TL;DR
LinkedIn发表在KDD2020上的文章,主要想解决在信息流中,如何将自然推荐物品和广告进行混排的问题,文中将该问题建模为带约束的优化问题,并提出了一种归并排序的方式。
目前这种方法及其衍生版本、简化版本,在日常工作中都非常常见,基本可以作为自然推荐和广告混排问题的baseline solution了。
摘要
Social networks and content publishing platforms have newsfeed applications, which show both organic content to drive engagement, and ads to drive revenue. This paper focuses on the problem of ads allocation in a newsfeed to achieve an optimal balance of revenue and engagement. To the best of our knowledge, we are the first to report practical solutions to this business-critical and popular problem in industry.
The paper describes how large-scale recommender system like feed ranking works, and why it is useful to consider ads allocation as a post-operation once the ranking of organic items and (separately) the ranking of ads are done. A set of computationally lightweight algorithms are proposed based on various sets of assumptions in the context of ads on the LinkedIn newsfeed. Through both offline simulation and online A/B tests, benefits of the proposed solutions are demonstrated. The best performing algorithm is currently fully deployed on the LinkedIn newsfeed and is serving all live traffic.
社交网络平台和内容平台都有信息流的产品,其中既有能够促进用户参与停留的自然推荐的内容,也有为平台贡献收益的广告内容。本文重点讨论了在信息流中广告分配问题,以实现收入和参与度的最佳平衡。据我们所知,对于这个显著影响业务收益且广泛存在的问题,本文首次提出了一种实际可用的解决方案。
本文描述了信息流排序这种大型的推荐系统是如何工作的,并且解释了在自然推荐物品和广告物品各自排序后将广告分配视作一种后处理操作,这个方案为什么是用的。在LinkedIn的信息流产品上,基于多种假设提出了一套轻量级的算法,并通过离线模拟和在线AB测试,证明了所提出的方案是有正向效果的。目前表现最好的算法已经被部署并在LinkedIn的信息流产品上全量使用。
问题背景
信息流推荐是一种常见的产品,为用户展示一些与其相关的内容,包括朋友以及关注用户的博文更新、公司的新闻、社团的活动或是工作的招聘信息。我们将创作者不需要付费就可以展示内容称为自然内容(organic content,下文中称自然推荐物品)。因为更感兴趣,用户会更原因浏览这些内容,进而在平台上有更高的参与度(engagement,也可以理解为平台上停留意愿)。
同时,商业化也是大部分社交网络平台需要重点考虑的事情之一,常见做法是将广告插入自然推荐中。这些广告可以帮助广告主触达其目标用户进而获得更高利润,同时也能帮助平台获得商业收益的回报。目前只有很少的工作在研究应该在页面头部插入多少搜索广告。
据我们所知,目前还没有人研究如何确定信息流推荐中广告的位置,以及现实应用场景中的有效性。这个问题相比搜索广告更加复杂,因为推荐广告可以插入在任意位置。同时,社交网络平台风靡全球,在其信息流推荐中如何实现商业化是非常重要的问题,这也是我们这个工作所关注的。
自然推荐主要目标是最大化用户参与度,如各种用户的行为,广告则是通过竞价排序最大化期望收益。这两类物品的效用以及目标不同,导致了当前推荐排序系统往往是两层结构:相互独立的排序子路和多路召回(此处指不同类型的推荐召回)合并的混排。
混排的多路召回的子路往往有不同的目标,广告很难会比自然推荐带来更高的参与度,如何分配信息流中的曝光来平衡参与度与收益,正是我们想要解决的问题。一个常用的简单方案是采用定坑,在确定的坑位中透出广告商品。毫无疑问,定坑的方式是有损效率的,下图是一个case。
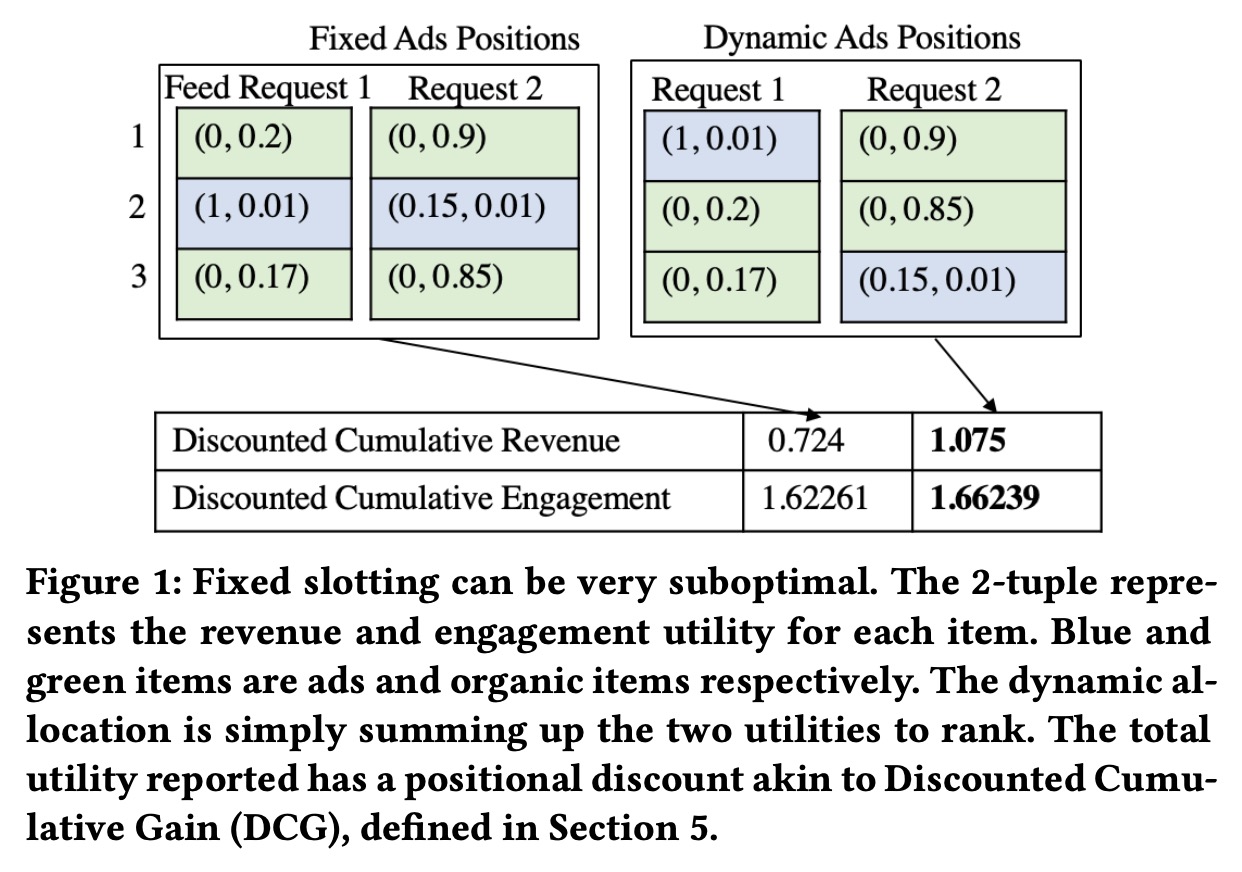
在混排中,如果想将不同目标的子路召回排序进行合并,就需要效用间的转化系数,某些情况下,可以直接采用商业价值进行折算,比如一个点击等同于1美元。我们也考虑了另外的方式,约束优化问题建模,这种方式并不直接给出一个转化系数,而是通过限定效用量来进行分配,得到最优解时的对偶变量即转化系数。
解决方案
常见的系统架构如下

其中自然推荐排序一般以用户活跃度优化为目标,广告排序一般以收入为目标,在CPC模式中一般采用\(\text{bid}\times\text{pCTR}\)进行排序,二价排序竞价扣费。混排层作为最后的重排,一般要求:
- 低延迟,子路的排序往往是耗时的大头
- 子路保序,即不改变推荐子路或者广告子路的序,除了效率因素外,广告一般采用GSP竞价,改变序之后会改变扣费
- 建模速度,因为推荐和广告往往是分不同团队在迭代,所以需要设计成两阶段的排序,同时系统需要自适应不同子路模型的迭代,自动调整混排中的参数
为了保护用户的体验,避免广告扎堆出现,需要设置一些规则。文中提出了top slot和min gap两个规则,top slot指第几个坑位之后才能出广告,min gap指出广告之后,至少需要间隔多少个自然推荐物品。
同时我们希望混排层还具备:
- 对于季节性自适应,广告需求往往有季节或者年的周期性变化,混排应该根据收益的系统性变化来调整广告的曝光量
- 动态广告位置,如果广告只在固定的位置出现,用户可能会有意回避,造成收益的损失。
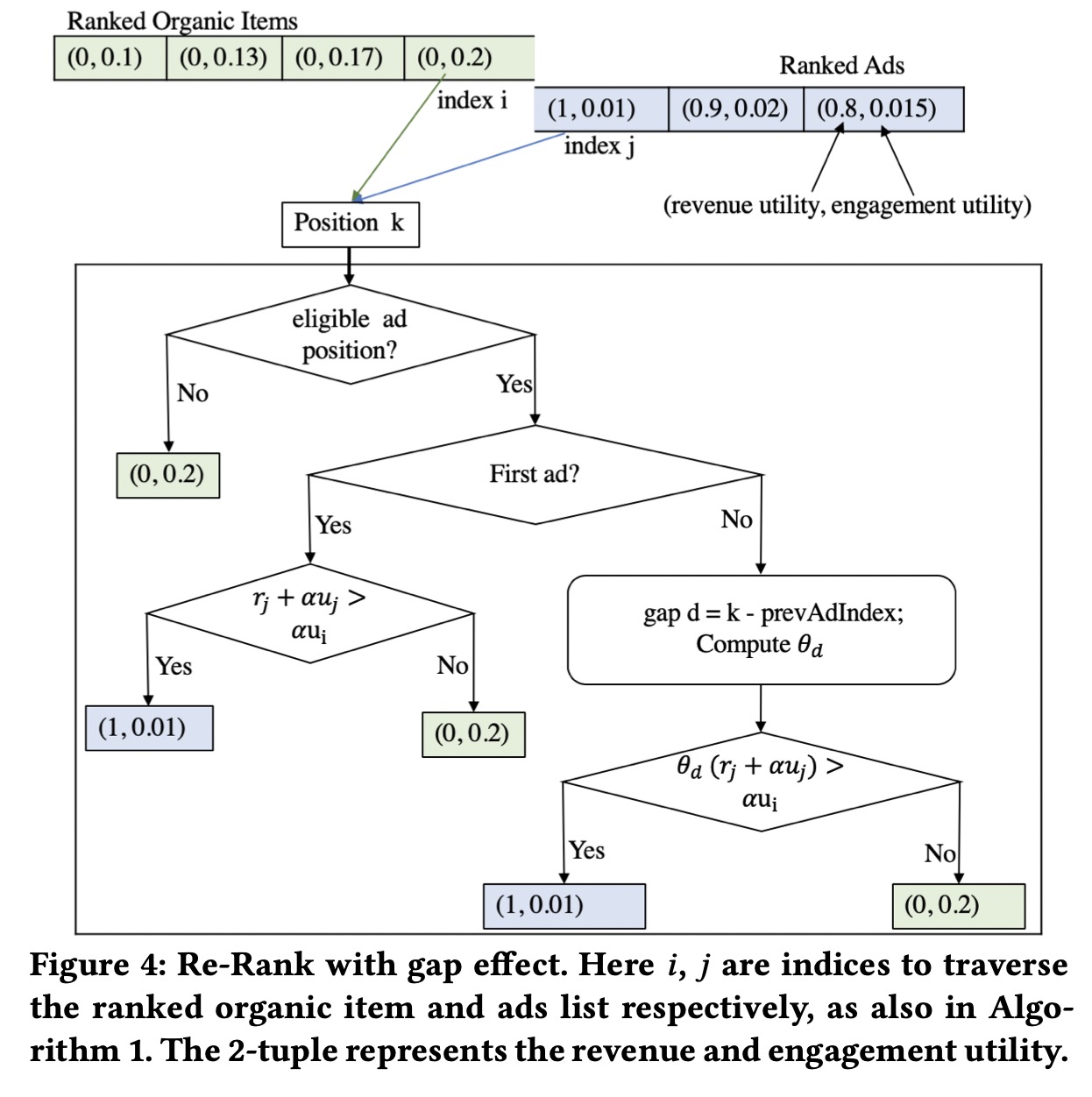
曝光的下标为\(i\),请求的下标为\(j\),自然推荐物品的期望参与效用\(u_i^o\),广告的期望参与效用\(u_i^a\)(此处的效用可以理解为点击物品),广告期望收益效用\(r_i^a\),自然推荐物品的期望收益效用为\(r_i^o=0\)。对于共\(\mathcal{J}\)请求,每次请求\(j\)都有\(N_j^o\)个自然推荐候选和\(N_j^a\)个广告候选,\(N_j=N_j^o+N_j^a\)。自然推荐子路根据\(\bf{u}^o\)进行排序,广告子路根据\(\bf{r}^a\)进行排序,对于每个曝光坑位\(i\),\(x_i\)表示是否放置广告,问题定义为 \[ \begin{aligned} \max && \sum_i x_i r_i -\frac{w}{2}\|{\bf{x}}\|^2 \\ \text{s.t.} && \sum_i x_i u_i^a +(1-x_i)u_i^o \geq C \\ && 0\leq x_i \leq 1, \forall i\in\mathcal{I} \end{aligned} \] 在全部参与大于等于某个常量基础下,最大化总体收益,目标函数中的二次项是为了保证整个问题的凸性。使用拉格朗日对偶,最优解为 \[ x_i=\begin{cases} 1, && \text{if} \quad r_i^a +\alpha u_i^a - \alpha u_i^o > 0 \\ 0, && \text{otherwise} \end{cases} \] 其中参数\(\alpha\)即最优的拉格朗日对偶变量。整个排序算法如下

整体逻辑是,自然推荐和广告进行归并排序,根据公式确定\(x_i\)取值,即对应坑位出广告还是自然推荐商品。
获取影子价格系数\(\alpha\)一般有三种方式:
- 给定\(C\)后,用历史数据求解出最优解
- 在线AB测试选出合适的系数
- 离线回放仿真,后文会解释。
在信息流排序中,往往会存在位置的偏差,顶部的商品更容易被点击。常见的解决方法是将位置信息作为特征加入模型训练,并且在线上推断时采用一个默认值。此处我们假设位置偏差对于自然推荐和广告无异质性,同时满足非递增。
对于出广告的间隔(Gap),由于位置偏差存在,很难直接估计。我们做了若干随机试验后,做了如下统计,其中\(d=k'-k\),即在\(k\)和\(k'\)位置出广告
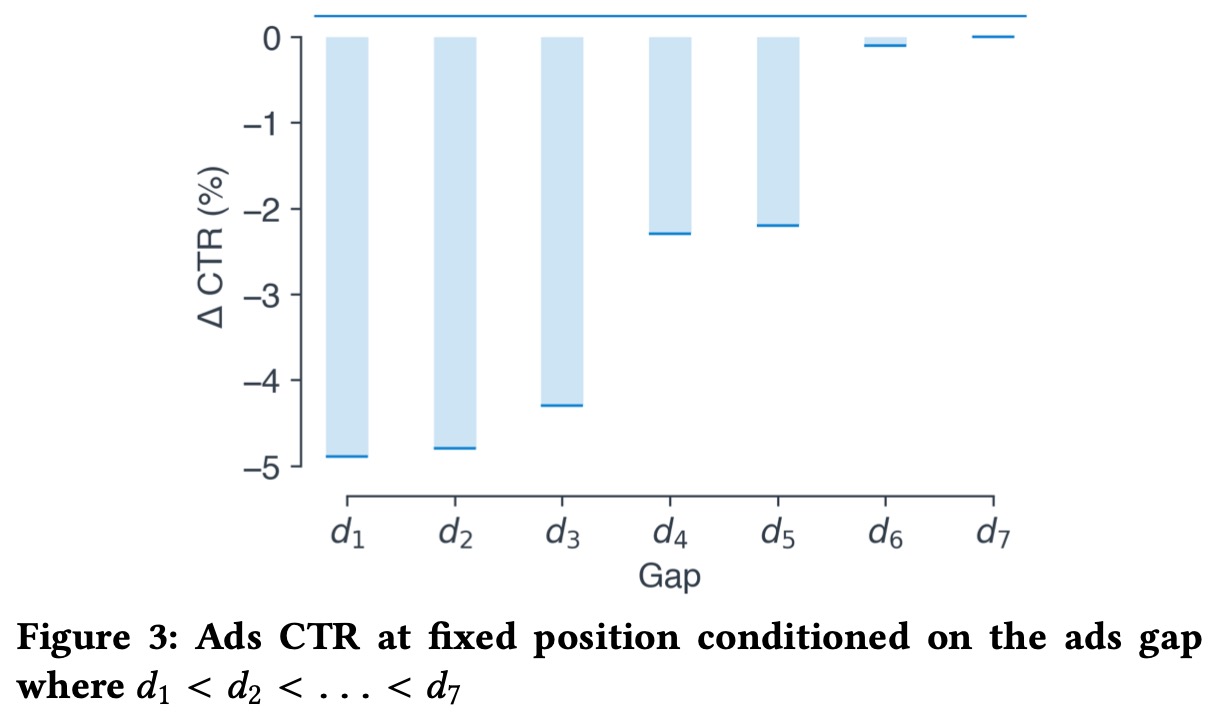
广告的CTR在比较小的gap下降低较多,但是对于自然推荐,并没有这个现象。所以在广告中我们采用与位置偏差相同的方式考虑gap的影响。
广告的CTR模型为 \[ g\big(\mathbb{E}[y_{iu}]\big)={\bf{a}}_{iu}^\intercal {\bf{z}}_{iu} + {\bf{b}}_i^\intercal {\bf{v}}_i \] 其中\(g(y)\)是概率的logit,\({\bf{a}}_{iu}\)是用户和商品的所有特征,\({\bf{b}}_i\)是物品相关的ID特征。我们在此基础上增加gap特征\(d\) \[ g\big(\mathbb{E}[y_{iu|d}]\big)={\bf{a}}_{iu}^\intercal {\bf{z}}_{iu} + {\bf{b}}_i^\intercal {\bf{v}}_i +\beta d \] 那么间隔的影响为 \[ \begin{aligned} g\big(\mathbb{E}[y_{iu|d}]\big)&= \frac{1}{ 1+\exp\big(-g(y_{iu|d})\big) } \\ &=\frac{1}{ 1+\exp\big(-g(y_{iu})\big) }\theta_d \\ \theta_d&=\frac{1+\exp\big(-g(y_{iu})\big)}{1+\exp\big(-g(y_{iu|d})\big)} \\ &\approx \frac{\exp\big(-g(y_{iu})\big)}{\exp\big(-g(y_{iu|d})\big)} \\ &=\exp(\beta d) \end{aligned} \] 间隔\(d\)下,广告的混排打分为\(\text{score}(i|d)=\theta_d (r_i+\alpha u_i^a)\),同时自然打分不变。
一个很自然的想法是做个性化的间隔效应估计,\(\theta_{ud}=\exp({\bf{c}}_{ud}^\intercal {\bf{\beta}}_{ud})\),但这种做法会增加计算时间,需要增加广告数量*位置数量次的计算。
实验分析
离线评估,定义折扣累计收益\(\text{score}(R)=\sum_j\sum_k w_k r_{k,j}\),折扣累积参与度\(\text{score}(E)=\sum_j\sum_k w_k u_{k,j}\),其中位置权重为\(w_k=\frac{1}{\log_2(k+1)}\),通过调整\(\alpha\),我们可以得到帕累托最优的等效面。
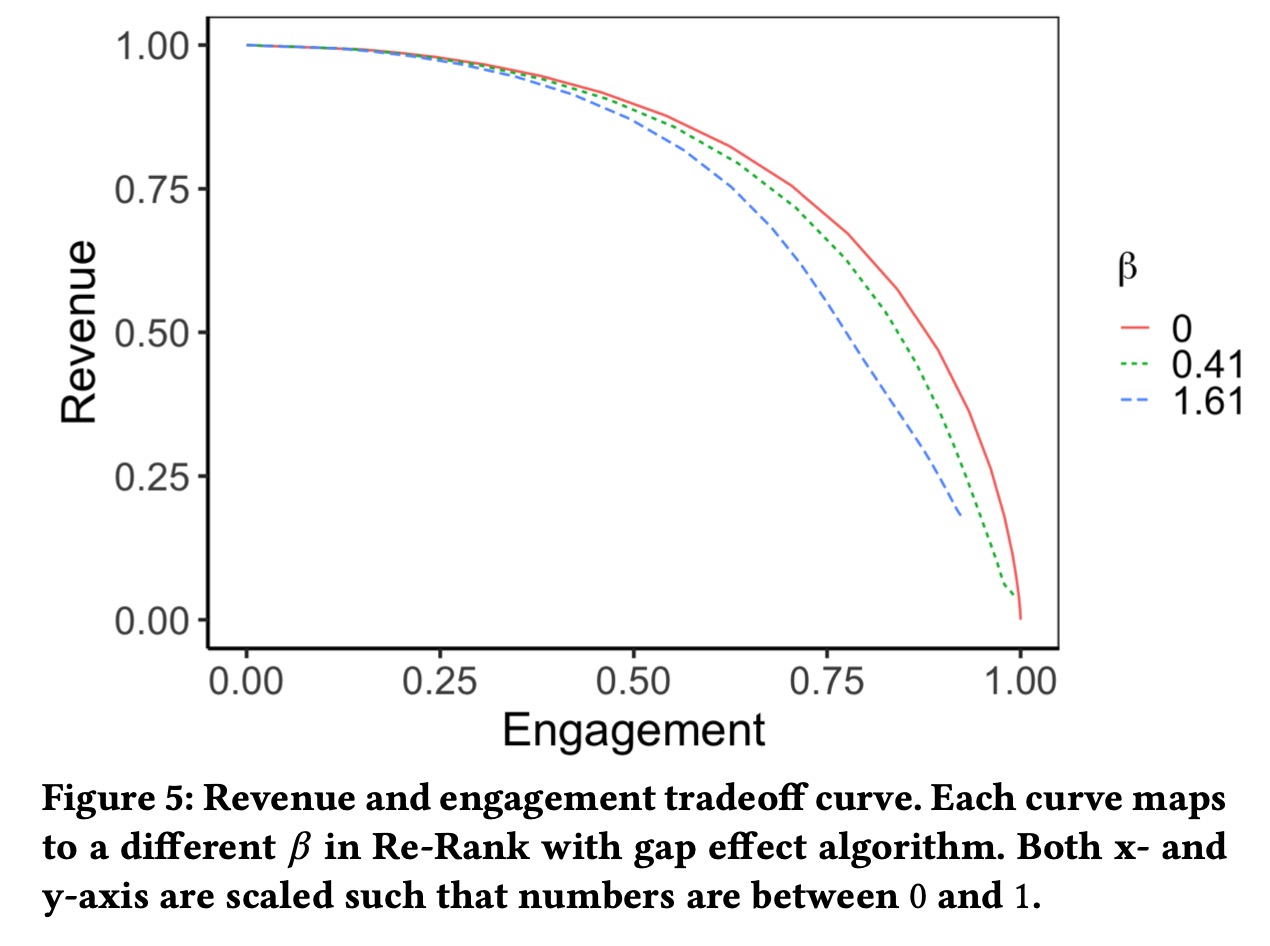
我们发现gap为0时候,效果最好,这是因为在原有评估指标中,并没有考虑到gap的影响,假设不同位置间独立,所以我们采用考虑gap影响的折扣累积收益 \[ \text{score}(R)=\sum_j\sum_k \frac{r_{k,j}}{\log_2(k+1)}\log_{10}(d+c) \] \(log_{10}(d+c)\)是根据随机实验中评估的折损效率进行拟合。
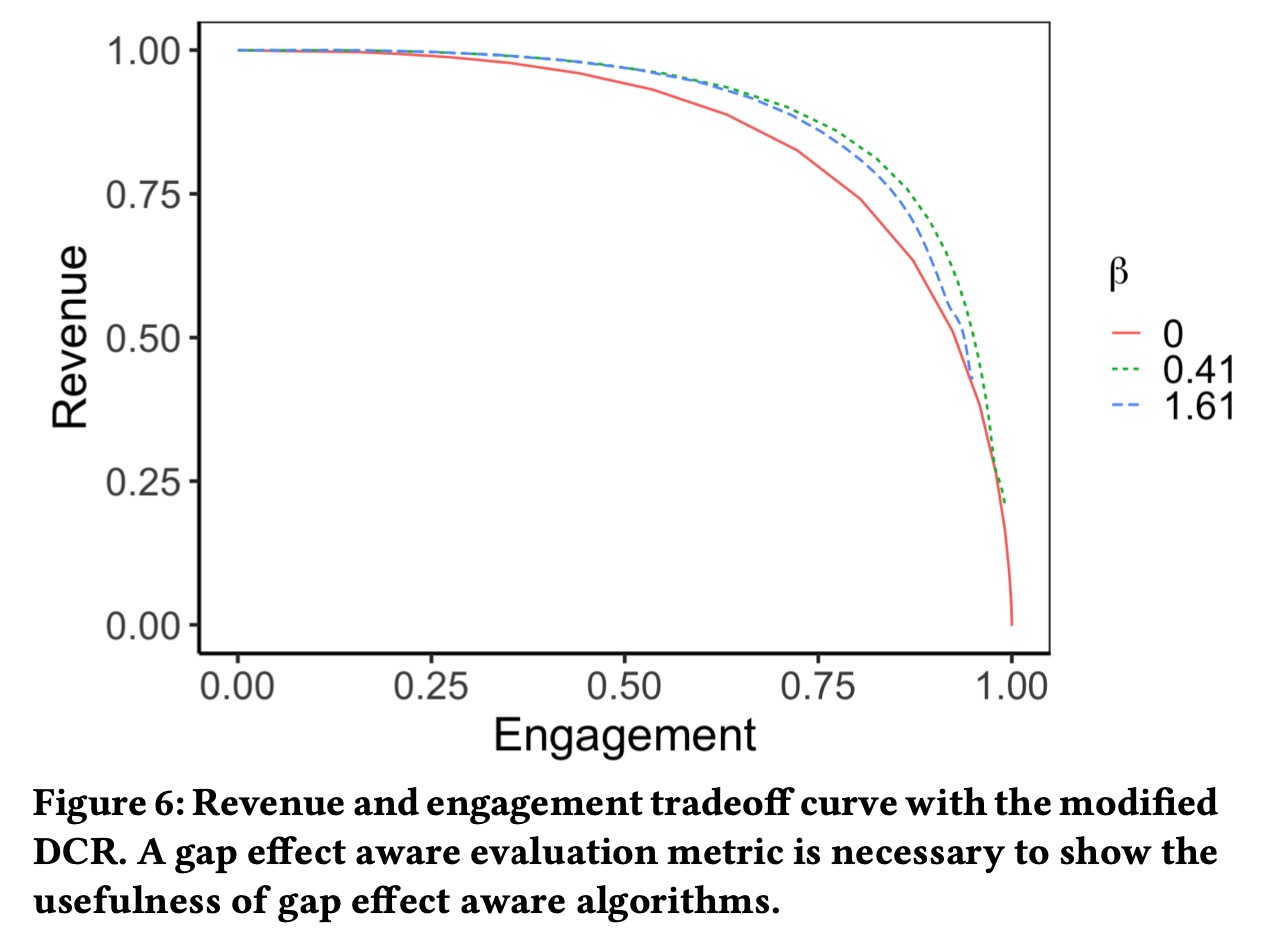
在线评估如下图所示,相比不考虑Gap效应时,相同\(\beta\)和不同\(\alpha\)下,收益和参与度都有不同程度的提升
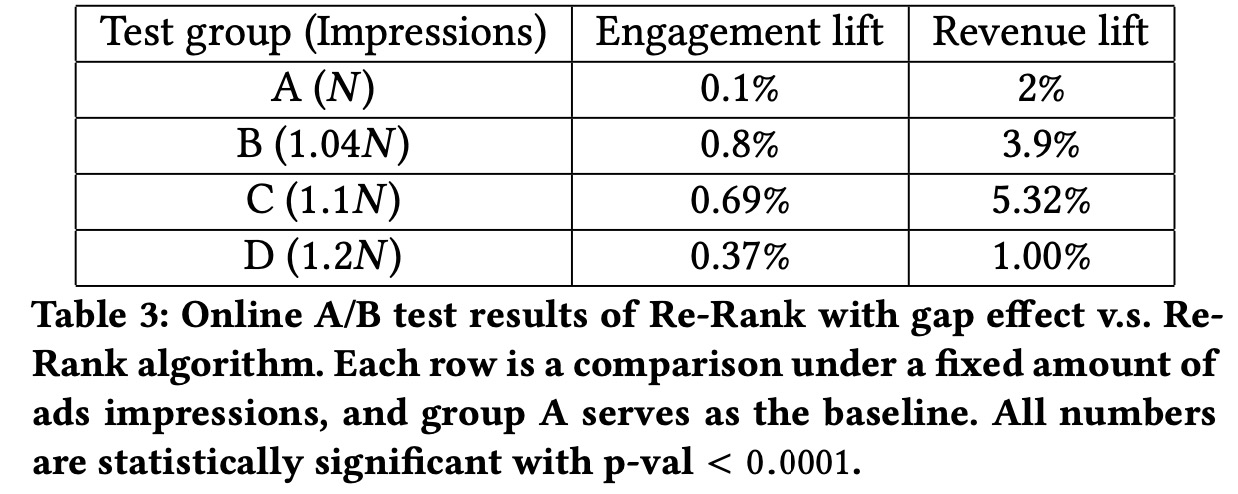
与此同时,在考虑Gap效应的混排中,广告会被放在更多不同的位置上,有70%的用户被施加了超过一种的Gap,旧算法只有40%,所以可以降低用户的“无视广告习惯”的影响
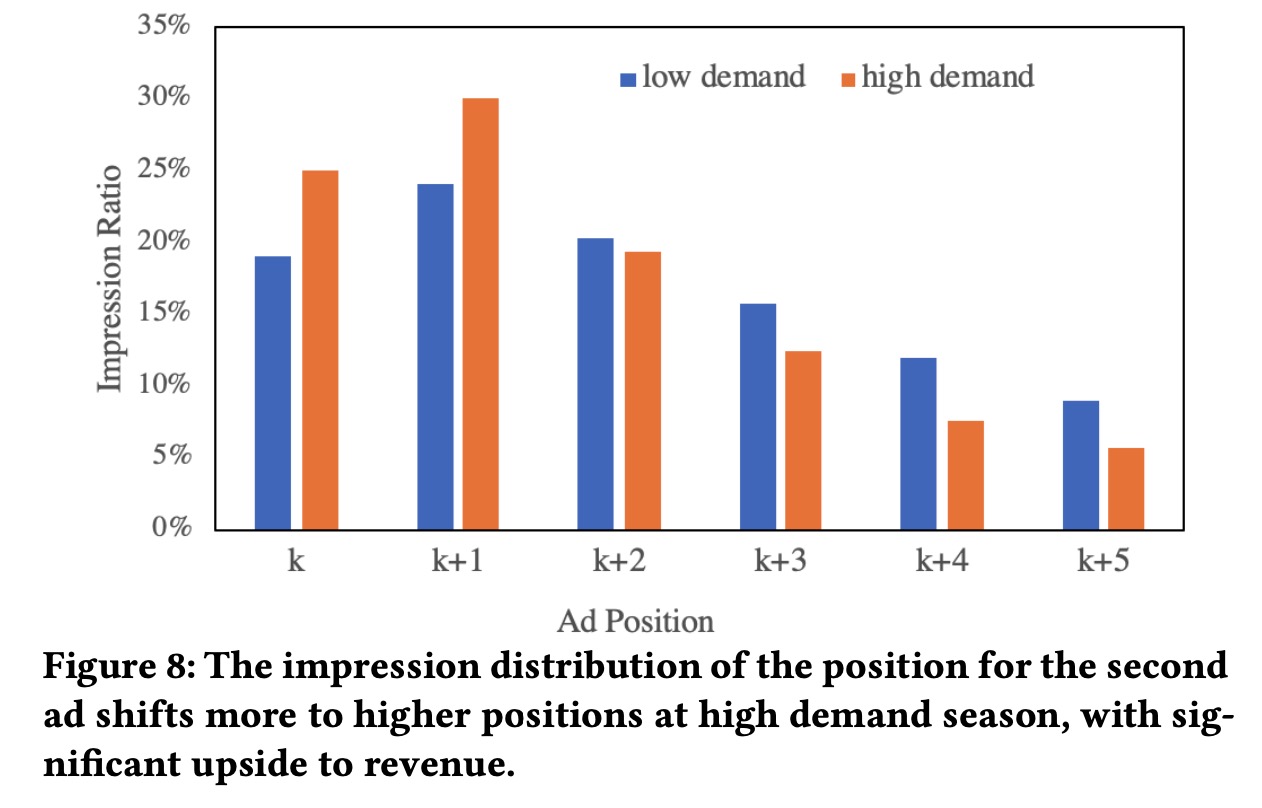
在广告系统中,广告需求存在周期性,较高需求时,收益的期望会更高,需求较低时,收益的追求降低,如下图所示,广告需求少时,整体排序位置会更靠后,广告需求多时,广告排序位置会更靠前。
因为自然推荐和广告是由不同的系统产出,所以各种排序分数需要可比,所以对其分别进行校准。对于点估计采用保序回归进行校准,对于多个点估计相乘的情况,采用Thompson采样来寻找全局的校准因子。
总结
本文是少有的写混排的文章,思路比较简单,以收益为目标,降低流量效率作为损失,进行归并混排。本文的一个亮点是对于广告商品间隔影响的考虑,这个在部分混排场景中并不常见,比如电商端内推荐广告就不存在这个问题,与之类似的问题是打散窗口的设计(比如一屏幕6个商品不能有同类目的)。除此之外,文章对于实践指导意义比较强,写了很多能落地的东西,这也是LinkedIn文章一贯的特点,非常务实。