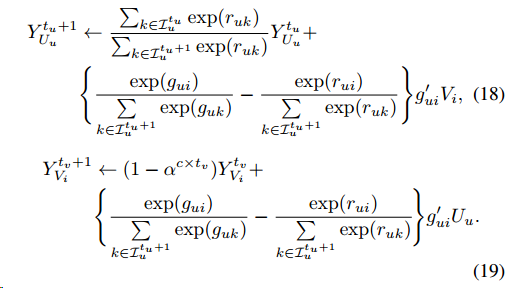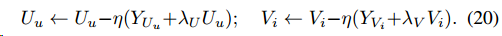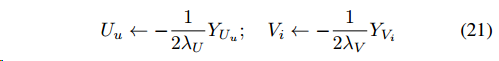这篇文章是做online learning的CF,用到了dual-averaging的方法,便于在线计算梯度、更新权重。
CF一直是非常经典的推荐算法,但经常考虑的都是静态的环境下做推荐,很少有考虑动态场景的,比如说: - 新的物品到达推荐系统中 - 新的用户加入到推荐系统中 - 新的评分出现
本文主要几点contribution包括提出了两种在线学习的方式,基于PMF和RMF做了在线学习的算法。Dual-Averaging Method方法主要思想是根据历史的平均梯度加上单个样本的梯度,以此作为新的更新方向。之后找时间会把它完整总结一下,这里先看一下具体算法。
PMF
概率矩阵分解模型是对factor vector做正太分布的先验,目标函数是 \[
\mathcal{L}=\frac{1}{2}\sum^N_{i=1}\sum^M_{j=1}I_ij(r_{ij}-g_{ij})^2+\frac{\lambda_U}{2}\|U\|^2_F+\frac{\lambda_{V}}{2}\|V\|^2_F
\] 其中\(g\)为评分函数,将值映射到\([0,1]\) \[
g(x)=1/(1+\exp(-x))
\] 梯度更新为 \[
\begin{aligned}
U_i\leftarrow U_i-\eta\frac{\partial\mathcal{L}}{\partial U_i}\\
V_j\leftarrow V_j-\eta\frac{\partial\mathcal{L}}{\partial V_j}\\
\end{aligned}
\] 对于SGD-PMF迭代方式很简单,对损失函数直接求梯度然后迭代即可
\[
\begin{aligned}
U_i\leftarrow U_i-\eta((g_{ui}-r)g'_{ui}V_i+\lambda_UU_u)\\
V_j\leftarrow V_j-\eta((g_{ui}-r)g'_{ui}U_u+\lambda_VV_i)\\
\end{aligned}
\]
而用Dual-Average的方法迭代更新方式为,先计算平均梯度,以更新\(U_u\)为例 \[
Y_{U_u}\leftarrow\frac{t_u-1}{t_u}Y_{U_u}+\frac{1}{t_u}(g_{ui}-r)g'_{ui}V_i
\] 对于\(V_i\)同理,然后下一步的更新为 \[
\begin{aligned}
U_u=\underset{w}{\arg\min}\{Y^T_{U_u}w+\lambda_U\|w\|^2_2\}\\
V_i=\underset{w}{\arg\min}\{Y^T_{V_i}w+\lambda_V\|w\|^2_2\}\\
\end{aligned}
\]
我们可以看到RAD的方式是直接选择梯度方向指向的点作为下一步的更新值,前面与累计梯度的内积确定了下降的方向,后面的正则项确定了下降的步长,然后根据单个样本更新迭代完成梯度的下降。

RMF
RMF也是以一种概率矩阵分解的方式,与PMF不同的是它考虑的损失函数是交叉熵,定义top-one概率为一个商品排序在top的概率,实际评分的top-one概率为
\[
P_R(r_{ui})=\frac{\exp(r_ui)}{\sum_{k=1}^MI_{uk}\exp(r_uk)}
\] 预测值的top-one概率为 \[
P_{UV}(g_{ui})=\frac{\exp(g_ui)}{\sum_{k=1}^MI_{uk}\exp(g_uk)}
\] 然后来最小化两个分布的交叉熵 \[
H(p,q)=E_p[-\log q]=-\sum_x p(x)\log(q(x))
\] 所以我们可以写出损失函数为 \[
\mathcal{L}=\sum^N_{i=1}\{-\sum^M_{j=1}I_{ij}\frac{\exp(r_ui)}{\sum_{k=1}^MI_{uk}\exp(r_uk)}\log\{\frac{\exp(g_ui)}{\sum_{k=1}^MI_{uk}\exp(g_uk)}\}\}+\frac{\lambda_U}{2}\|U\|^2_F+\frac{\lambda_{V}}{2}\|V\|^2_F
\] 此处因为RMF的梯度太长了我也不写了,截图一下