这篇文章是今年年初时候发在sigkdd上的一篇关于eta的文章,《Learning to Estimate the Travel Time》。
背景
车辆行驶时间估计是重要的位置服务的之一,而且在滴滴的服务中占有比较重要的一环,这篇文章提出了一个新的ETA的模型,并应用于滴滴出行的线上服务。传统的ETA主要分为两类,第一类就是基于路径的方法,整条路径的行驶时间等于其中每一段路径时间的和: \[ \hat{y}=\sum_i\hat{t}_i+\sum_j\hat{c}_j \] 其中\(\hat{t}_i\)是第\(i\)段路径的行驶时间,\(\hat{c}_j\)是第\(j\)个路口的等待时间。这种方法被广泛应用于学术界和工业界,它把行驶时间分成几个子问题,包括估计路径中一段的行驶时间和路口的等待时间,一般用回归或者是张量分解的办法来预测一段路径上的行驶时间或者行驶速度,还有一些研究关注于行驶时间的近似,这样可以得到一个更通用的子路径旅行时间的估计。这些方法通常有以下难点:
- 尽管有大量的历史时空数据,但仍然是相对稀疏的
- 运输系统是一个动态系统,这些方法很难刻画出系统变化的过程
- 这样的分解子问题方法可能会导致误差的累加,这样对整体的估计是不利的
- 个性化对于ETA而言非常重要,而上述模型都很难体现这方面
第二种方式是数据驱动的方式,有一些方法将路径上的行驶时间建模成一个时间序列模型,ETA则成为一个多变量时间序列预测问题。这种方式更灵活,然而也同样有一些缺点:
- 数据稀疏问题仍然存在
- 行驶时间预测被限制在一些固定的路径上,很难泛化到其他没见过的路线上
- 许多关键信息都被忽视了,诸如交通情况和司机个人的信息
本文提出一种新的基于机器学习的方法来克服这些现有方法已存在的问题,我们建立了一个丰富的位置数据特征库,包括车辆数据、路况数据、用户行为数据等等。基于这些提取的特征,我们把ETA建模成一个回归问题,并对比了GBDT、FM等模型,同时建立了一个新的深度学习模型。
模型
此处省略一些建模细节,只讲大体思路。
特征提取
- 空间特征,从地理信息中提取一些特征,我们先将车辆轨迹映射到路网中,并获取一些列道路段和路口,然后我们提取这些路段、路口的信息,包括路径长度、宽度、车道数量等等
- 时间特征,如一些道路的高峰段时间
- 交通信息,主要是每个路段车辆行驶速度、车流量等
- 司机个人信息,驾龄、车型等等
- 额外特征,天气、交通限制等等
Learning to Estimate the Travel Time
我们用MAPE作为误差 \[ \min_f\sum^N_{i=1}\frac{|y_i-f(x_i)|}{y_i} \] 为了保证一定的泛化能力,避免过拟合,我们增加一个正则项 \[ \min_f\sum^N_{i=1}\frac{|y_i-f(x_i)|}{y_i}+\Omega(f) \] 文中对比了GBDT和FM两种模型。两个模型的细节都是老生常谈了,之前也写过,此处不赘述了。
Wide-Deep-Recurrent Learning
在实际中,GBDT和FM并不是解决ETA问题的最好的模型。GBDT难以处理过大的特征集合,FM又很依赖于特征,并且模型表达能力有限。同时,我们又拥有分布复杂数据量庞大的历史数据,这使得我们需要采用更复杂的模型来解决这个问题,所以我们选择了深度学习的方法。
Wide&Deep Model是之前谷歌提出的,做ctr的模型,一方面做特征的交叉,一方面用简单的网络结构做深层的特征映射。
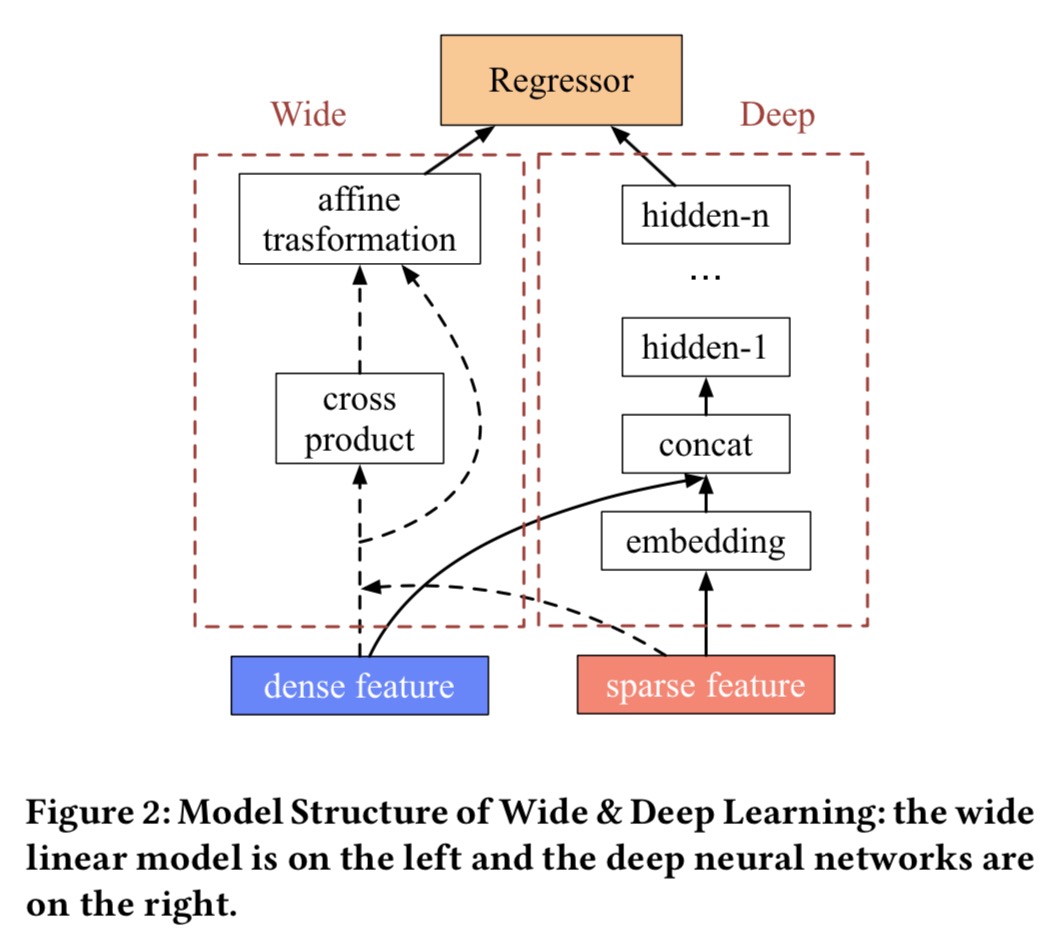
模型中Wide的部分负责将特征映射到高维的特征空间,做叉积的操作,这种方法类似于FM,然后做仿射变化,主要就是一个线性加权求和,一个浅层的网络结构,这部分主要是一个线性的部分,Deep的部分负责将稀疏的特征映射到密集的特征空间中,相当于做embedding,然后concat这部分embedding,再加上一个简单的MLP结构,最后Wide和Deep两部分共同对最后进行输出。
Wide&Deep Model可以很好地利用一些全局信息,在所有的路径和地理区域信息,但是无法很好的抓住一些局部特征,因此我们增加了另一部分网络结构来利用路段的局部信息,而这种信息又跟NLP中的序列结构很相似,所以我们用了LSTM。
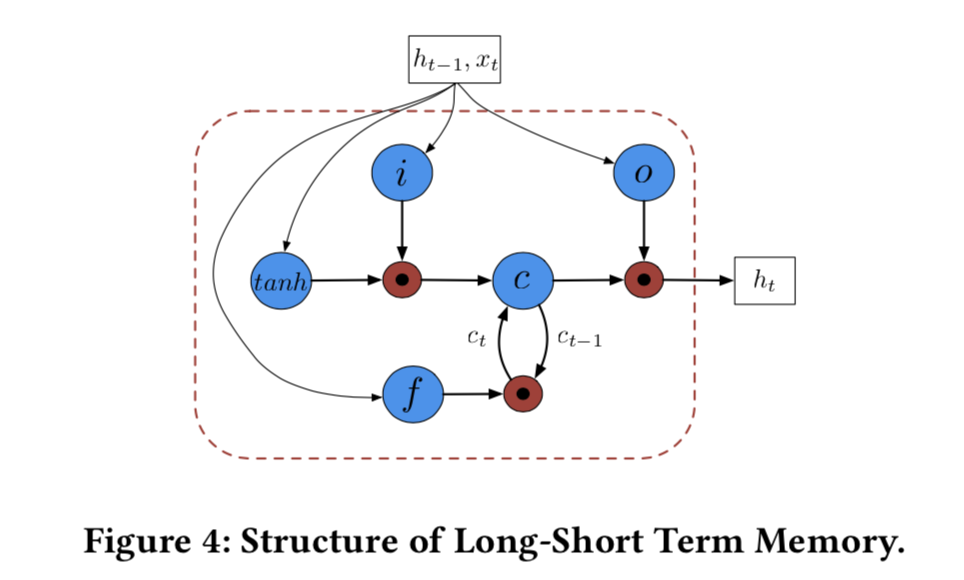
LSTM最早是用于解决梯度消失问题,它优势在于它的几个门结构,可以控制信息在一个节点内的流动,包括输入门、遗忘门、输出门: \[ \begin{aligned} i_t&=\sigma(W_i[x_t;h_{t-1}]+b_i)\\ f_t&=\sigma(W_f[x_t;h_{t-1}]+b_f)\\ o_t&=\sigma(W_o[x_t;h_{t-1}]+b_o)\\ g_t&=\tanh(W_g[x_t;h_{t-1}]+b_g)\\ \end{aligned} \] 其中记忆单元和隐藏状态的更新为: \[ \begin{aligned} c_t&=f_t\odot c_{t-1}+i_t\odot g_t\\ h_t&=o_t\odot tanh(c_t)\\ \end{aligned} \] 所以总体的模型结构如下图:
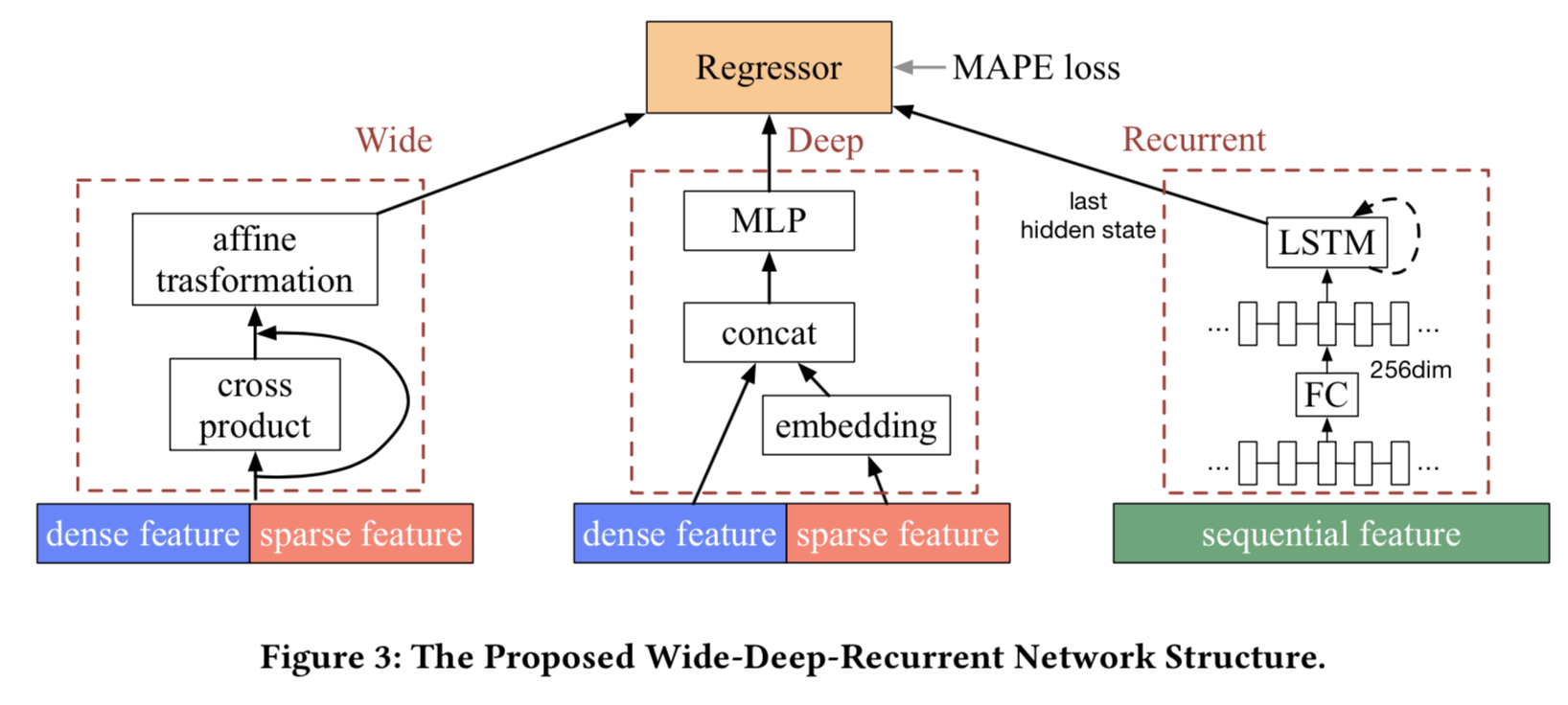
WDR模型主要分成三部分,wide部分最后传出256维的输出,deep部分做20维的embedding,然后经过一个3层的MLP,激活函数采用ReLU,输出256维向量,recurrent部分则是一个RNN结构的变形,每一段路径都做了256维的embedding,然后传入LSTM单元,最后的隐藏状态作为输出。
整体的工程结构如下图:
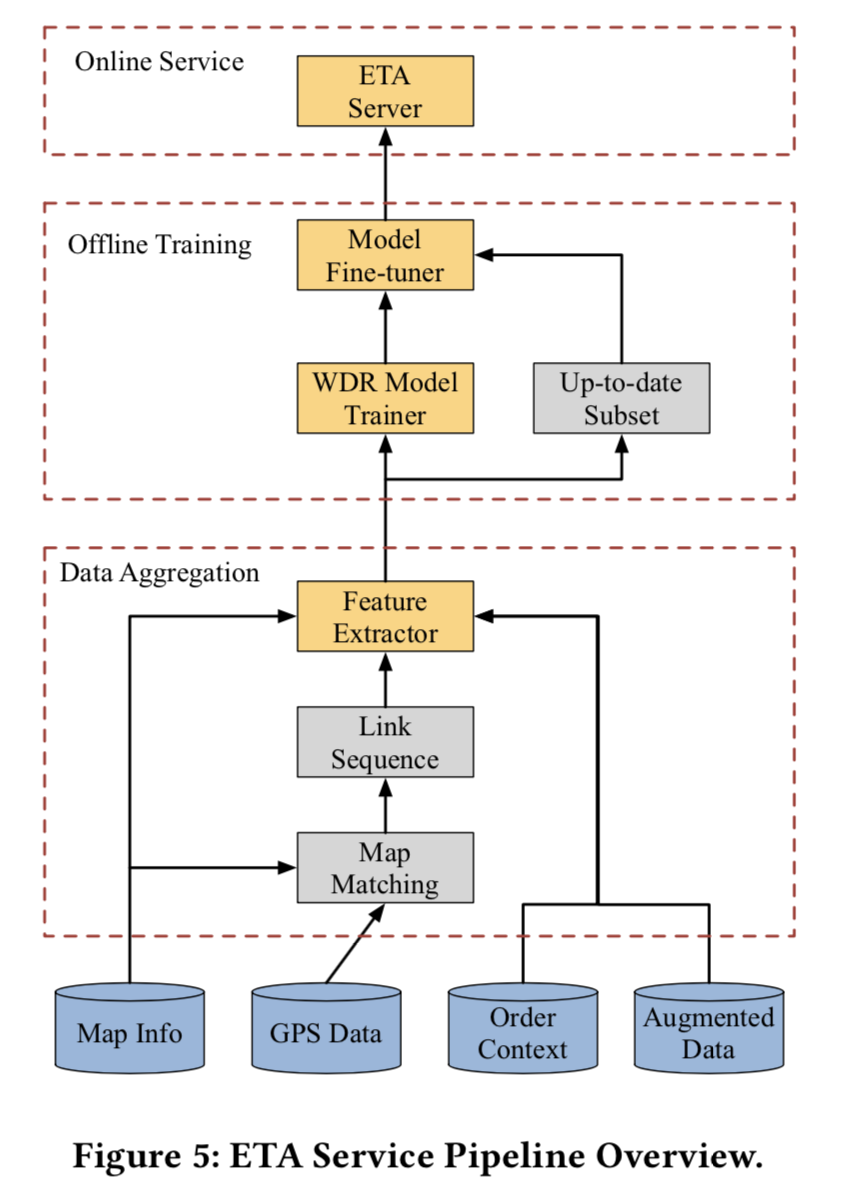
结语
此处不详细列举后面数据的处理和实验结果了,只写个前面的想法,总体来说亮眼的点比较少,中规中矩的工作,但是从实验到落地到上线,这部分东西还是很值得肯定的。建议大家也多关注一些工程上的点,毕竟落地了才能创造价值。