摘要
Data selection bias has been a long-lasting challenge in the machine learning domain, especially in multi-stage recommendation systems, where the distribution of labeled items for model training is very different from that of the actual candidates during inference time. This distribution shift is even more prominent in the context of online advertising where the user base is diverse and the platform contains a wide range of contents. In this paper, we first investigate the data selection bias in the upper funnel (Ads Retrieval) of Pinterest’s multi-cascade ads ranking system. We then conduct comprehensive experiments to assess the performance of various state-of-the-art methods, including transfer learning, adversarial learning, and unsupervised domain adaptation. Moreover, we further introduce some modifications into the unsupervised domain adaptation and evaluate the performance of different variants of this modified method. Our online A/B experiments show that the modified version of unsupervised domain adaptation (MUDA) could provide the largest improvements to the performance of Pinterest’s advertisement ranking system compared with other methods and the one used in current production.
数据选择偏差是机器学习领域一直以来都面临的挑战,特别是在多阶段的推荐系统中,模型训练所用到的样本分布与在线推断时候的样本分布有较大差异。在在线广告中,用户群体多样、平台包含各种各样的内容,这种分布的差异更加突出。
在本文中,我们先研究了Pinterest的多级广告排序系统上所存在的数据选择偏差问题,并利用各类sota的方法进行了全面的实验,包括迁移学习、对抗学习、非监督域适应等。此外,我们在无监督域适应学习上做了一些优化,并评估了不同参数下模型的效果。在线AB实验表明,经过优化的无监督域适应模型(MUDA)对Pinterest的广告排名系统有显著的提升。
正文
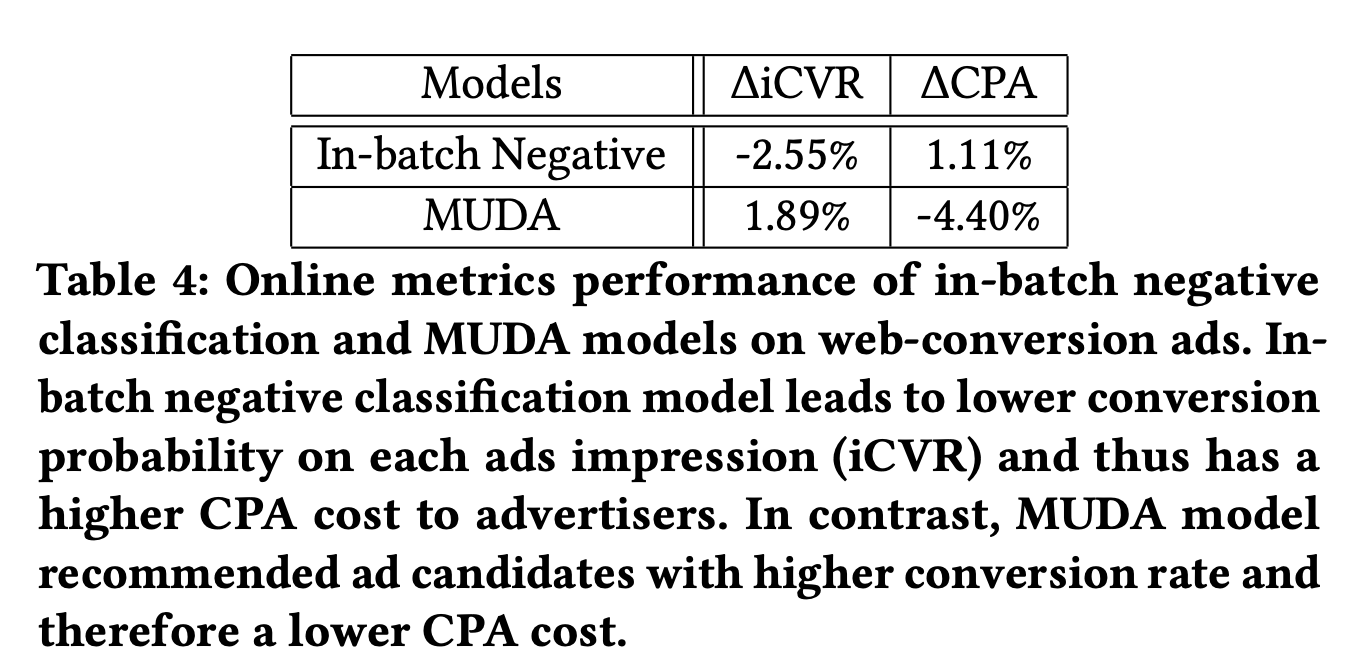
如下图所示,Pinterest平台上的广告在被展示前往往有以下四个阶段:定向(选中目标人群)、召回(文中为retrieval,可以理解为电商场景下粗排的角色,此处称之为召回)、排序和竞价,其中每阶段都会对相关的候选物品进行打分或者过滤,最终从数百万的候选集中筛选出数个内容进行展示。
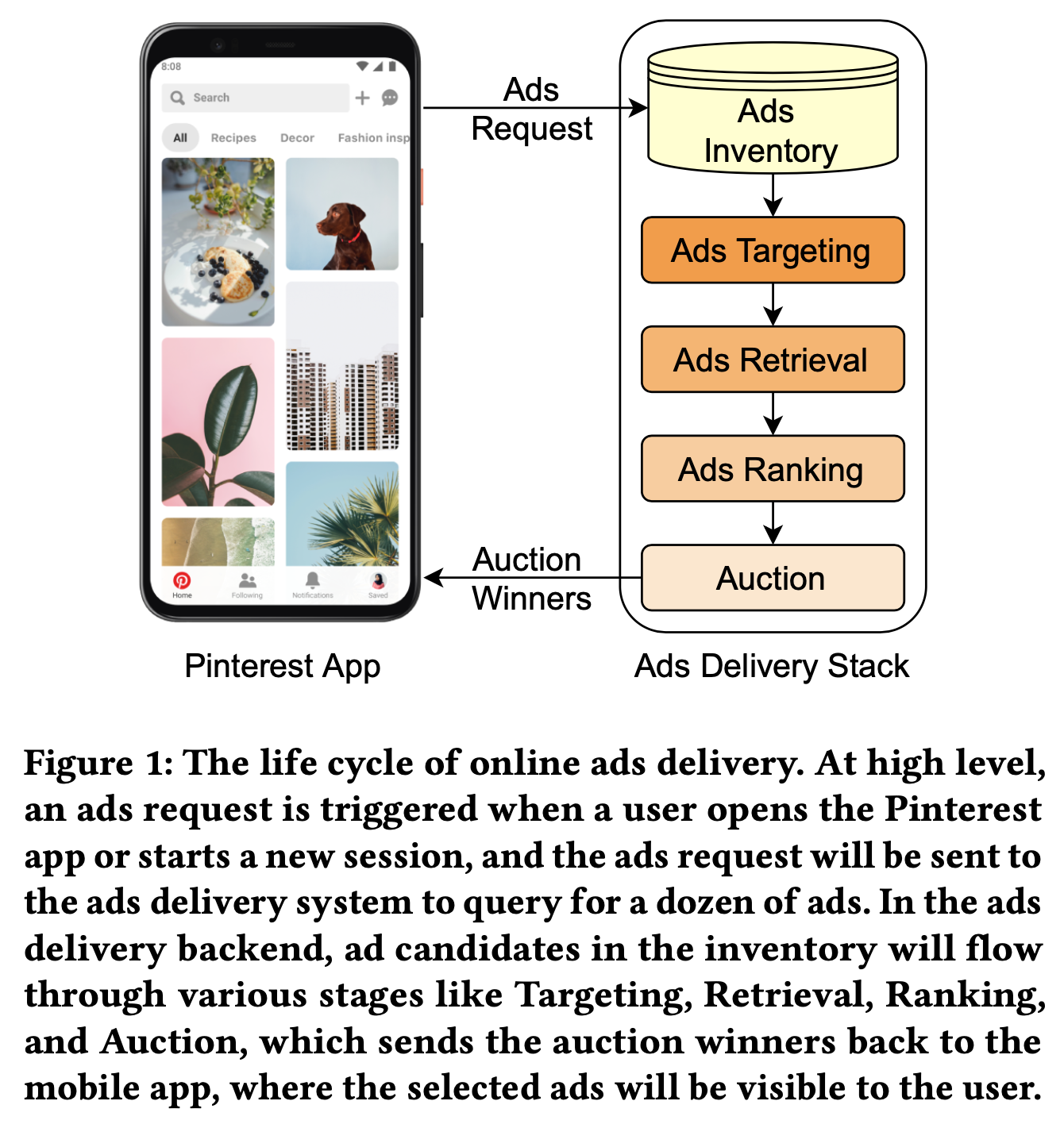
对于召回阶段的模型,我们会收集两个环节的数据用做模型训练:参与竞价的候选物品集合和最终竞得的物品集合,其中精排模型对于前者的打分会作为伪标签,最终竞得的样本以及用户发生行为的物品作为真正的样本标签。为了保证模型的时效性,模型会做天级别的更新。(下图a)
然而,这种构建训练样本方式会带来样本选择偏差,预测阶段会对定向后的物品候选集进行打分,而训练阶段使用的样本来自竞价阶段,后者是前者的子集,如上图b、c、d所示,在召回候选集合(post-Targeting candidates)、竞价阶段候选集合(auction candidates)以及竞价获胜的物品集合(auction winners,即最终曝光的物品)上,不同任务上的精排的打分分布有显著差异。(选择精排打分分布,是因为训练时候会用精排打分作为label,作者认为精排模型有最好的打分能力,前链路应该向召回看齐。此处多说一句,目前主流的思路是 召回、粗排、精排应该有一致性,但是应该向什么对齐却是有待讨论的,精排受限于前链路的样本bias,候选集较大时排序能力并不强,甚至弱于粗排,召回粗排又受限于精排决定的曝光样本,如何定义出一个ground truth的label,是目前研究的重点)
下面我们对这个问题做一些定义,用\((u,a,y)\)分别表示用户特征、广告特征和实际label,\(F_\theta\)表示参数为\(\theta\)的模型,\(l\)表示损失函数,我们希望能够最小化理想的目标: \[ \underset{\theta}{\min} {\cal{L}}_\text{ideal}(F_\theta) =\frac{1}{|\mathbb{D}|} \sum_{(u,a)\in\mathbb{D}} l\Big(y, F_\theta(u,a)\Big) \] 其中\(\mathbb{D}\)表示全集的分布,也即非偏的样本集合。由于我们只能观测到全集样本子集,所以无法直接面向这个目标进行优化。下面我们会介绍我们尝试过不同的方式,对上述目标进行“近似”优化。
- 最基础的方式,二分类建模,\(\underset{\theta}{\min}{\cal{L}}_\text{naive}(F_\theta)=\frac{1}{|\mathbb{O}|}\sum_{(u,a)\in\mathbb{O}} l\Big(y, F_\theta(u,a)\Big)\)
- batch内负采样,在二分类建模中,用户未点击样本作为负样本,这种做法并不一定正确,用户可能会认为这些广告是有价值的,但在当前时刻并没有做任何动作,所以我们在训练的batch中,用其它请求的样本作为负样本,进行二分类模型的训练。需要注意的是,我们只保留了所用用户的正样本做训练。
- 知识蒸馏,用精排的模型进行蒸馏,用\(R\)表示精排模型,\(\underset{\theta}{\min}{\cal{L}}_\text{kd}(F_\theta)=\frac{1}{|\mathbb{O}|}\sum_{(u,a)\in\mathbb{O}} l\Big(R(u,a), F_\theta(u,a)\Big)\)
- 迁移学习,其核思是用原域的数据进行训练,然后在目标域上进行fine-tune,所以我们用定向后的数据集来作为unbiased dataset进行finetune(unbiased 是因为召回模型在推断阶段打分集合如此)
- 对抗学习作为正则化,对于bias问题的另一种观点是,模型在biased数据上学到的表征,在unbiased数据上泛化能力不足,造成效果不好,所以我们可以在学习过程中增加正则化,来矫正表征的学习。具体做法如下,用\(F_1\)和\(F_2\)来表示模型级联的输出,用\(H\)表示一个二分类学习器,\({\cal{L}}_\text{cls}(u,a)=-\mathbb{I}_{(u,a)\in\mathbb{D}}\log H\Big(F_1(u,a)\Big)-\mathbb{I}_{(u,a)\in\mathbb{O}}\log \bigg(1 - H\Big(F_1(u,a)\Big)\bigg)\),即判断这个预测是来自unbiased样本集合还是biased样本集合,总的损失函数是\({\cal{L}}_\text{adv}={\cal{L}}_\text{target}\bigg(\Big(F_2(F_1(u,a)\Big), y\bigg)-\lambda {\cal{L}_\text{adv}}\)
- UDA(Unsupervised Domain
Adaptation,非监督域适应),UDA是一类用目标域样本无监督训练、用原域样本有监督训练的算法。
- 原始UDA,\(\underset{\theta}{\min}{\cal{L}}_\text{naiveUDA}(F_\theta)=\frac{1}{|\mathbb{D}|}\sum_{(u,a)\in\mathbb{D}} l\Big(R(u,a), F_\theta(u,a)\Big)\),用精排模型给unbiased样本打分,然后训练召回模型
- MUDA,在原始的UDA算法中,我们很难保证排序模型\(R\)在unbiased集合上的效果,所以我们针对样本做一定筛选,定义上下阈值\(\delta_l\)和\(\delta_h\),低于下界的为负样本,高于上界的为正样本,\(\underset{\theta}{\min}{\cal{L}}_\text{mUDA}(F_\theta)=\frac{1}{|\mathbb{D}|\cdot|\mathbb{O}|}\sum_{\{(u,a)|(u,a)\in \mathbb{D}\cup\mathbb{O},R(u,a)<\delta_l||R(u,a)>\delta_h\}} l\bigg(\Phi^{\delta_h}_{\delta_l}\Big(R(u,a)\Big), F_\theta(u,a)\bigg)\)
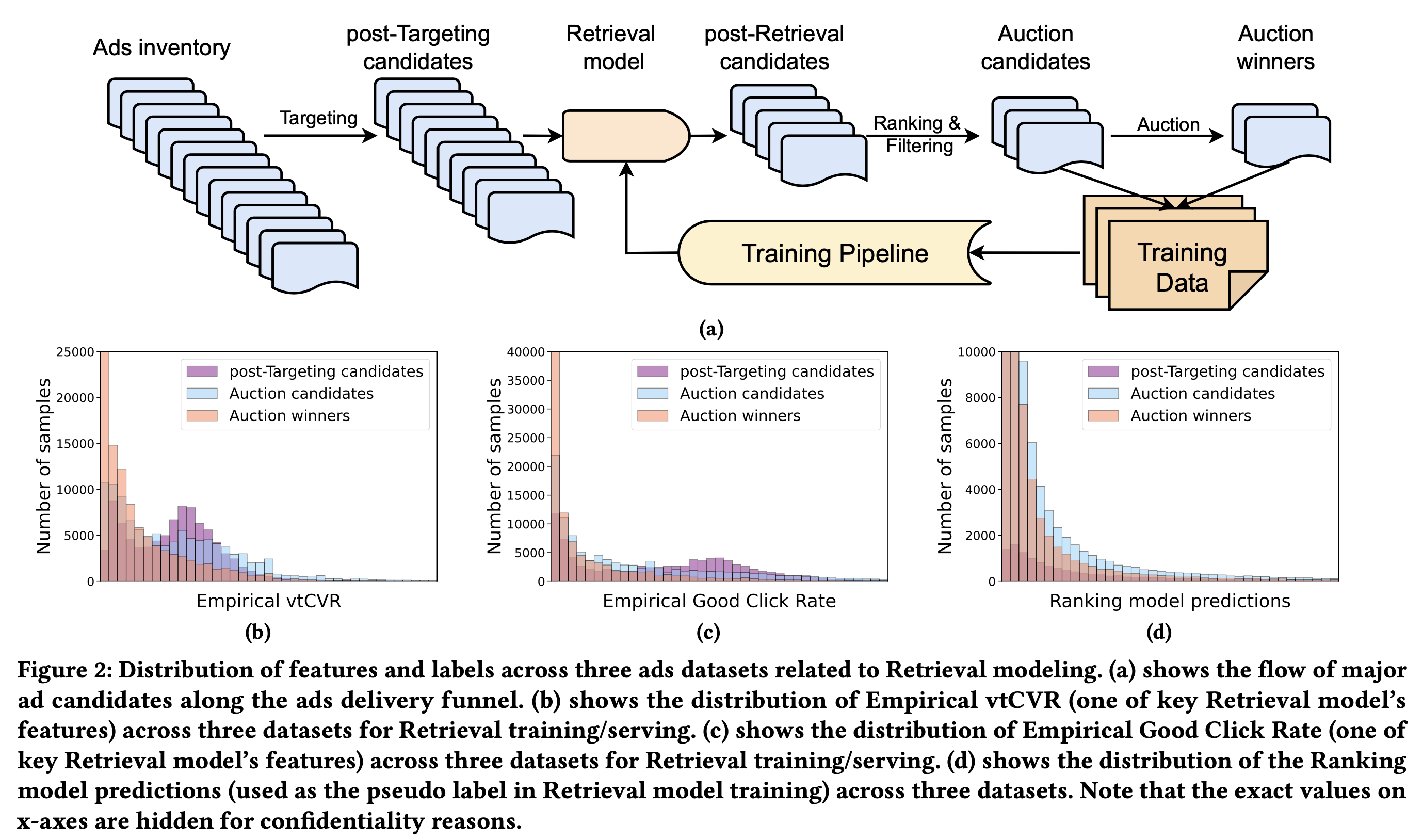
离线评估,前几种方式往往会有较高的AUC,但由于样本有偏,离线AUC并不能真正反映出模型的效果。
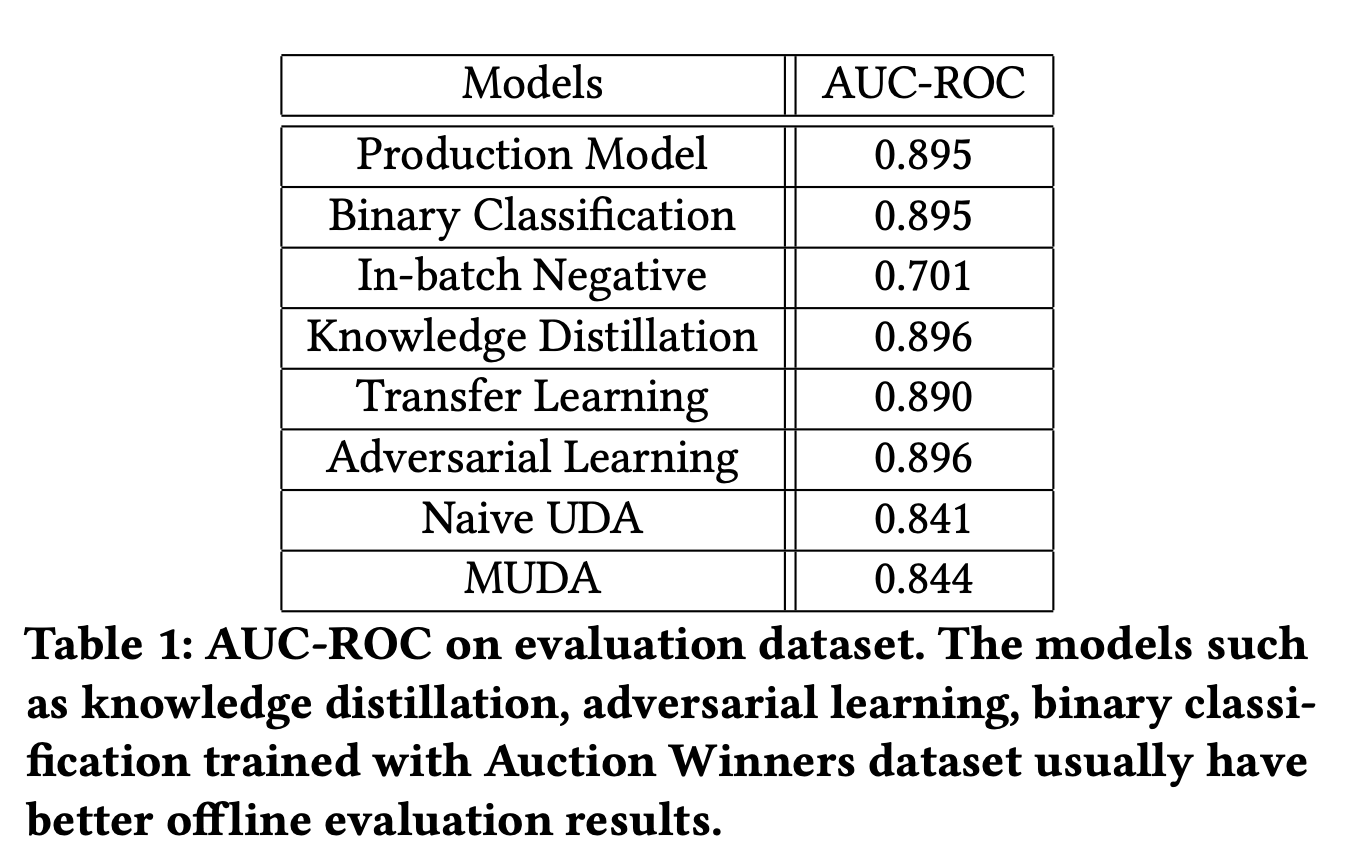
在线实验,mUDA模型在多目标上,都取得了较好的结果。
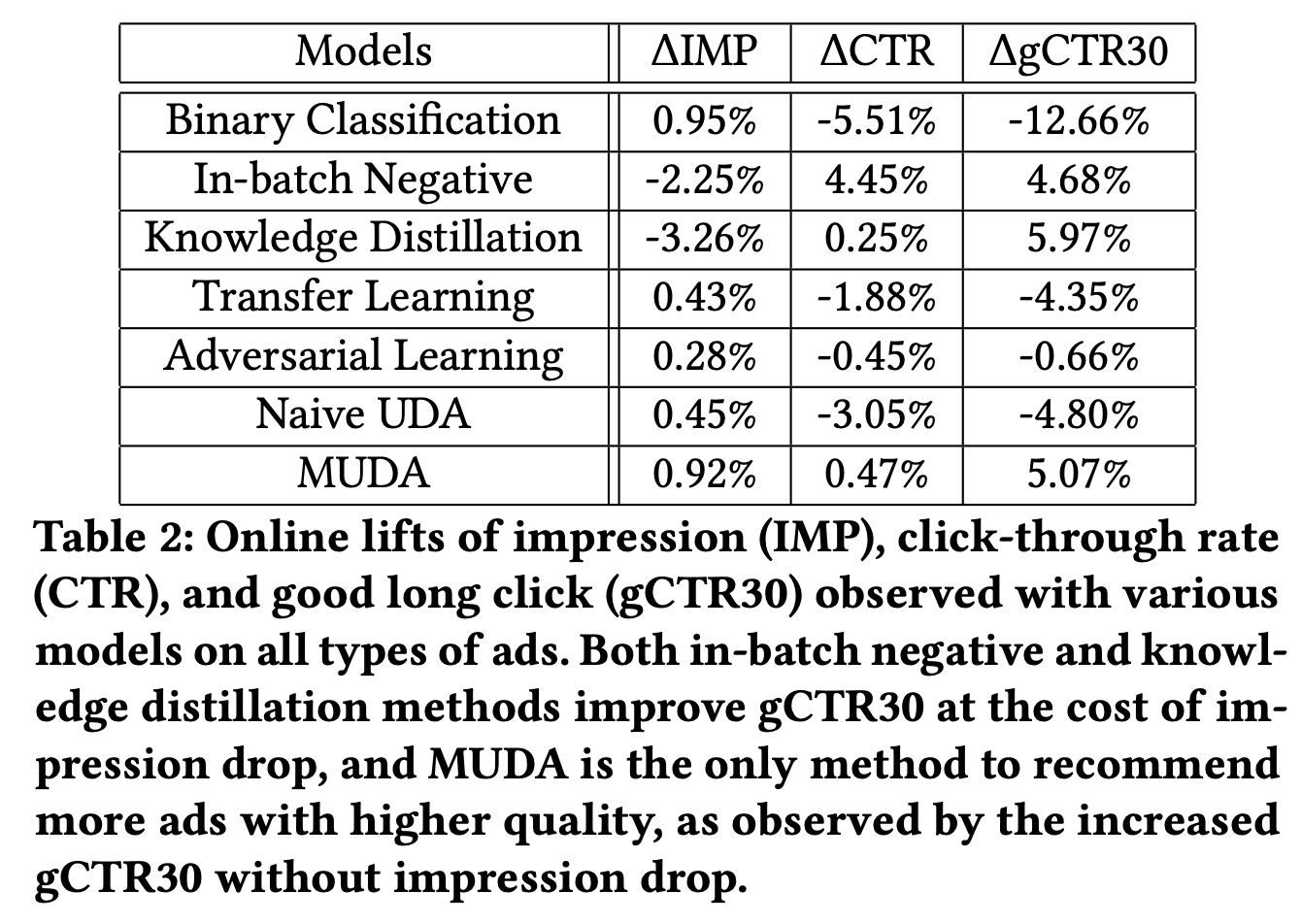
值得注意的是,样本内负采样的方式,虽然也同时带来的CTR和gCTR30的增长,但实际上是由于不同类型上广告流量变化所带来的差异,对于广告后链路转化效果而言,mUDA效果也更好。