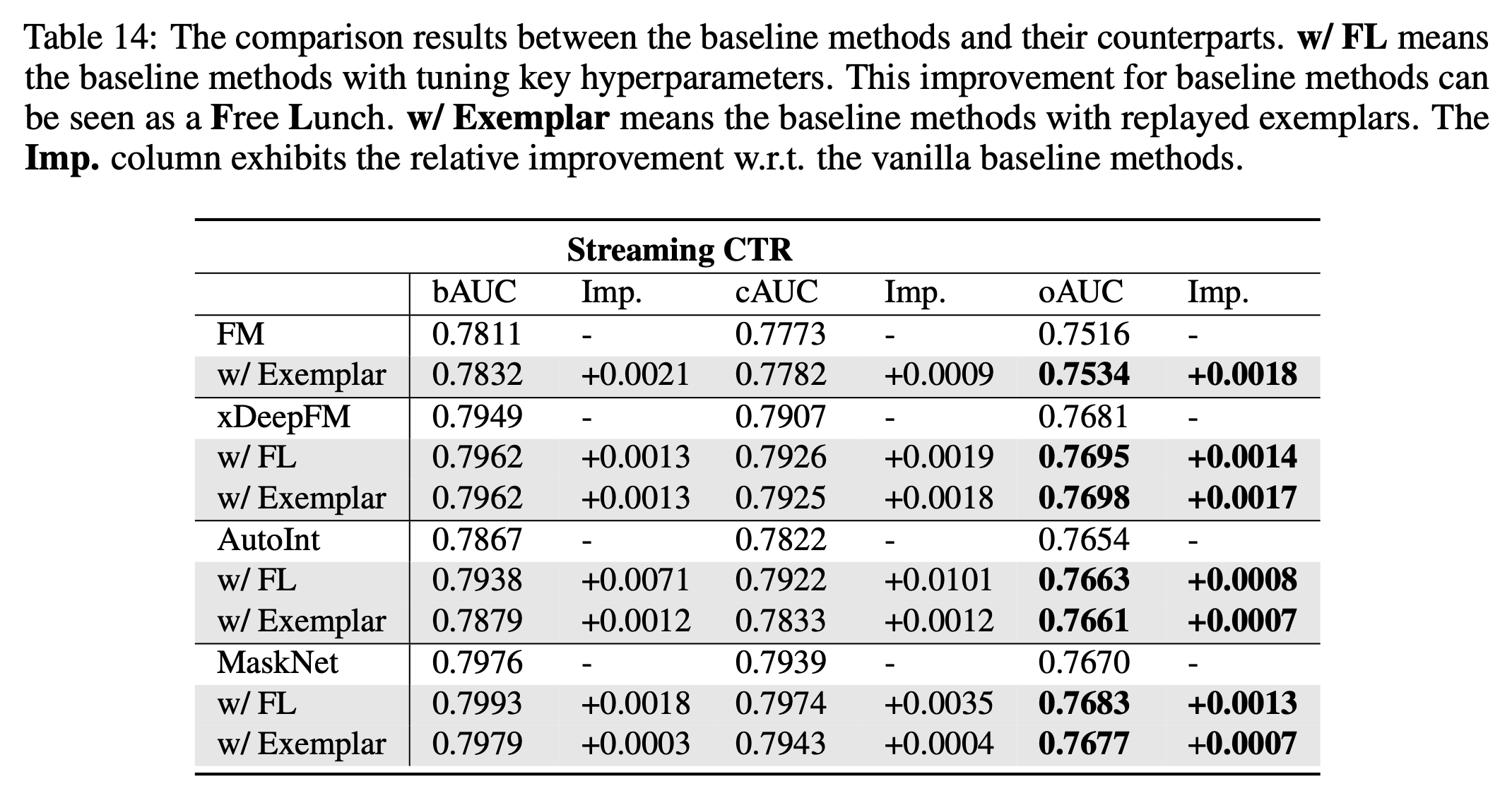
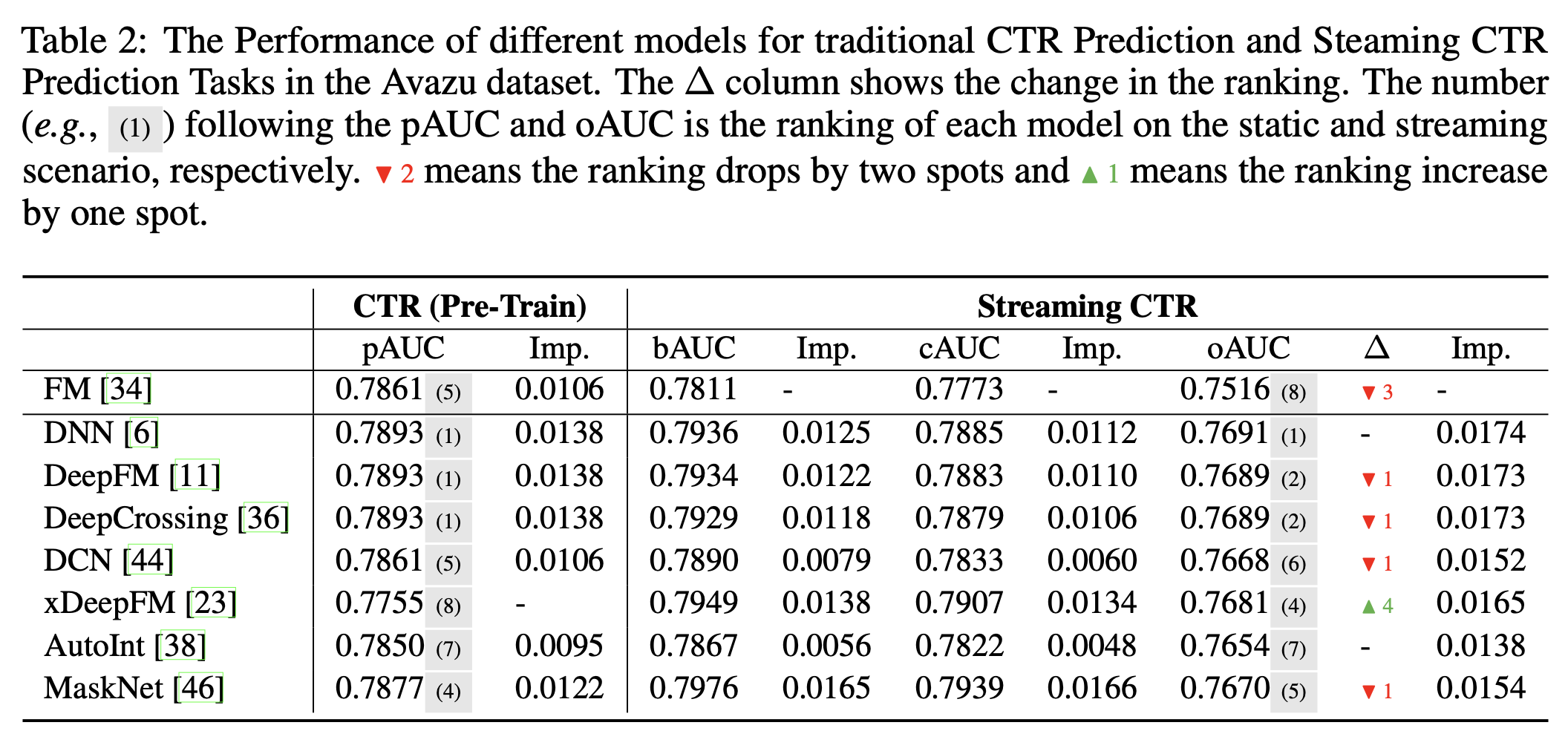
定义清楚相关指标后,文中对比了一些常见的模型的效果,其中FM和xDeepFM的效果变化较大,这也使得我们想更深入地研究影响模型流式学习效果的原因。
我们将影响因素分为两大类,这里直接写结论:
- 模型相关的因素
- 参数大小。在静态数据中,增加模型参数大小会带来效果提升,但是对于流式数据,效果提升趋于饱和的现象会更明显,提升幅度也更不明显。
- 标准化,Batch Normalization 或者 Layer Normalization。流式任务中不用标准化效果最好,BN效果最差。
- Dropout Rate。会降低效果。【没具体解释,单纯看图和表,drop out概率越大,效果越差。图下标还错了。】
- 正则项,Embedding正则化会提升iAUC,但会降低pAUC和oAUC,MLP正则化会降低效果。
- 优化算法相关的因素
- 优化器,Adam相关的优化器效果表现较好。
- batch size,大batch size会有更好的泛化效果,不论iAUC还是oAUC都提升很多,过大的batch size(5000->10000)会让效果提升趋于饱和。
- training epoch。【一顿分析没看懂。写得太差了。】
结合上述分析,我们提出两种简单有效的办法来来提升oAUC:
- 根据oAUC调整关键超参数。因为有些超参数对于pAUC和oAUC的提升效果不一致,所以我们建议根据oAUC来调整这些超参数。(这其实是一个比较简单能提点数的办法,目前大部分实践都是根据pAUC做模型参数的调整,并不会根据线上ODL的效果进行调参)
- 样本回放。CTR模型仍会受到“样本遗忘”问题的影响,通过样本回放的方式可以有效提高模型效果。