这篇文章是airbnb团队在KDD2019上的一篇文章。在当时来看,GBDT的模型已经对他们的业务有了一定的贡献,这篇文章主要是在讲,该团队在尝试使用NN模型来做进一步的迭代。相比于其他文章更关注于新的建模技巧,这篇文章描述的更多的是从树模型到NN模型这一路走来的心路历程,同时也希望给其他准备尝试NN的团队一些启示和建议。
看完这篇文章还是有很多感想的,会在结束的时候做一些讨论。
Introduction
最早一版实现的搜索排序是一个人工的打分函数,用GBDT替代人工打分函数使得业务有了airbnb有史以来最大的改善,同时也伴随着许多成功有效的迭代改进。本文讨论的模型主要是用于对用户预定概率进行建模,对于一个用户,他会进行多次的搜索、点击,一个成功的session以预定一个房间作为结束。在训练时候,模型可以从当前的日志中得到之前模型推荐的列表,来学习一个打分函数,将历史日志中最易被预定的房间排在尽可能靠前的位置。训练结束后,新模型将通过AB测试,和当前模型进行比较,观察转化率是否会有显著的提高。
注,airbnb的黑话:
- 房间=listing
Model Evolution
下图展示了我们主要离线指标NDCG的相对提升以及转化率的相对提升,其中被预约的房间的相关性为1,其他为0,x轴为不同时间上线的模型。
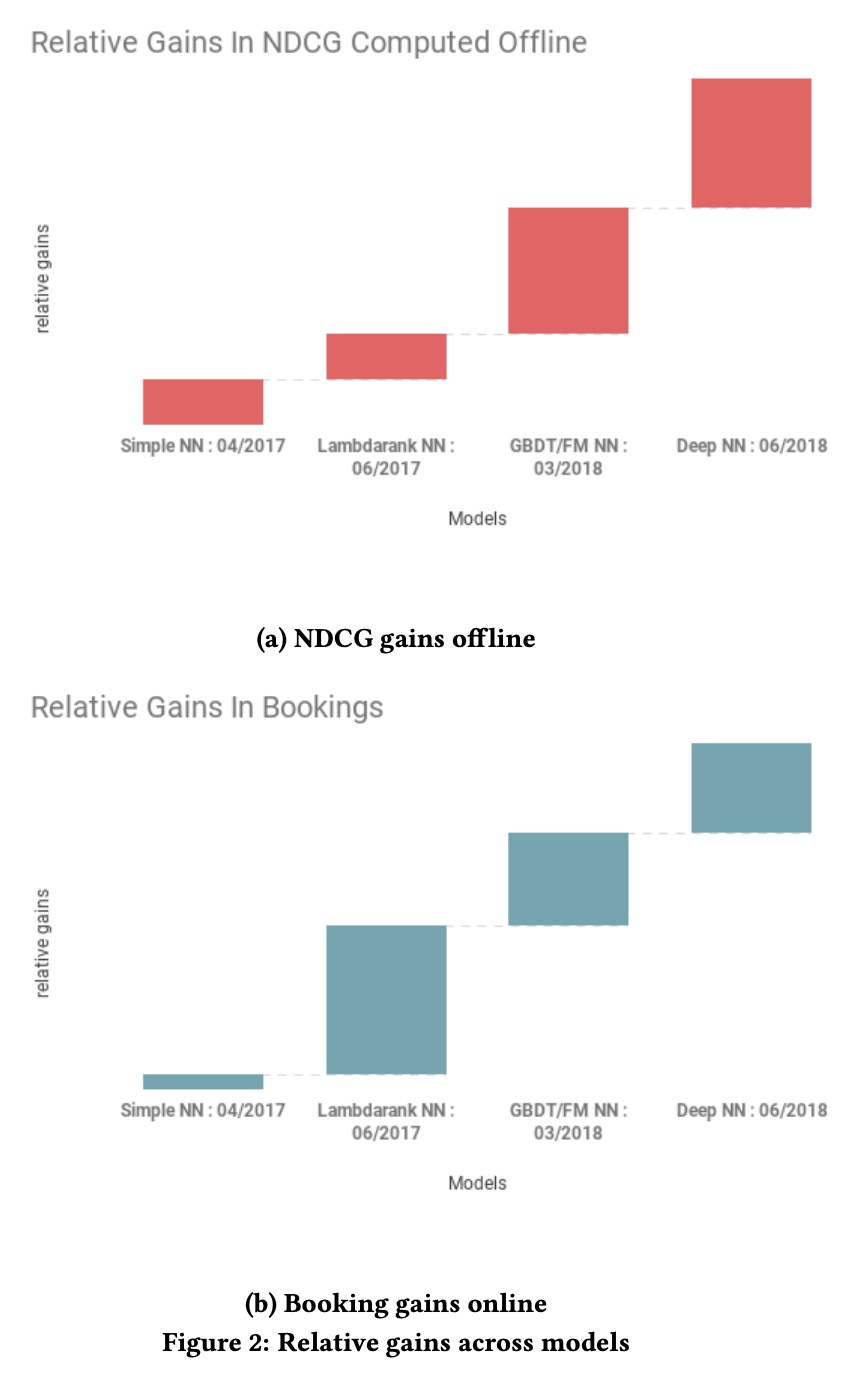
Simple NN
Andrej Karpathy对模型结构的建议:Don't be a hero. 即不要觉得模型结构很重要。然而这边不是我们开始,刚开始我们尝试了很多复杂结构,但是除了提高了复杂度,并没有什么结果。
最开始上线的网络结构是一个单层的NN,32个节点,激活函数选择ReLU,这个模型在效果上已经跟GBDT差不多了,采用跟GBDT完全相同的母豹函数以及特征。
这个模型的上线验证了NN pipeline是可以用于生产环境的,并且可以应对流量高峰。
Lambda Rank NN
在NN上线后我们第一个突破是将Lambda Rank的思想带入NN中,离线我们都采用NDCG作为评估指标,Lambda Rank可以让我们直接优化NDCG指标,我们在最简单的NN模型基础上做了两个改动:
- 采用pairwise的训练方式,构造<被预定房间,未被预定房间>的训练样本,在训练中最小化交叉熵,使得被预定房间的score高于未被预定的房间
- 根据对NDCG提升的不同,对pairwise的loss进行加权,更关注于列表中靠前位置的样本
Decision Tree / Factorization Machine NN
当NN作为rank的主力时候,我们也在对其他的模型进行调研:
- GBDT的迭代,包括构建样本的方式等等
- FM,通过将listing和query映射到32维的空间,预测给定query下的listing预定概率
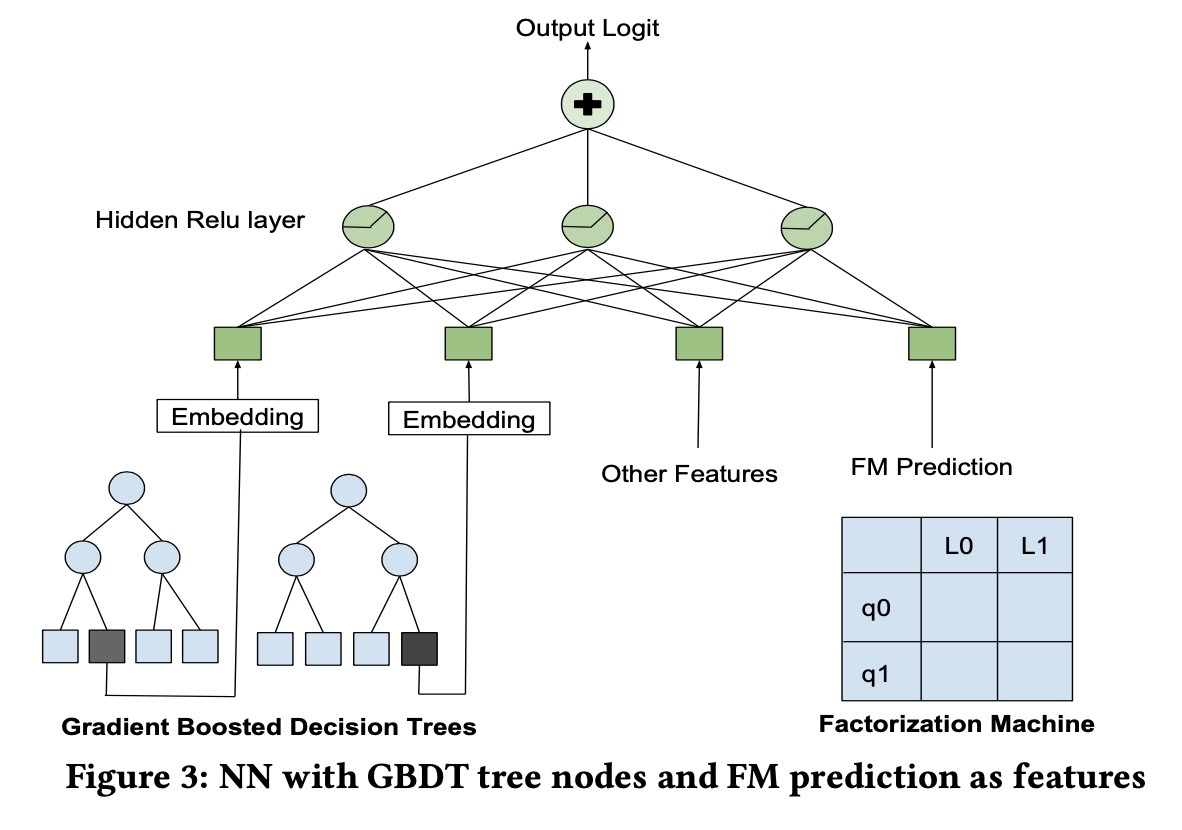
上述两个模型在测试集上和NN有差不多的效果,但是对于最后展示房间的排序却截然不同,所以我们尝试将三个模型结合起来,对于FM我们将最终的结果作为特征加入模型,对于GBDT我们将叶子结点作为类别特征加入模型:
Deep NN
迭代到这个时候,模型的复杂度已经开始有点高了,为了解决这些问题,我们将数据量扩大了十倍,然后将网络变成2层,此时我们的模型的输入有195维的特征(包含类别的embedding),第一层是127ReLU的全连接,第二层是87ReLU的全连接。
此时输入DNN模型的特征是房间的一些属性包括价格、便利设施、历史预定情况等等,经过简单的特征工程后加入模型,除了以下几个其他模型的输出作为特征:
- 由Smart Pricing产生的房间价格
- 该用户过去浏览的相似房间,通过共同浏览的embedding计算得到
这些模型并不是直接为排序服务,但可以为DNN提供额外的信息。
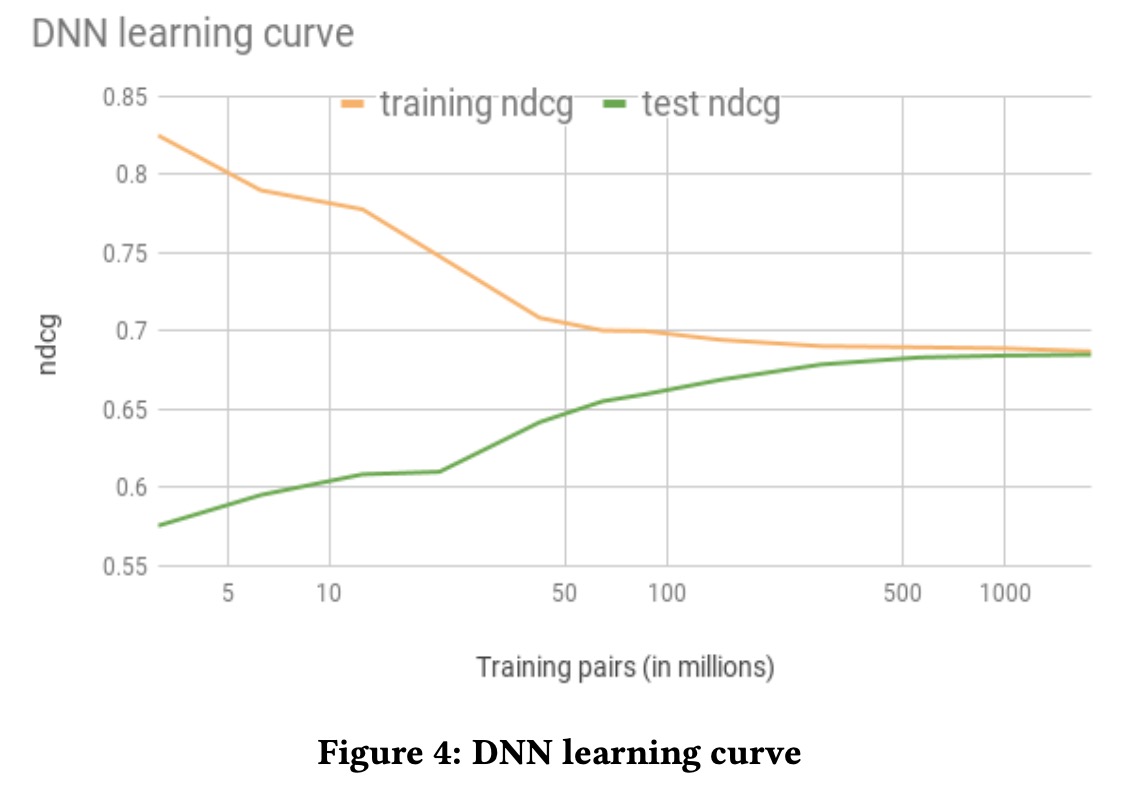
大概经过17亿pairs的训练后,我们能够把训练集和测试集的泛化gap降到最
FAILED MODELS
上面讲述的几步迭代并不是我们全部的经历,现实是残酷的,充斥着很多不成功的尝试,数量上远超过那些成功的尝试。此处我们列举几个有意思的例子,因为它们展示了有些方法在大部分场景上非常有效且流行,但是在我们的场景上并没有卵用。(读到这里疯狂打call,说出了我的心里话。)
Listing ID
Airbnb上的每个房间都拥有唯一的id,采用NN模型的一个潜在机会就是能够直接将这些id作为特征代入模型,即用id做embedding,这一做法在NLP和Youtube的推荐上都被验证是十分有效的。
然而在不同的尝试中,listing id往往会导致过拟合
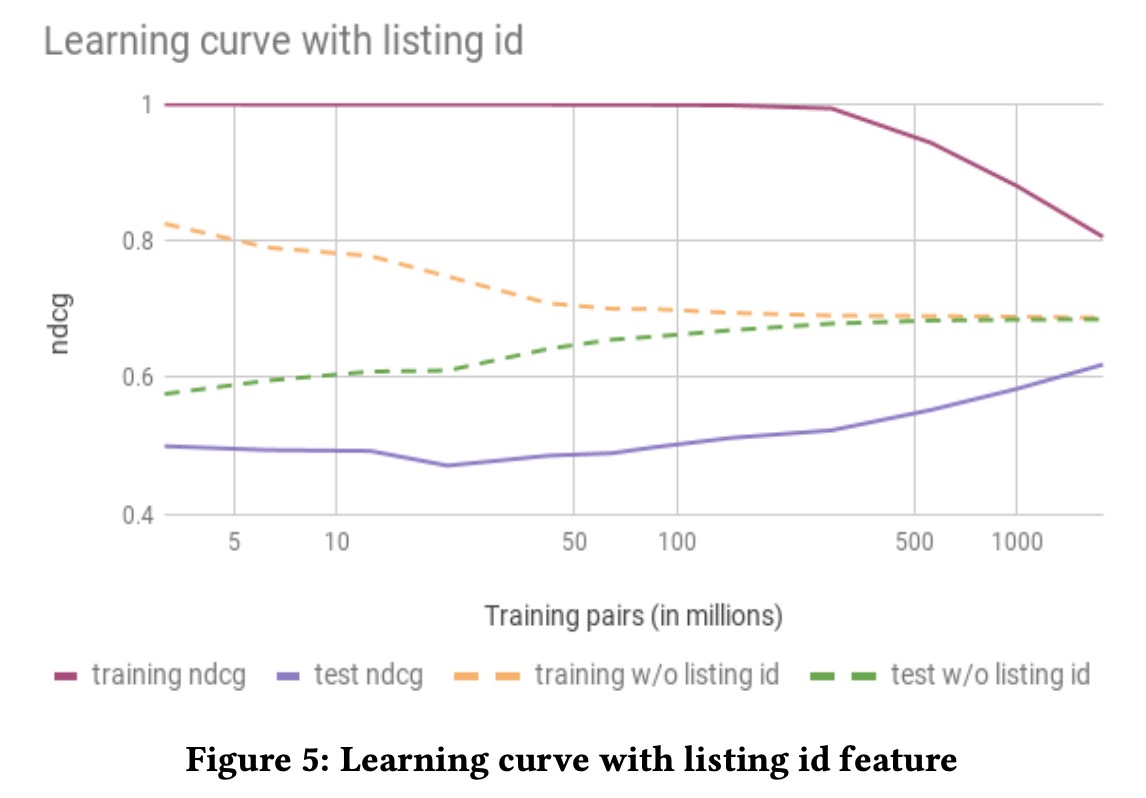
我们可以看到NDCG在训练集上非常好,却在测试集上表现很差。事后分析,用id构造embedding这一想法在我们的场景上失效是因为我们特殊的市场环境:embedding需要每个物品都拥有大量数据进行训练,来挖掘他们的价值,当这个物品可以被无限重复次使用的时候,比如线上视频或者语言中的词汇,并不存在用户与它们交互次数的限制,获取大量的训练数据就相对简单了。但是在我们的场景下,房间被预定这个行为是有物理限制的,一年最多被预定365次,这样每个房间的预定数据就非常稀疏,直接导致过拟合。
Multi-task Learning
因为预定这个行为是有物理限制的,但是浏览行为是没有限制的,进一步,我们又发现长时间浏览详情页和预定是有相关关系的。
为了解决listing id的过拟合问题,我们构建一个多任务的模型,分别用两个输出层来预测预定概率和长时间浏览的时长,同时通用底下的隐藏层,模型结构如下图所示:
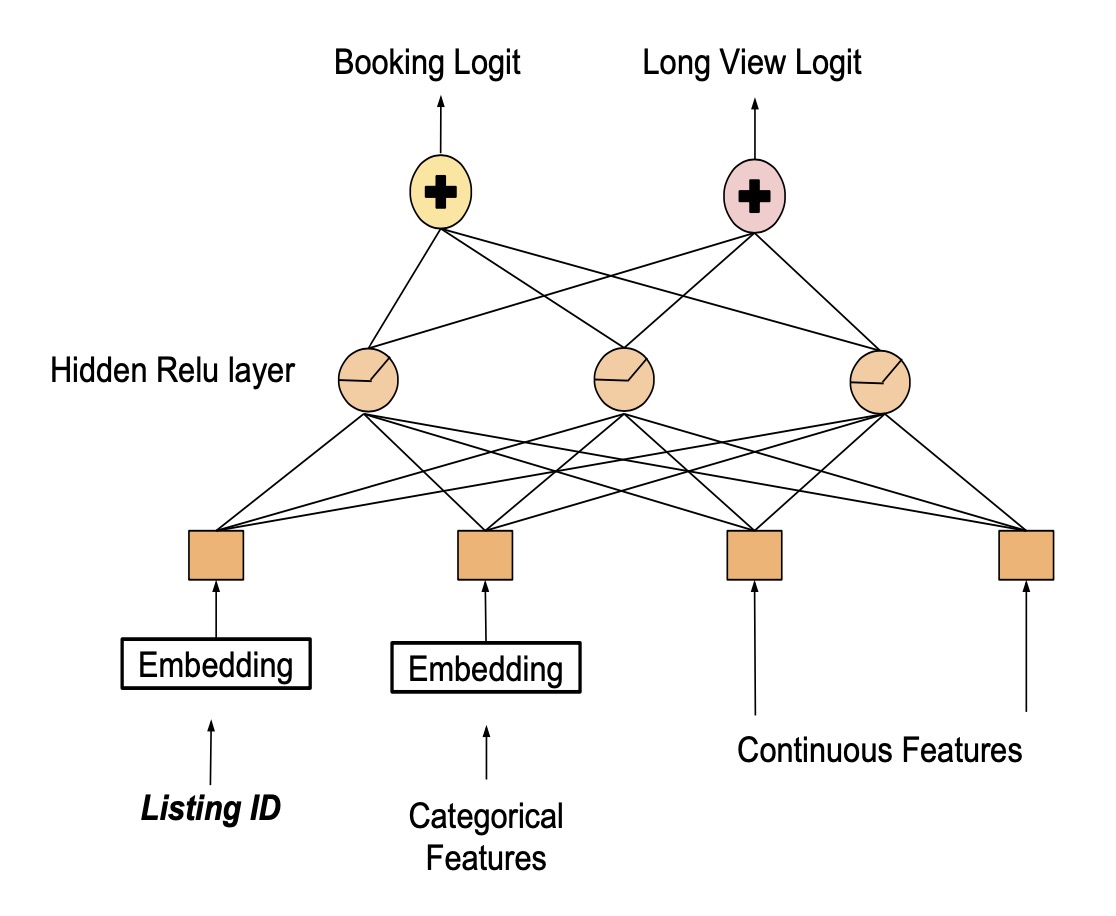
其中listing id的embedding可以共享,这个模型背后的想法是可以将长时间浏览的学习到的知识迁移到预定概率预测上,同时避免过拟合。
当线上测试的时候,模型对长时间浏览的预测有了一定进步,但是对于预定概率的预测却没什么差异。我们对数据进行检查,我们发现几个潜在的特性:
- 高端、高价的房间
- 拥有较多描述的房间
- 特殊的房间
以上这些特性都很难再模型中表达出来,同时这些也是airbnb这种场景中特有的。
Feature Engineering
基线GBDT Pipeline我们采用了很多特征工程,包括计算比率、滑动窗口的平均等等,这些都凝聚了很多历史经验。采用NN模型的一个大的好处在于它可以自动化构建特征,给模型喂入原始数据,然后通过隐藏层自动构建特征。
这一章会讲一些特征工程相关的事情,因为我们发现想让NN更高效也是需要一些对原始数据的处理,相比于做一些数学运算的传统特征工程,我们主要关注于使特征遵从特定的性质,使得NN模型能够更加有效的利用其中的信息。
Feature Normalization
在我们刚开始尝试训练NN模型时候,我们简单的将GBDT使用的全部特征喂进模型,这样做很糟糕,最终loss会比较难收敛,我们追踪这个问题发现是因为特征没有正确的标准化。
对于决策树,精确数值没有太多意义,相对的序关系更重要,NN对于数值类特征则会更加敏感。
超出常规范围的数值会造成过大的梯度,这对ReLU这样的激活函数会失去作用,为了避免这个问题,我们将所有特征限制到一个相对较小范围内,保证中位数为0:
- 对于正态分布的特征,采用\(\frac{\text{feature_val}-\mu}{\sigma}\)
- 对于长尾分布的特征,采用\(\log\big(\frac{1+\text{feature_val}}{1+\text{median}}\big)\)
Feature Distribution
除了将特征限制到较小的范围,我们还保证他们都拥有相对平滑的分布。这么做的原因有:
- 容易发现bug,当我们拥有数亿的样本时,边界检查一般是否有用但是作用有限,我们发现分布的平滑度(smoothness)是一个检查bug的利器,因为往往错误都会产生一个违反常态的分布
- 增强泛化,我们发现在我们的场景中,每一层的输出会逐渐把分布变得更加平滑,如下图所示,当我们用数百个特征建立一个模型的时候,特征的组合空间会非常大,在训练中只有部分特征的组合会被遍历到,来自lower layer的平滑的分布会使得upper layer在面对没有见过的取值时给出更加合理的结果,这也使得NN的泛化能力会更好。基于这个考虑,我们尽量保证输入特征有更平滑的分布
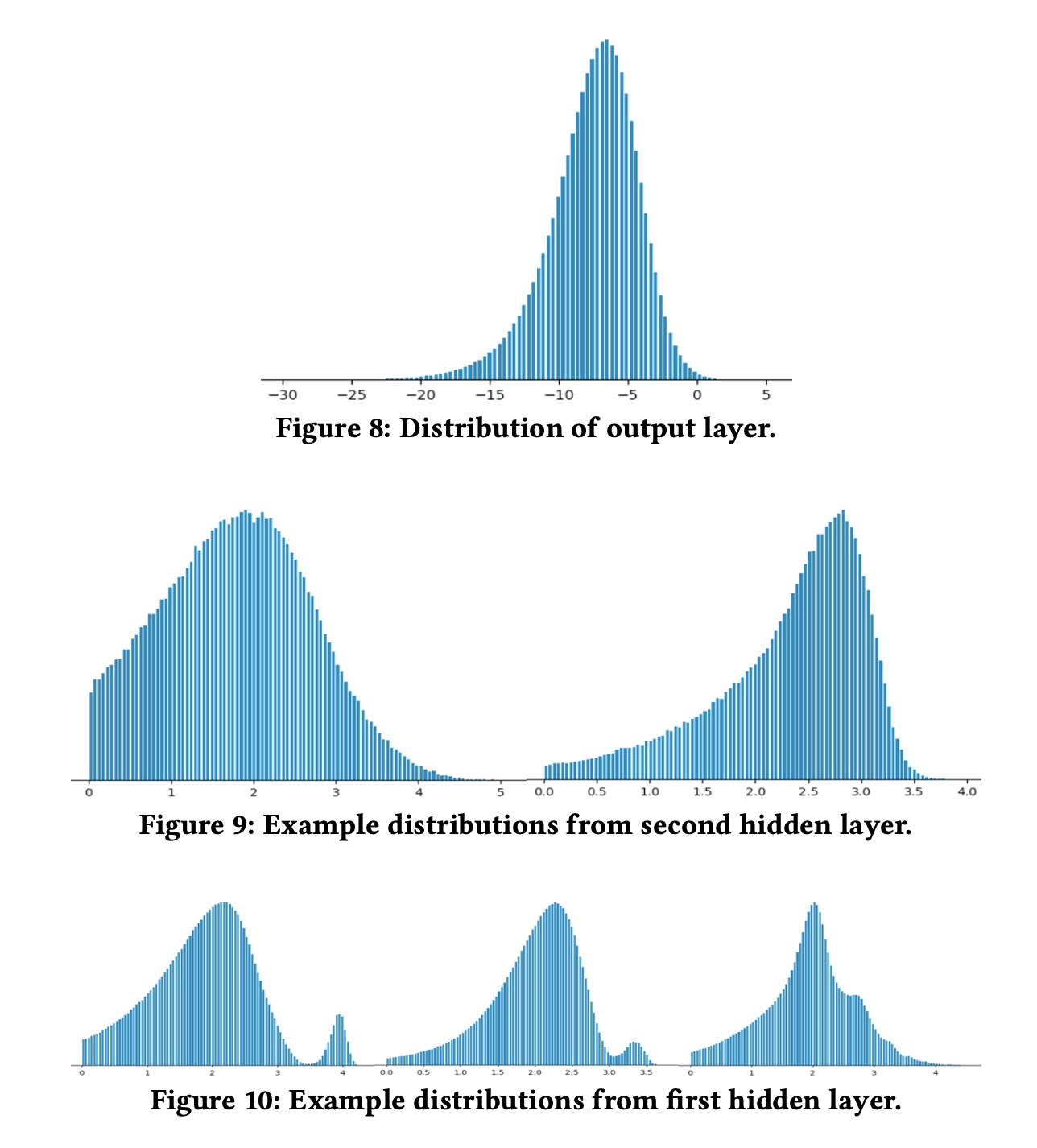
为了验证这个模型的泛化能力,作者姜特征值扩大任意倍数,然后观察最后NDCG指标,我们发现模型表现会相对平稳很多。大部分特征通过debug+标准化都会得到一个相对平滑的分布,然而对于一些特别的特征我们是需要一些特别的处理,比如说经纬度,原始经纬度分布如下图所示,我们通过计算其离展示给用户的地图中心的偏离值作为标准化,然后再取\(\log(\cdot)\),就会得到如下平滑的分布。
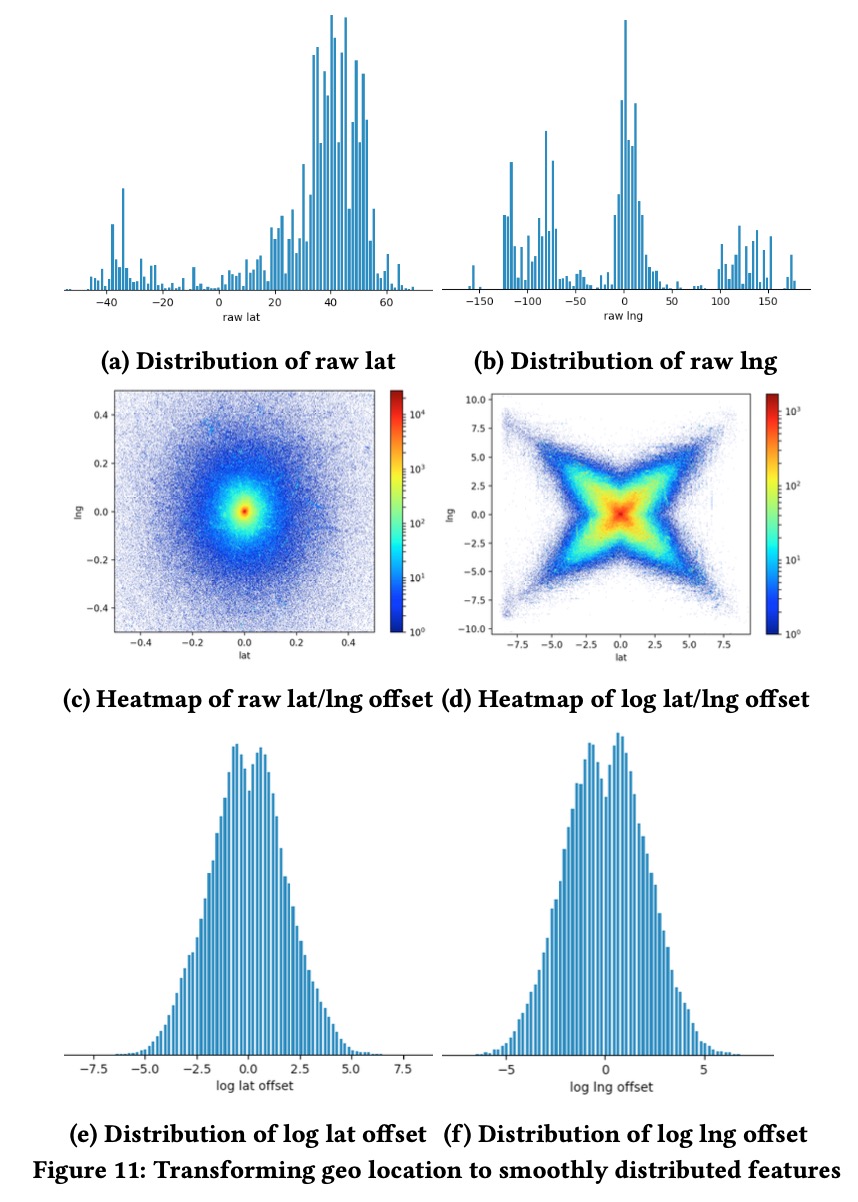
- 检查特征的完整性,通过观察特征分布,我们可以发现一些业务上的问题
High Cardinality Categorical Features
即类id特征。listing id并不是我们尝试的唯一的id类特征,我们还尝试了其他的并取得一定业务收益。用户的对于城市区域的偏好是一个比较重要的位置信息,对于GBDT,这些信息需要很多的工程准备。
NN模型可以轻易处理类id的特征,我们通过城市和s2的格子取hash构建一种新的类别特征,然后进行embeddidng,这样可以学习到位置的偏好信息。
System Engineering
工程Pipeline总结如下:
- 搜索query打到一个java服务器,然后进行检索和打分
- 服务器产生log,徐俩画的thrift实例
- 采用Spark pipeline来构建训练数据
- tensorflow训练模型
- scala和java的工具来做模型评估以及离线评估
- 模型通过java服务器加载
- 所有都在aws实例上运行
其中有若干优化点:
- Protobufs and Datasets,之前使用GBDT时候训练数据是csv,然后tensorflow通过feed_dict直接读,这样做主要时间卡点在读数据上,gpu利用率不高,后来将训练数据保存为protobufs,并且用dataset的api,读取数据快了17倍,能够使用的数据从一周变成一个月
- Refactoring static features,很多房间的特征都是很少改变的,但是会随着检索重复很多遍,为了降低磁盘的读写压力,把listing id作为类别特征,然后构建一个只读的embedding,直接读这些静态特征,相当于把特征换存在模型中
- Java NN库,做了一个tensorflow的适配java库
Hyperparameter
- 采用dropout来避免过拟合
- 初始化采用Xavier,不要用全0
- 学习率调整没太大意义,最后采用LazyAdamOptimizer
- Batch size,影响不是很明显
Feature Importance
NN模型的特征重要性一般是很难看出来的,我们做了几种尝试来做一些解释:
- 分数拆解,最开始我们尝试把分数拆解到对应的输入上,但是由于NN都是交叉的结构,这样做行不通
- Ablation Test,尝试每次把特征去掉一个,然后观察最后结果的不同,然后用结果指标变化量来作为特征重要性。但这样做会引入重训练带来的误差,同时由于特征之间有些相关性,模型可能也会从其他特征中学出来这些
- Permutation Test,对某个特征值进行随机的扰动,这样做同样假设了特征的独立性,在特征间存在某些相关性时并不可用。但是如果随机扰动某个特征并没有对最后结果产生影响,那么这个模型大概率也不会依赖这个特征
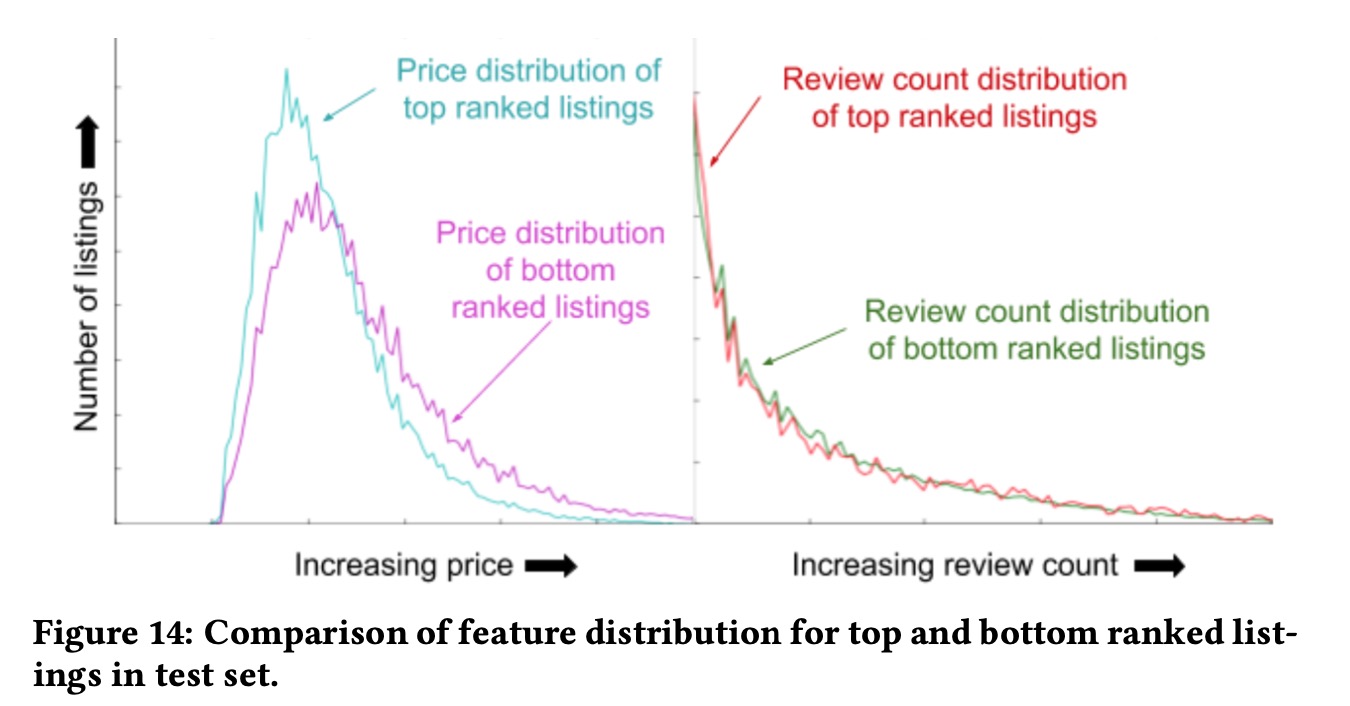
- TopBot Analysis,在测试集上,看不同score的房间,在特征分布上的差异(这个其实是一个日产工作中特别常用的手段,正向做法是看某一个特征上结果指标的分布差异,反向看就是不同score下,某个特征的差异)
Retrospective
上图展现了目前为止,我们整个DL旅程,从才开始被DL其他成功的例子所激励,我们处于乐观之巅,开始考虑用DL全面替代GBDT,并且期待DL能带来惊人的提升。在一些初步尝试之后,我们保持所有东西不变然后看是否能用NN替代当前的模型,因为没有太多的提升,这使得我们走入了失望之谷。经过一段时间,我们意识到使用DL并不是一蹴而就的,而是不断改进、尝试、思考而来的。对于小规模的数据集,采用GBDT的确是一个非常容易且正确的选择,我们也会在中等的问题上继续使用这样的模型。
所以还要不要推荐别人使用DL呢?答案是Yes,这不仅是因为它能够带来很高的线上业务的提升,也是因为它改变了我们的前进路线,早起我们更关注于特征工程,在采用DL之后,使得我们有精力可以从一个更高层级来看待整个问题,比如是否需要改进我们的优化目标,模型是否能代表所有用户等等,这两年采用NN来做搜索排序,我们只是一个开始。
这篇文章到这里就结束了,我对于这篇文章真的是十分喜欢,感觉就像自己亲身经历一样,目前手头的工作也是被卡在了某个以ensemble tree为主的工作上,去年团队也有很多关于NN(也包含其他一些模型)的尝试,但都是因为过于关注模型的“外在”(稀奇古怪的结构、魔改的loss等等),而忽视了模型的“内在”驱动(模型面对的问题是什么,采用什么样的技术去解决),这导致团队之前的工作都显得有些“浮于表面”,甚至也导致我有了一种“NN并不适合我们这个业务场景”的错觉,我们常常抱怨某某顶会文章复现完了不work,华而不实,其实只是我们在面对自己的“症状”时,吃错了“药”,同时对于自己症状也没有十分详尽的去分析这个病因到底是什么,一顿生搬硬套,看似尝试了很多,却只是无用功。
希望在以后的工作中,真的能一步一个脚印,做一些solid的事情,同时不轻信也不急于否定DL,要做“内在”驱动的事情,多关注于为什么做,在迭代中去找到背后原因(某某任老板以前常说要透过本质去找背后原因,现在看来还是理解不够深T_T),多思考多质疑,业务出发,技术驱动,愿与诸位共勉。